
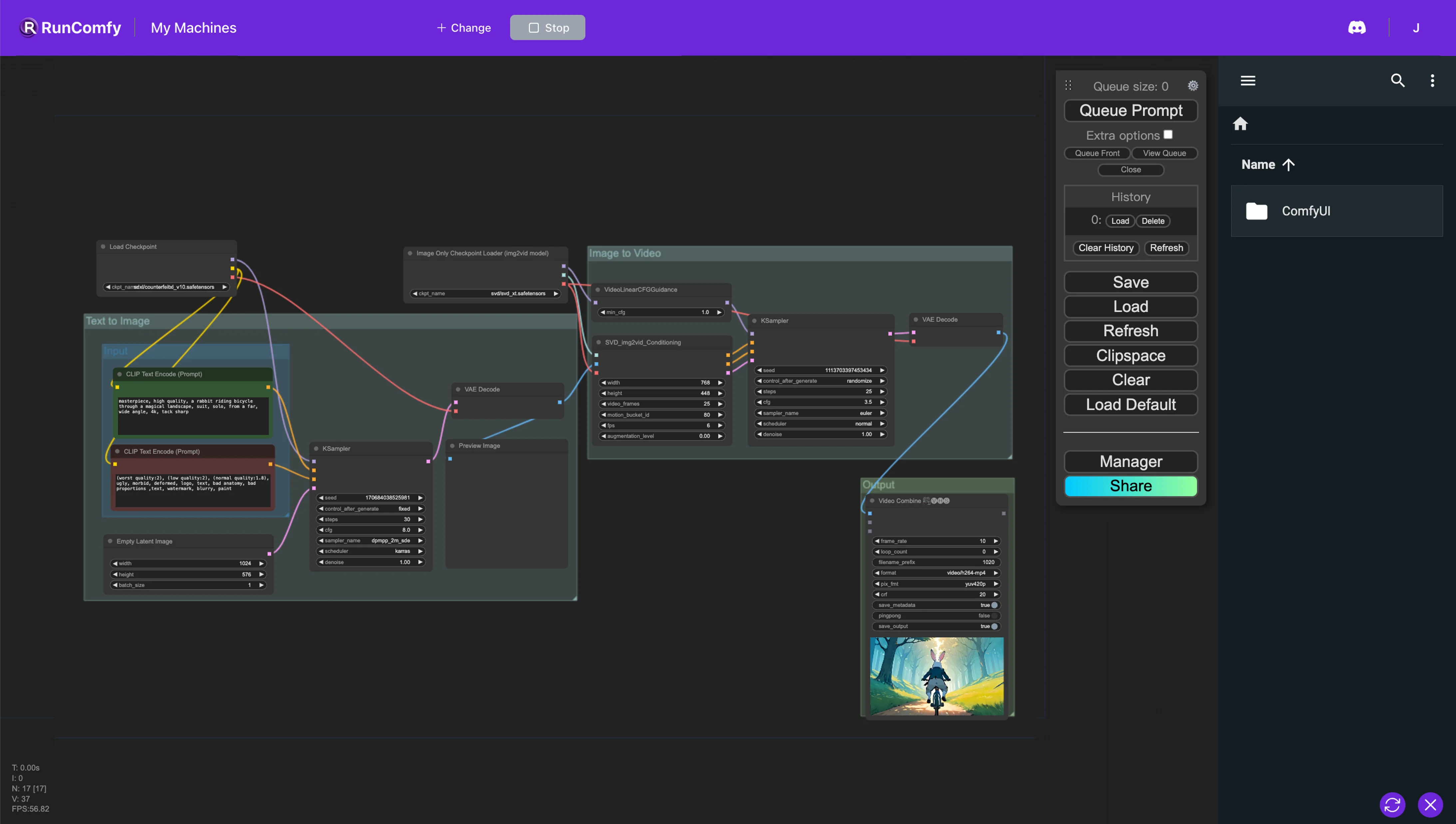
1. ComfyUI Stable Video Diffusion (SVD) Workflow#
The ComfyUI workflow seamlessly integrates text-to-image (Stable Diffusion) and image-to-video (Stable Video Diffusion) technologies for efficient text-to-video conversion. This workflow allows you to generate videos directly from text descriptions, starting with a base image that evolves into a dynamic video sequence. This workflow facilitates the realization of text-to-video animations or videos.
2. Overview of Stable Video Diffusion (SVD)#
2.1. Introduction to Stable Video Diffusion (SVD)#
Stable Video Diffusion (SVD) is a state-of-the-art technology developed to convert static images into dynamic video content. Leveraging the foundational Stable Diffusion image model, SVD introduces motion to still images, facilitating the creation of brief video clips. This advancement in latent diffusion models, initially devised for image synthesis, now incorporates temporal dimensions to animate still visuals, producing videos typically within the range of 2 to 5 seconds.
Stable Video Diffusion is available in two variants: the standard SVD, capable of generating videos at a resolution of 576×1024 pixels across 14 frames, and the enhanced SVD-XT, which can produce up to 25 frames. Both variants support adjustable frame rates from 3 to 30 frames per second, addressing diverse digital content creation requirements.
The training of the SVD model involves a three-stage process: starting with an image model, transitioning to a video model pre-trained with an extensive video dataset, and refining with a selection of high-quality video clips. This meticulous process highlights the significance of dataset quality in optimizing the model's video production capabilities.
At the heart of the Stable Video Diffusion model is the Stable Diffusion 2.1 image model, which acts as the foundational image backbone. The integration of temporal convolution and attention layers into the U-Net noise estimator evolves this into a powerful video model, interpreting latent tensors as video sequences. This model employs reverse diffusion to simultaneously denoise all frames, akin to the VideoLDM model.
Equipped with 1.5 billion parameters and trained on a vast video dataset, the model undergoes further fine-tuning with a high-quality video dataset for peak performance. Two sets of SVD model weights are publicly accessible, designed for generating 14-frame and 25-frame videos at 576×1024 resolution, respectively.
2.2. Key Features of Stable Video Diffusion (SVD)#
When using Stable video Diffusion in ComfyUI workflow, you can adjust the key parameters for video output customization include the motion bucket id, controlling the video's motion intensity; frames per second (fps), determining the frame rate; and the augmentation level, adjusting the initial image's noise level for various transformation degrees.
2.2.1. Motion Bucket ID: This feature offers users the ability to control the video's motion intensity. By tweaking this parameter, you can dictate the amount of movement observed in the video, ranging from subtle gestures to more pronounced action, depending on the desired visual effect.
2.2.2. Frames Per Second (fps): This parameter is crucial for determining the video's playback speed. Adjusting the frames per second allows you to produce videos that can either capture the swift dynamics of a scene or present a slow-motion effect, thereby enhancing the storytelling aspect of the video content. This flexibility is particularly beneficial for creating a wide range of video types, from fast-paced advertisements to more contemplative, narrative-driven pieces.
2.2.3.Augmentation Level Parameter: This adjusts the initial image's noise level, enabling various degrees of transformation. By manipulating this parameter, you can control the extent to which the original image is altered during the video creation process. Adjusting the augmentation level allows for maintaining closer fidelity to the original image or venturing into more abstract and artistic interpretations, thus expanding creative possibilities.