
SeedVR2 V2.5 video upscaling workflow for ComfyUI#
SeedVR2 V2.5 is a high-fidelity video and image upscaler that restores detail, sharpens textures, and improves temporal consistency while keeping motion smooth. This ComfyUI workflow wraps the SeedVR2 diffusion transformer and its VAE so you can upscale AI-generated clips, archive footage, or post-process renders into cleaner, more cinematic results.
Designed for artists and editors, the SeedVR2 V2.5 workflow handles both single images and full videos, including RGBA content, and preserves original audio and frame rate when reassembling the upscaled video. It includes optional compile-time acceleration and model choices that balance quality, VRAM, and speed.
Key models in ComfyUI SeedVR2 V2.5 workflow#
- SeedVR2 Diffusion Transformer 3B and 7B. Core one-step restoration models that enhance resolution and perceptual quality while maintaining temporal coherence. Use 3B for lower VRAM or faster turnaround and 7B when you want the highest fidelity. See the official model cards and paper for details: ByteDance-Seed/SeedVR2-3B, ByteDance-Seed/SeedVR2-7B, and the SeedVR2 paper on one-step video restoration arXiv:2506.05301.
- SeedVR2 VAE (ema_vae_fp16). Variational Autoencoder used to encode frames to latent space and decode the restored results back to RGB with tiling support for large resolutions. Distributed with the ComfyUI integration: numz/SeedVR2_comfyUI.
- Optional quantized variants. The community integration exposes FP8 and GGUF options to reduce memory at some quality or speed tradeoff. See the ComfyUI SeedVR2 node repository for current options: ComfyUI-SeedVR2_VideoUpscaler.
How to use ComfyUI SeedVR2 V2.5 workflow#
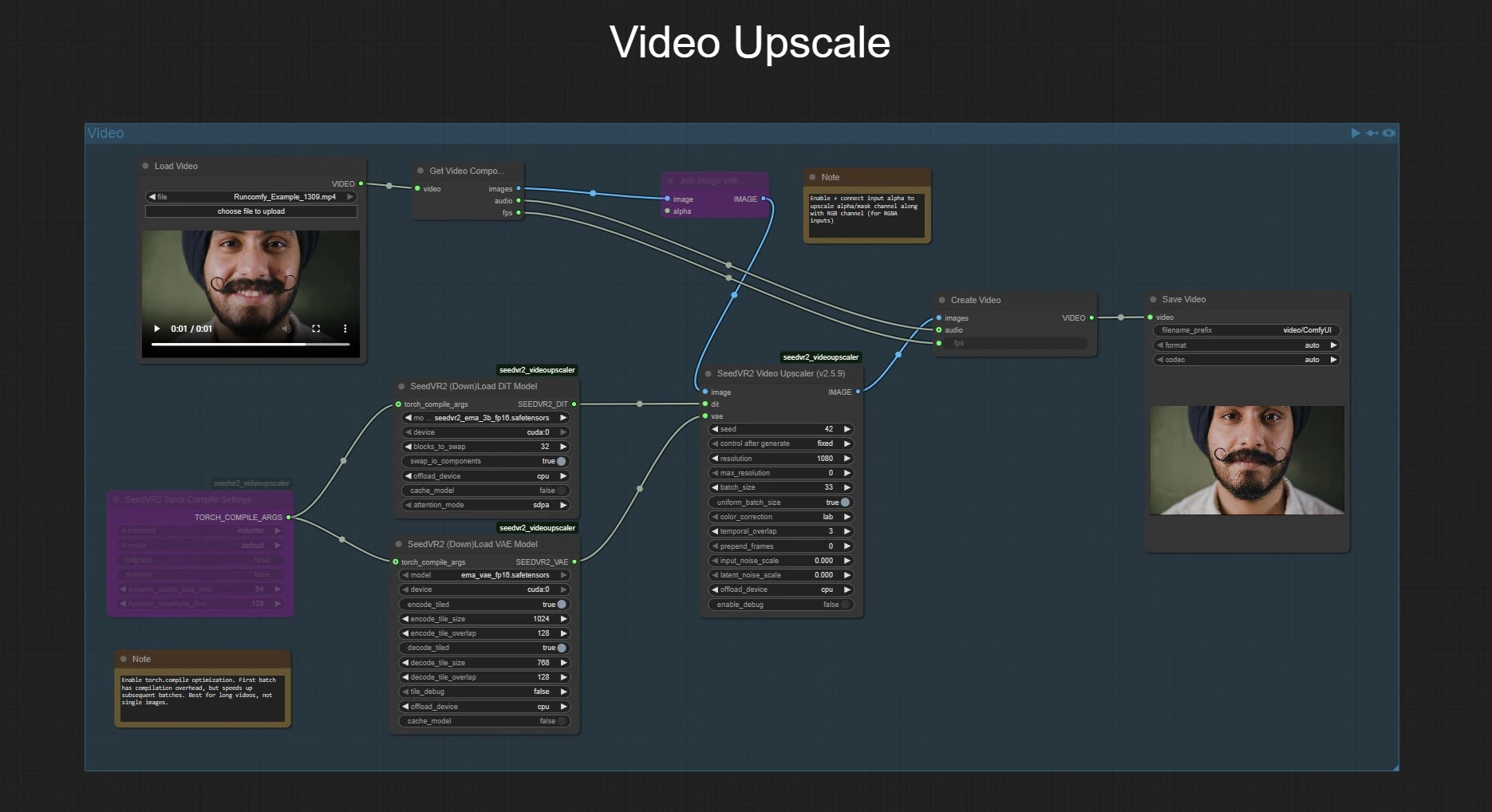
This graph has two independent groups that share the same model loaders and upscaler logic. Use the Image group for single stills. Use the Video group to split a video into frames and audio, upscale the frames with SeedVR2 V2.5, then reassemble the clip with original audio and fps.
Image group#
Load a still with LoadImage (#27). If your image has transparency, route it through JoinImageWithAlpha (#31) so the alpha channel is preserved through upscaling. Choose and load a DiT checkpoint with SeedVR2LoadDiTModel (#28) and a VAE with SeedVR2LoadVAEModel (#29); the models download automatically on first use. Feed the image into SeedVR2VideoUpscaler (#30) to upscale and restore; the node focuses on detail recovery and controlled sharpening that matches SeedVR2 V2.5’s look. Save results with SaveImage (#32). For batch runs, you can enable SeedVR2TorchCompileSettings (#25) to compile the graph once and speed subsequent batches.
Video group#
Import a clip with LoadVideo (#21), then GetVideoComponents (#22) extracts frames, audio, and fps. If your frames contain alpha, merge it via JoinImageWithAlpha (#17) before upscaling. Load your chosen DiT and VAE with SeedVR2LoadDiTModel (#14) and SeedVR2LoadVAEModel (#13), then upscale the frame stream with SeedVR2VideoUpscaler (#10). Rebuild the video using CreateVideo (#24), which passes through the original audio and fps, and write the file with SaveVideo (#23). For long clips, SeedVR2TorchCompileSettings (#19) reduces per-iteration time after an initial compile step.
Key nodes in ComfyUI SeedVR2 V2.5 workflow#
SeedVR2VideoUpscaler (#10 and #30) Central restoration and upscaling node powered by SeedVR2. Set your target upscale objective either by scale or target dimensions, and choose a batch size that fits your GPU. Temporal consistency is driven by processing multiple neighboring frames together; the official guidance notes that a batch of at least 5 frames activates temporal consistency for videos, with larger batches improving stability if VRAM allows ComfyUI-SeedVR2_VideoUpscaler. For RGBA, ensure the alpha path is connected upstream. If you see memory pressure at high resolutions, lower the target resolution or switch to a lighter model variant.
SeedVR2LoadDiTModel (#14 and #28) Loads the SeedVR2 transformer checkpoint and configures the inference device. Pick between 3B and 7B according to your quality and VRAM budget; FP16 offers the best fidelity, while FP8 or GGUF can help on constrained GPUs as exposed by the community integration numz/SeedVR2_comfyUI and the official ComfyUI node repo ComfyUI-SeedVR2_VideoUpscaler. Keep the DiT on your fastest GPU unless you are explicitly offloading for memory.
SeedVR2LoadVAEModel (#13 and #29) Loads the EMA VAE used for encode and decode. When targeting large outputs, enable tiled encode or decode to reduce peak VRAM at a small cost in speed; adjust tile size and overlap only if you encounter OOM or edge artifacts. Offloading the VAE to CPU or another GPU can free room for the DiT without changing results numz/SeedVR2_comfyUI.
SeedVR2TorchCompileSettings (#19 and #25) Optional speed-up that compiles parts of the SeedVR2 path to a fused kernel plan. The first run pays a compilation cost, then subsequent batches are faster, which is ideal for longer videos or repeated iterations ComfyUI-SeedVR2_VideoUpscaler.
Optional extras#
- Pick the model to match your job: 3B for speed or limited VRAM, 7B when absolute detail matters SeedVR2-3B, SeedVR2-7B.
- Preserve audio and timing by keeping the
audioandfpsoutputs fromGetVideoComponents(#22) connected toCreateVideo(#24). - For heavy content with transparency, ensure alpha is merged via
JoinImageWithAlphabefore the upscaler to keep edges crisp in compositing. - If you hit OOM, try a lower output resolution, switch to the 3B model, enable VAE tiling, or use a quantized checkpoint where available numz/SeedVR2_comfyUI.
- For deeper background on how SeedVR2 achieves one-step restoration with adaptive window attention and adversarial post-training, see the paper arXiv:2506.05301 and reference implementation IceClear/SeedVR2.
Acknowledgements#
This workflow implements and builds upon the following works and resources. We gratefully acknowledge numz for the ComfyUI-SeedVR2_VideoUpscaler (SeedVR2 v2.5 nodes/workflow), and AInVFX for the official SeedVR2 v2.5 video tutorial, for their contributions and maintenance. For authoritative details, please refer to the original documentation and repositories linked below.
Resources#
- SeedVR2 V2.5 Source: https://www.reddit.com/r/comfyui/comments/1ordkfc/seedvr2_v25_released_complete_redesign_with_gguf
- GitHub: numz/ComfyUI-SeedVR2_VideoUpscaler
- Docs / Release Notes: Reddit post
- SeedVR2 V2.5 Youtube Demo: https://www.youtube.com/watch?v=MBtWYXq_r60
- Docs / Release Notes @AInVFX: YouTube video
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.


