

Stable Diffusion 3.5 VS FLUX.1#
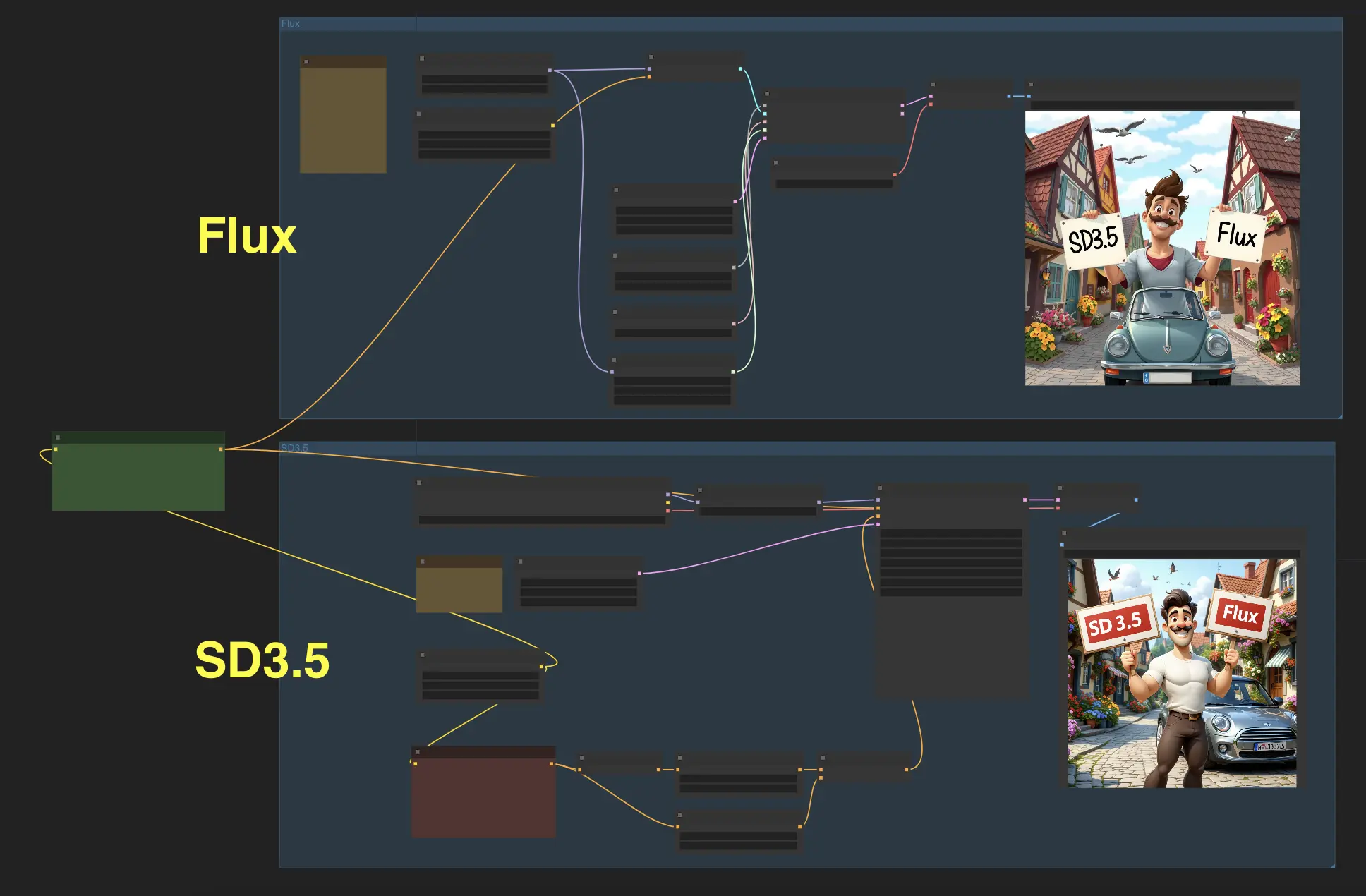
Get ready to witness the awe-inspiring capabilities of two cutting-edge models: Stable Diffusion 3.5 (SD3.5) and FLUX.1? With this ComfyUI workflow, you can now input a text prompt and generate images with these two models simultaneously, allowing you to compare the results and choose the one you like best.
We have tested some cases using SD3.5-large and Flux.1-schnell, and the results reveal that Stable Diffusion 3.5 (SD3.5) and FLUX.1 each excel in different areas. While FLUX.1 has an advantage in producing photorealistic images, SD3.5 demonstrates greater proficiency in generating anime-style artwork without requiring additional fine-tuning or modifications.
Don't just take our word for it – experience the magic for yourself!







