
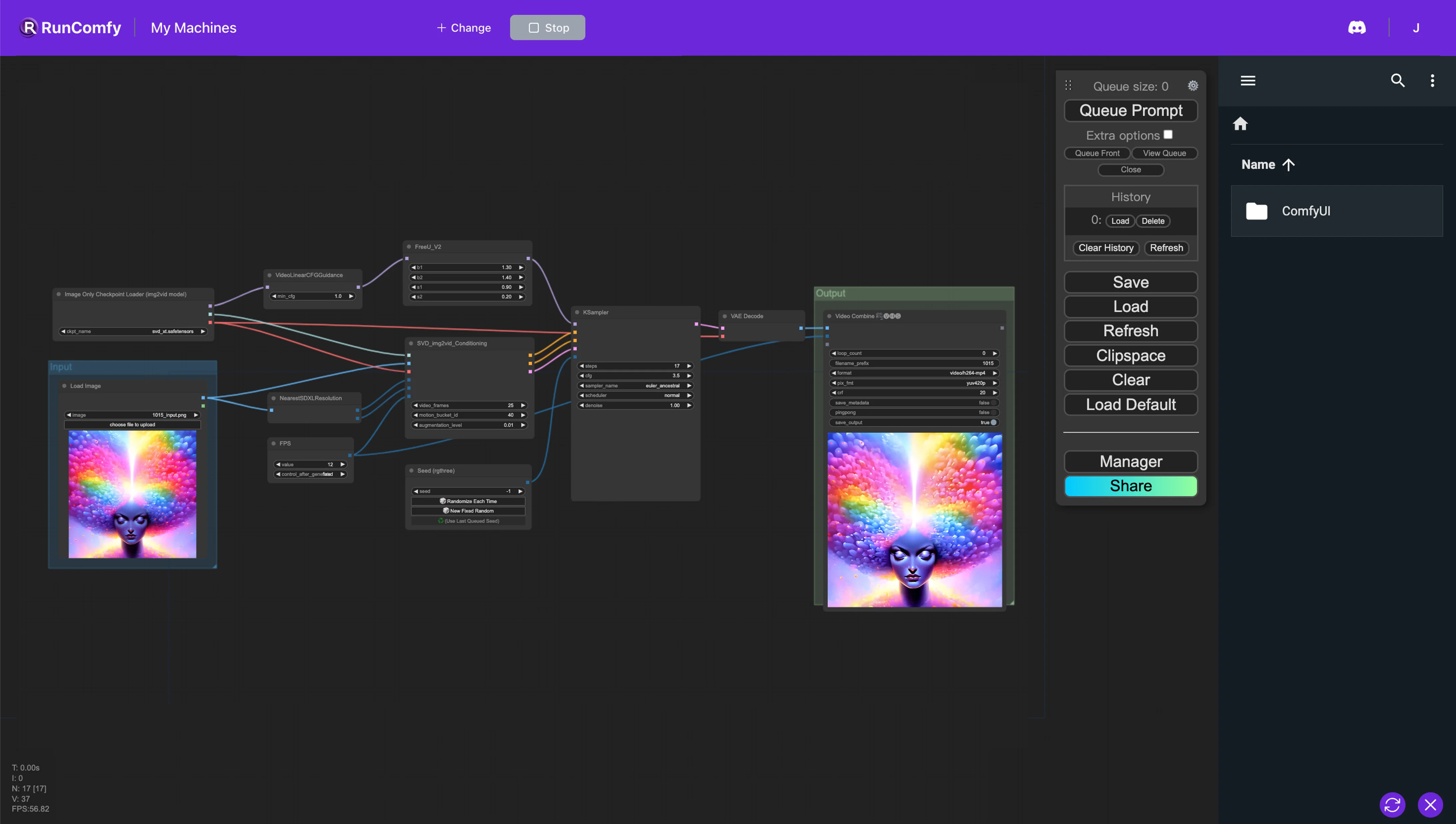
1. ComfyUI Stable Video Diffusion (SVD) と FreeU ワークフロー#
このComfyUIワークフローは、Stable Video Diffusion (SVD) とFreeUを活用することで、最適化された画像からビデオへの変換パイプラインを実現します。FreeUは、再トレーニング、パラメーター拡張、メモリやコンピュート時間の増加を必要とせずに、ディフュージョンモデルの結果を向上させます。このインテグレーションにより、ビデオ出力の忠実度を高めることができます。
2. Stable Video Diffusion (SVD) の概要#
詳細については、SVDの紹介をご覧ください。
3. FreeUの概要#
詳細については、FreeUの紹介をご覧ください。