







The OmniGen-ComfyUI nodes and its associated workflow are fully developed by AIFSH and saftle. We give all due credit to AIFSH and saftle for this innovative work. On the RunComfy platform, we are simply presenting AIFSH's and saftle’s contributions to the community. It is important to note that there is currently no formal connection or partnership between RunComfy and AIFSH and saftle. We deeply appreciate AIFSH's and saftle’s work!
The ComfyUI OmniGen workflow enables you to manipluate a photo to change subject's cloths, background, Clothes Virtual Try On, Selfie with Celbrity, add or remove elements and much more. You can add upto 3 reference images for getting your desired results.
OmniGen#
OmniGen is a versatile, unified image generation model designed to create diverse visuals from multi-modal prompts with simplicity and flexibility. Unlike traditional models, it eliminates the need for extra modules like ControlNet or preprocessing steps such as pose estimation, enabling direct output through text-based instructions. Inspired by GPT's seamless approach to text generation, OmniGen empowers users to fine-tune it for any creative or specialized task with minimal effort. Its innovative framework makes image generation more accessible, fostering limitless possibilities for visual creativity. OmniGen is a step forward in universal image generation, inspiring the next wave of transformative AI tools.
1.1 How to Use OmniGen Workflow?#
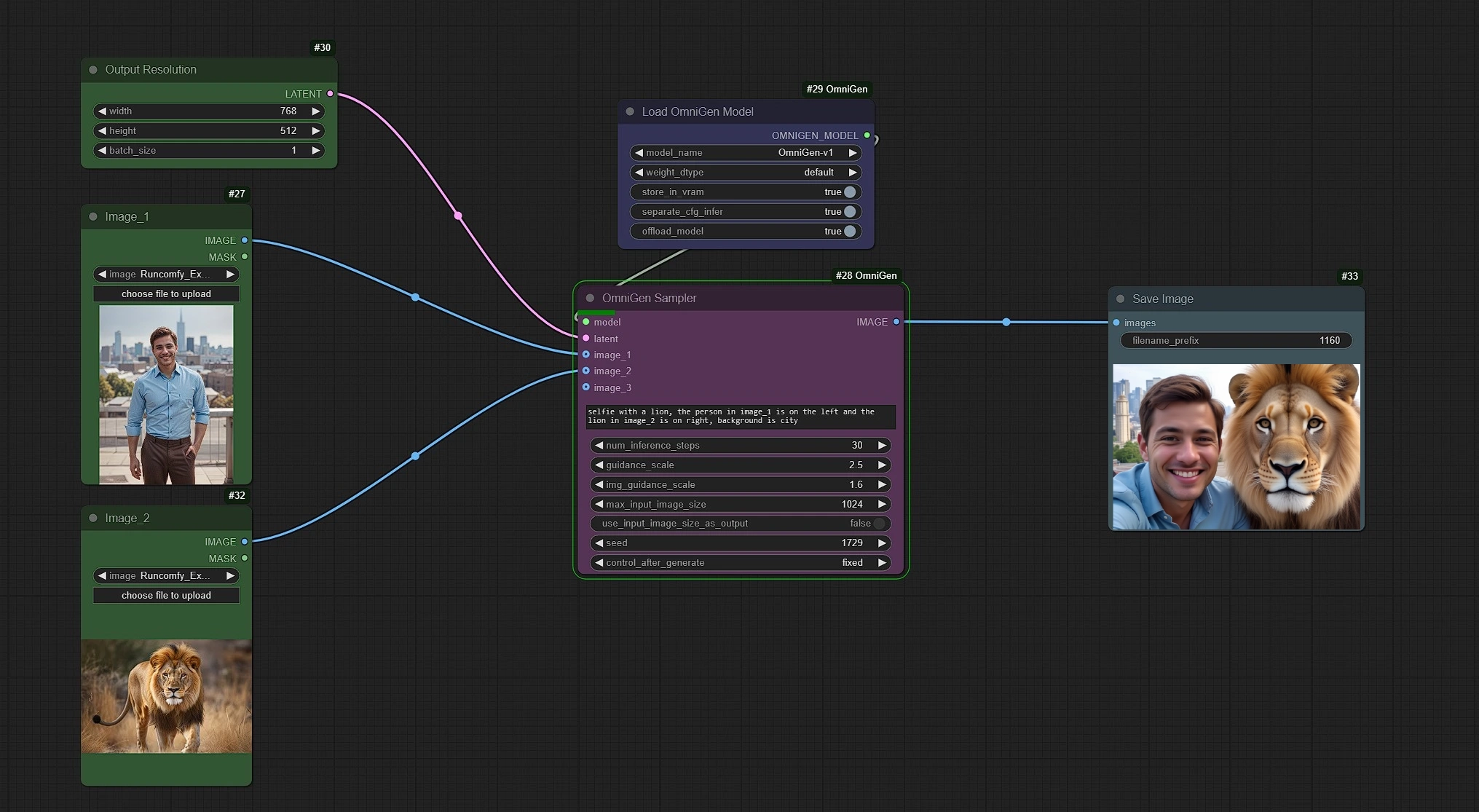
In this workflow, Left Green nodes are the inputs for Reference Images and Resolutions. Middle Pink and Purple nodes are the OmniGen unsampler and OmniGen Model Loader and Right Blue is the Image Save node.
- Upload your reference Images.
- Enter your resolution and prompts
- Click Queue
No need to setup anything, Rendered as simple as that.
1.2 Load Reference Input Images#
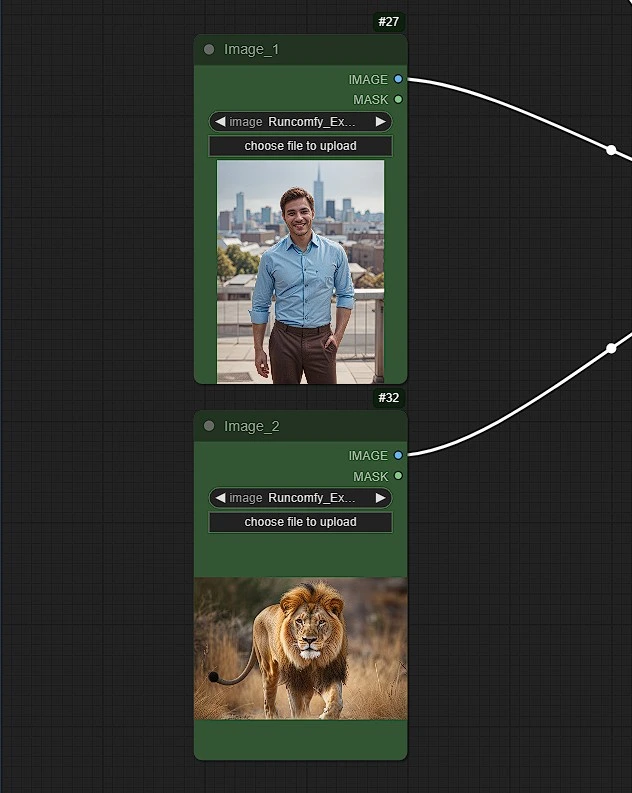
- Upload 1, 2 or upto 3 Reference Images, elements like clothes, persons, celebrities, animals, etc.
- These Images will also be Used in Prompts with Trigger word as "image_1" , "image_2" and "image_3" respectively.
1.3 Resolution#
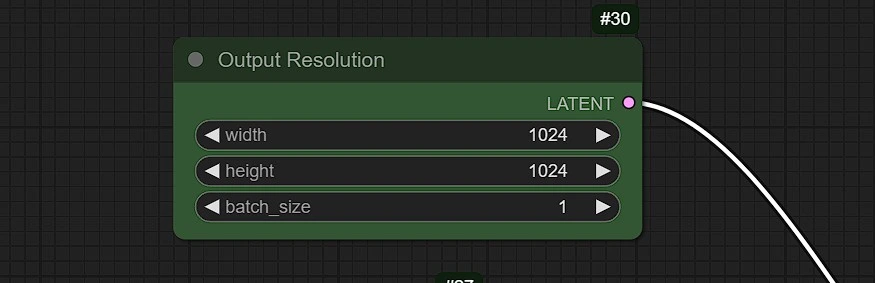
- In this node set your resolution for your output image.
- In higher image resolution (above 1k) more Vram will be consumed also chances of double figures or subjects may occour.
- You can change the batch_size and the seed to randomize in the sampler to generate variations.
1.4 OmniGen Sampler and Prompts#
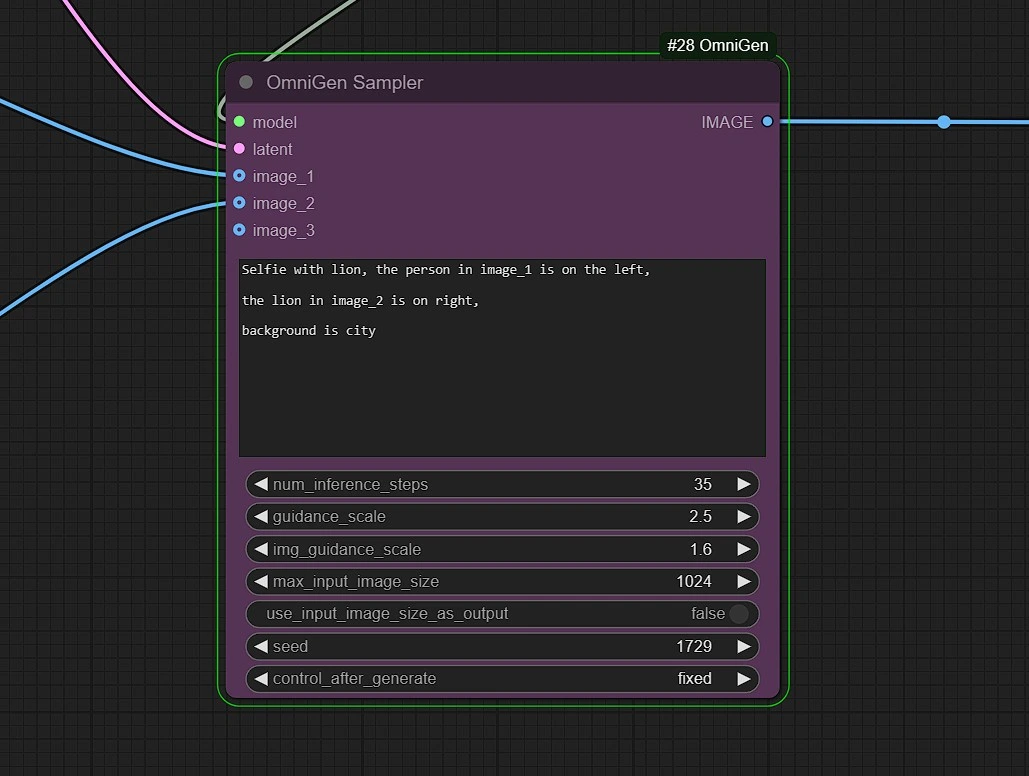
- Prompt: Add your prompts based on your reference images. Denote input images as "image_1" , "image_2" and "image_3".
- Example: The Person in image_1 is wearing jacket from image_2.
num_inferene_step:This set the sampling steps for OmniGen, Use value around 25-35 for good resultsimg_guidance_scale:This sets the weightage/Strength for the reference image(s).max_input_image_size:This caps the resolutions of the inputs.
1.5 OmniGen Models#
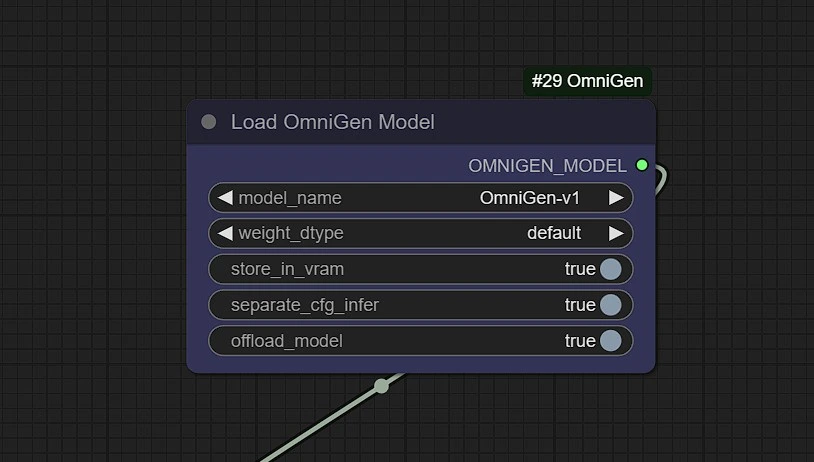
Models are downloaded from this Shitao's Hugging Face Repo, in your comfyui/model/OmniGen Folder manually by the runcomfy server. It may take upto 3-5 mins to make a local copy on your machine.
You can Upload OmniGen other models here when they are released.
OmniGen redefines image generation by offering a unified, flexible approach that simplifies workflows and removes the need for additional tools or preprocessing. Its easy fine-tuning and multi-modal capabilities open new possibilities for creative and specialized tasks. OmniGen sets the stage for more accessible and innovative AI-driven visual generation in the future.

