
Qwen Image 2512 LoRA Inference: pipeline-aligned, training-matched AI Toolkit generations in ComfyUI#
This production-ready RunComfy workflow applies an AI Toolkit–trained LoRA to Qwen Image 2512 in ComfyUI with a focus on training-matched behavior. It centers on RC Qwen Image 2512 (RCQwenImage2512)—a RunComfy-built, open-sourced custom node (source) that runs a Qwen-native inference pipeline (instead of a generic sampler graph) and loads your adapter through lora_path and lora_scale.
Why Qwen Image 2512 LoRA Inference often looks different in ComfyUI#
AI Toolkit previews for Qwen Image 2512 are produced by a model-specific pipeline, including Qwen’s “true CFG” guidance behavior and the defaults that pipeline uses for conditioning and sampling. If you rebuild the same job as a standard ComfyUI sampler graph, the guidance semantics and the LoRA patch point can shift—so “same prompt + same seed + same steps” can still land on a different-looking result. In practice, many “my LoRA doesn’t match training” reports are pipeline mismatches, not one missing parameter.
RCQwenImage2512 keeps inference aligned by wrapping the Qwen Image 2512 pipeline inside the node and applying the LoRA in that pipeline via lora_path and lora_scale. Pipeline source: `src/pipelines/qwen_image.py`.
How to use the Qwen Image 2512 LoRA Inference workflow#
Step 1: Open the workflow#
Launch the cloud workflow in ComfyUI.
Step 2: Import your LoRA (2 options)#
- Option A (RunComfy training result): RunComfy → Trainer → LoRA Assets → find your LoRA → ⋮ → Copy LoRA Link

- Option B (AI Toolkit LoRA trained outside RunComfy): Copy a direct
.safetensorsdownload link for your LoRA and paste that URL intolora_path(no need to download intoComfyUI/models/loras)
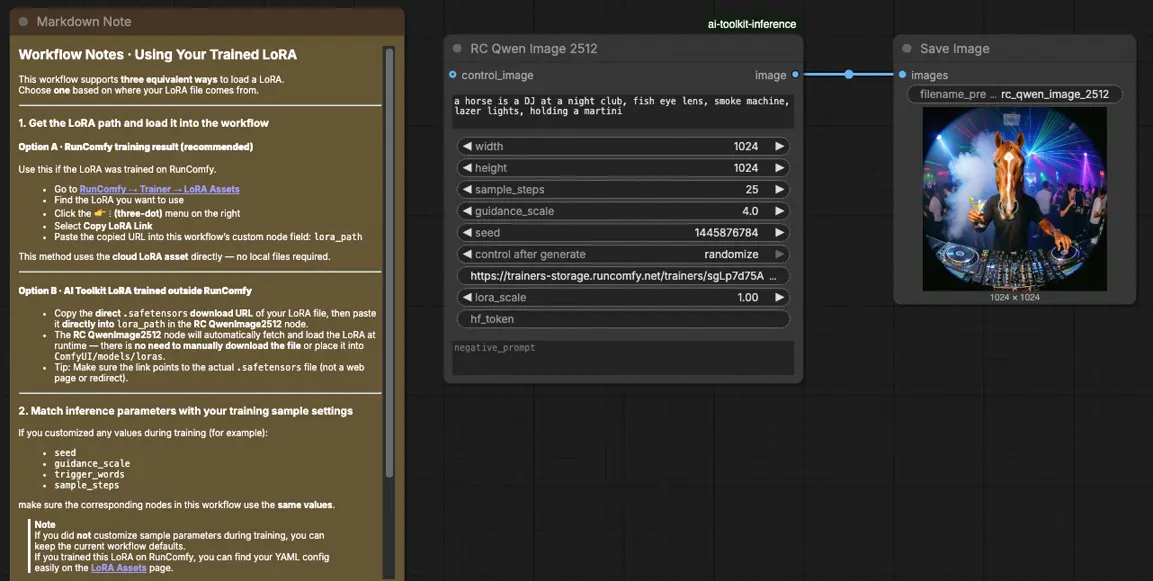
Step 3: Configure the RCQwenImage2512 custom node for Qwen Image 2512 LoRA Inference#
Paste your LoRA link into lora_path on RC Qwen Image 2512 (RCQwenImage2512).

Then set the remaining node parameters (start by matching the values you used for preview/sample generation during training):
prompt: your positive prompt (include any trigger tokens your LoRA expects)negative_prompt: optional; keep it empty if you did not use negatives in your previewswidth/height: output resolution (multiples of 32 are recommended for this pipeline family)sample_steps: inference steps; mirror your preview step count before tuning (25 is a common baseline)guidance_scale: guidance strength (Qwen uses a “true CFG” scale, so reuse your preview value first)seed: lock the seed while you validate alignment by setting the control_after_generate to 'fixed', then vary it for new sampleslora_scale: LoRA strength; begin near your preview value and adjust in small increments
This is a text-to-image workflow, so you do not need to provide an input image.
Training alignment note: if you customized sampling during training, open your AI Toolkit training YAML and mirror width, height, sample_steps, guidance_scale, seed, and lora_scale. If you trained on RunComfy, open Trainer → LoRA Assets → Config and copy the preview/sample values into RCQwenImage2512 before you iterate.

Step 4: Run Qwen Image 2512 LoRA Inference#
Click Queue/Run. The SaveImage node saves the generated image to your standard ComfyUI output folder.
Troubleshooting Qwen Image 2512 LoRA Inference#
RunComfy’s RC Qwen Image 2512 (RCQwenImage2512) custom node is designed to keep inference pipeline-aligned with Qwen Image 2512 preview-style sampling by:
- executing a Qwen-native inference pipeline inside the node (not a generic sampler graph), and
- injecting the LoRA via
lora_path+lora_scaleinside that pipeline (consistent patch point).
(1)Qwen-Image Loras not working in comfyui#
Why this happens
Users reported that AI Toolkit–trained Qwen-Image LoRAs can fail to apply in ComfyUI because the LoRA state-dict key prefixes don’t match what the ComfyUI-side loader/inference path expects (so the adapter loads “silently” but does not actually patch the Qwen transformer modules).
How to fix (user-verified options)
- Use RCQwenImage2512 for pipeline-level LoRA injection: load the adapter only via
lora_path+lora_scaleon RCQwenImage2512 (avoid stacking extra LoRA loader nodes on top while debugging). This keeps the LoRA patch point aligned with the Qwen pipeline used by preview-style sampling. - If you must use a non-RC inference provider / loader path: a user-reported fix is to rename the LoRA keys by replacing the first segment of the LoRA key prefix from
diffusion_model→transformer, so the weights map onto the expected Qwen transformer modules (see the issue for the exact context and why this is needed).
(2)Patch for crash when using inference_lora_path with qwen image (allows for generating samples with turbo lora)#
Why this happens
Some users hit a crash when they try to load an inference LoRA for Qwen (including Qwen-Image-2512) through AI Toolkit’s inference_lora_path flow. This is not a “prompt/CFG/seed” problem—it's an inference loading-path issue.
How to fix (user-verified)
- Apply the patch / update to a version that includes the patch described in the issue. The issue author reports that the patch fixes the crash when loading an inference LoRA for Qwen (see the issue for the exact change and the config context).
- For ComfyUI inference specifically: prefer RCQwenImage2512 and load the adapter via
lora_path/lora_scaleinside the RC node. This avoids relying on external inference LoRA loading routes and keeps the pipeline consistent with preview-style sampling.
(3)using sageattention 2 qwen-image in comfyui shows black images due to NaNs (i.e. black images)#
Why this happens
Users reported that running Qwen Image in ComfyUI with SageAttention can produce NaNs that turn into black images. This can look like “my LoRA is broken,” but it’s actually the attention backend producing invalid values—pipeline execution fails before you can meaningfully evaluate LoRA behavior.
How to fix (user-verified)
- Don’t use
--use-sage-attentionfor Qwen Image when it causes NaNs/black output. Validate a clean baseline first (non-black outputs), then evaluate LoRA impact. - If you need SageAttention speedups: fixing Qwen black-output by forcing a CUDA backend path. In practice, this often means using a workflow-level patch (e.g., a “Patch Sage Attention” node) and selecting a CUDA backend variant that avoids the broken Triton path for the affected GPU/arch.
- After you have stable (non-black) baseline outputs, run Qwen Image 2512 inference through RCQwenImage2512 so the pipeline + LoRA injection point stays preview-aligned while you match
width/height/sample_steps/guidance_scale/seed/lora_scale.
Run Qwen Image 2512 LoRA Inference now#
Open the shared workflow, paste your LoRA URL into lora_path, match your preview sampling values, and run RCQwenImage2512 for training-matched Qwen Image 2512 generations in ComfyUI.


