
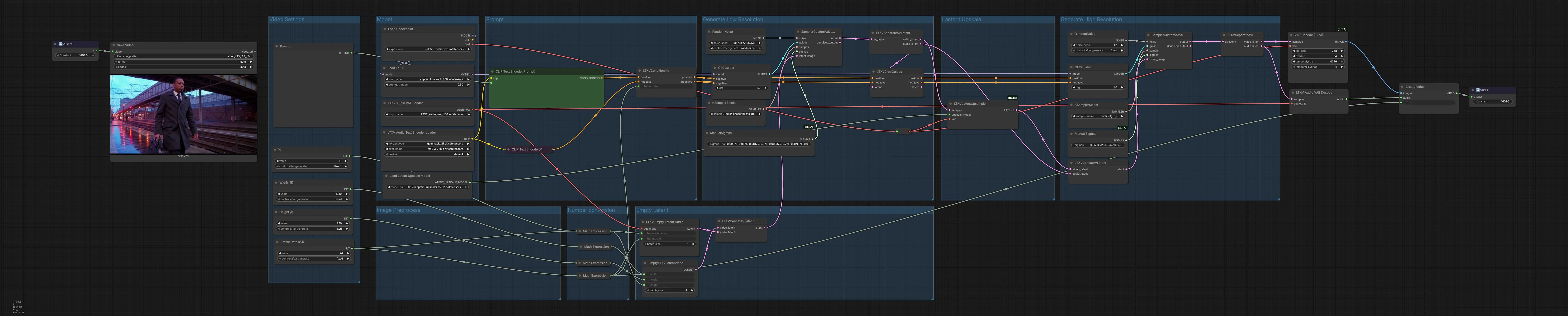
LTX 2.3 Sulphur 2 テキストからビデオへのワークフローによるシネマティックキャラクターアニメーション#
このComfyUIパイプラインは、自然言語のプロンプトを短く、シネマティックでキャラクターフォーカスのビデオに変換します。オプションのオーディオを備え、Lightricks LTX-2.3とSulphur 2コンポーネントに基づいて構築されています。低解像度で生成をステージングし、モーションプランニングを行い、潜在シーケンスをアップスケールし、高解像度で精緻化してフレームにデコードし、同期されたオーディオトラックをマルチプレックスします。
LTX 2.3 Sulphur 2 テキストからビデオへのワークフローは、迅速なキャラクターアニメーションテスト、D-Humanスタイルのモーションコンセプト、および洗練されたテキストからビデオへの実験に最適です。画像からビデオへの入力やプロンプトリレーに依存せず、すべてがテキストから始まり、LTXVコンディショニングがビデオとオーディオの潜在をエンドツーエンドでガイドします。
Comfyui LTX 2.3 Sulphur 2 テキストからビデオへのワークフローの主要モデル#
- Lightricks LTX-2.3。空間時合成とマルチモーダルAV潜在のために使用されるコアテキストからビデオへのジェネレーター。能力と制限に関するメモを含む公式モデルリポジトリを参照してください。 Hugging Face: Lightricks/LTX-2.3
- Lightricks LTX-2.3 FP8チェックポイント。メモリー効率の高いLTX-2.3の変種で、推論速度を向上させ、制約のあるGPUでより長いクリップや高解像度を可能にします。 Hugging Face: Lightricks/LTX-2.3-fp8
- Sulphur 2ベースモデル。このワークフローでLoRAを介してスタイルの事前情報とキャラクターの詳細を提供し、鮮明な顔とシネマティックなトーンを達成します。 Hugging Face: SulphurAI/Sulphur-2-base
- LTX-2.3 Spatial Upscaler x2 1.1。高解像度の精緻化パスの前に空間の詳細を増加させる潜在スペースアップスケーラー。 Hugging Face: Lightricks/LTX-2.3 file ltx-2.3-spatial-upscaler-x2-1.1.safetensors
- LTXテキストエンコーダー (Gemma 3 12B IT、LTX用にパッケージ化)。LTX-2.3のコンディショニングに一致するテキスト埋め込みスペースを提供し、忠実なプロンプトフォローを実現します。 Hugging Face: Comfy-Org/ltx-2
- LTX Audio VAE。ビデオと一緒に生成されたオーディオ潜在をデコードし、最終レンダーに同期サウンドトラックを含めます。 Hugging Face: Lightricks/LTX-2.3
Comfyui LTX 2.3 Sulphur 2 テキストからビデオへのワークフローの使用方法#
全体のロジック このパイプラインは3つのアクトで動作します: 低解像度生成で動きと構成を確立し、潜在アップスケーリングで空間の詳細を増やし、最終的なオーディオも生成する高解像度の精緻化パス。潜在はフレームと波形にデコードされ、MP4コンテナにマルチプレックスされて配信準備が整います。
ビデオ設定 “ビデオ設定”グループを使用して、幅、高さ、フレームレート、持続時間を定義します。フレーム数は持続時間とfpsから自動的に計算されるため、タイミングとリズムが一貫します。これらの値は潜在の割り当てとデコードを駆動するため、ターゲットのアスペクト比と実行時間に合わせて最初に設定してください。ここでfpsを調整することも、モーションのスムーズさとオーディオの整合性に同じクロックを使用するようにコンディショニングに情報を伝えます。
プロンプト “プロンプト”では、LTXテキストエンコーダーをLTXAVTextEncoderLoader (#316)でロードし、CLIPTextEncode (#303)でポジティブな説明を記述し、CLIPTextEncode (#312)で不要な特性を記述します。ノードLTXVConditioning (#304)はポジティブとネガティブのコンディショニングをマージし、選択したフレームレートを追加して時間的ガイダンスがfpsに一致するようにします。ポジティブなプロンプトをショットのブリーフのように扱い、被写体、カメラ、照明、ムード、スタイルの手がかりを記述します。ネガティブリストは定期的に目にするアーティファクトに集中し、削除したいものを記載してください。
モデル “モデル”グループはCheckpointLoaderSimple (#315)を介してメインチェックポイントをロードし、LoraLoaderModelOnly (#285)でSulphur 2 LoRAを適用してシネマティックなテクスチャとキャラクターの忠実度を加えます。これにより、チェックポイントやLoRAを交換して全体の見た目とモーションの事前情報を変更できます。モデル出力は最初と精緻化のガイダーにルーティングされ、スタイルとアイデンティティがパスを通して一貫します。LTX-2.3とSulphur 2の組み合わせにより、パンチの効いたコントラストと動きの中でよく読める詳細な顔が得られます。
数値変換 ユーティリティ式は、fpsと秒を整数のフレームカウントに変換し、下流で使用します。これにより、オーディオとビデオのタイムラインが手動の計算なしで一致します。後でfpsや持続時間を修正した場合、グラフは依存ノードを自動的に更新します。
空の潜在 “空の潜在”は生成のための整列されたコンテナを作成します: EmptyLTXVLatentVideo (#295)はビデオ潜在の空間サイズと長さを定義し、LTXVEmptyLatentAudio (#305)は同じフレームレートでオーディオ潜在を割り当て、LTXVConcatAVLatent (#321)はそれらを単一のAV潜在にマージします。空の潜在から始めることで、ディフュージョンパスがプロンプトとコンディショニングを完全に反映し、既存のコンテンツに影響されません。
低解像度生成 最初のサンプリングステージでは、低コストで動きと構成を確立します。CFGGuider (#313)、KSamplerSelect (#291)、ManualSigmas (#306)はプロンプトが生成と全体のノイズスケジュールをどれだけ強く導くかを管理します。SamplerCustomAdvanced (#283)はAV潜在をノイズ除去して一貫したクリップにします。結果はLTXVSeparateAVLatent (#307)で分割され、LTXVCropGuides (#284)は空間的な注意を精緻化し、後のアップスケーリング中に望む被写体のフレーミングが保持されます。
潜在アップスケール LTXVLatentUpsampler (#287)は、LTX-2.3 x2アップスケーラーを使用して空間の詳細を引き上げ、速度と安定性を保ちながら潜在スペースに留まります。アップスケールされたビデオ潜在を前方に供給することで、テクスチャと可読性が向上し、高解像度の精緻化の前に保存されます。これにより、最初のパスから気に入った動きを維持しながら、エッジがシャープになり、素材が豊かになります。
高解像度生成 アップスケールされたビデオ潜在は、LTXVConcatAVLatent (#278)でオーディオ潜在と再結合され、最終品質のために再度ガイドされます。CFGGuider (#282)、KSamplerSelect (#280)、ManualSigmas (#281)はプロンプトの強度、詳細、および時間的一貫性について最後の言葉を与え、SamplerCustomAdvanced (#308)は精緻化されたAV潜在を生成します。LTXVSeparateAVLatent (#309)はビデオをVAEDecodeTiled (#314)に渡してメモリーに優しいフレームデコードを行い、オーディオをLTXVAudioVAEDecode (#297)に渡して波形を再構築します。CreateVideo (#310)はフレームとオーディオをターゲットfpsでマルチプレックスし、SaveVideo (#75)はMP4/H.264ファイルに書き込みます。
画像プリプロセス このエリアは、タイル化と潜在アップスケーリングがVRAMの予算内で動作するようにベースVAEとアップスケーラーモデルをルーティングします。メモリープレッシャーを感じる場合は、FP8 LTX-2.3ウェイトを優先し、タイル化デコードを有効にしてスループットと品質を維持してください。
Comfyui LTX 2.3 Sulphur 2 テキストからビデオへのワークフローの主要ノード#
LTXVConditioning (#304) ポジティブおよびネガティブなテキストコンディショニングをマージし、作業フレームレートを添付して時間的ガイダンスがレンダーに一致するようにします。強力で具体的なシーン言語はショット構造を改善し、簡潔なネガティブはアーティファクトを減少させます。LTX-2.3モデルカードでコンディショニングノートを確認してください。 Hugging Face: Lightricks/LTX-2.3
LTXVCropGuides (#284) メインの被写体が意図した通りにフレーム内に収まるように構成をソフトに誘導します。アップスケーリングと精緻化の前に顔サイズ、地平線の配置、または中央の被写体を保護するために使用します。特に対話スタイルのショットや中距離のクローズアップに役立ちます。
CFGGuider (#313, #282) プロンプトがディフュージョントラジェクトリーにどれだけ積極的に影響を与えるかを制御します。最初のガイダーを使用して動きとステージングを固定し、次にシャープネスを追加しつつ確立されたショットから逸脱しないようにします。
ManualSigmas (#306, #281) ノイズスケジュールを定義します。ノイズを多く前置することで大きな動きの探索を促し、穏やかなスケジュールは時間的一貫性を強調します。低解像度と高解像度のスケジュールを補完的に保ち、同一にしないようにします。
LTXVLatentUpsampler (#287) 公式のLTXアップスケーラーを使用してx2の潜在アップスケーリングを行い、精緻化サンプラーの前に詳細を得ます。別のLTX-2.3アップスケーラーバリアントに切り替えることで、シャープネスと粒状感がわずかに変わることがあります。 Hugging Face: Lightricks/LTX-2.3
VAEDecodeTiled (#314) 長いまたは大きなクリップを管理可能なタイルでデコードし、VRAMの急上昇を避けます。空間サイズやクリップの長さを変更する場合は、メモリーヘッドルームとデコード速度のバランスを取るためにタイル化を調整してください。
LoraLoaderModelOnly (#285) Sulphur 2 LoRAをベースモデルパスに適用し、キャラクターの忠実度とスタイルの手がかりを両方のサンプリングステージに転送します。これを使用して、同じLTX-2.3バックボーンを維持しつつ、迅速にルックを切り替えます。 Hugging Face: SulphurAI/Sulphur-2-base
オプションの追加#
- シード制御: 両方の
RandomNoiseノードで固定値を設定し、テイクを再現可能にします。一つのシードを変更して代替を探ります。 - プロンプト: プロンプトをショットの指示(被写体、カメラ、照明、ムード)として書きます。ネガティブリストは集中し短く保ちます。
- パフォーマンス: VRAMが限られている場合は、FP8 LTX-2.3ウェイトを優先し、タイル化デコードを有効に保ちます。
- 出力: グラフはMP4/H.264を書き出しますが、
SaveVideoでコンテナやコーデックを変更し、ProResプロキシワークフローを使用できます。
このLTX json 2.3 Sulphur 2 テキストからビデオへのワークフローは、プロンプトから同期オーディオ付きの洗練されたビデオまでのクリーンでエンドツーエンドのパスを提供し、シネマティックキャラクターアニメーションの迅速な反復に対応しています。
謝辞#
このワークフローは、以下の作品とリソースを実装および構築しています。Sulphur2 Basic Workflow for Video ProductionのためのRunningHub、Sulphur-2-baseモデルのためのSulphurAI、LTX-2.3およびLTX-2.3-fp8モデルのためのLightricks、LTX-2テキストエンコーダーのためのComfy-Orgに感謝します。詳細については、以下にリンクされたオリジナルのドキュメントおよびリポジトリを参照してください。
リソース#
- RunningHub/Sulphur2 Basic Workflow for Video Production
- ドキュメント / リリースノート: Sulphur2 Basic Workflow for Video Production
- SulphurAI/Sulphur-2-base
- Hugging Face: SulphurAI/Sulphur-2-base
- Lightricks/LTX-2.3
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3
- arXiv: LTX-2: Efficient Joint Audio-Visual Foundation Model (2601.03233)
- Lightricks/LTX-2.3-fp8
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3-fp8
- arXiv: LTX-2: Efficient Joint Audio-Visual Foundation Model (2601.03233)
- Comfy-Org/ltx-2
- Hugging Face: Comfy-Org/ltx-2
注: 参照されたモデル、データセット、およびコードの使用は、それぞれの著者およびメンテナによって提供されたライセンスおよび条件に従います。