
VOID ビデオインペイント ComfyUI: インタラクションを考慮したオブジェクト除去でクリーンで一貫したビデオ#
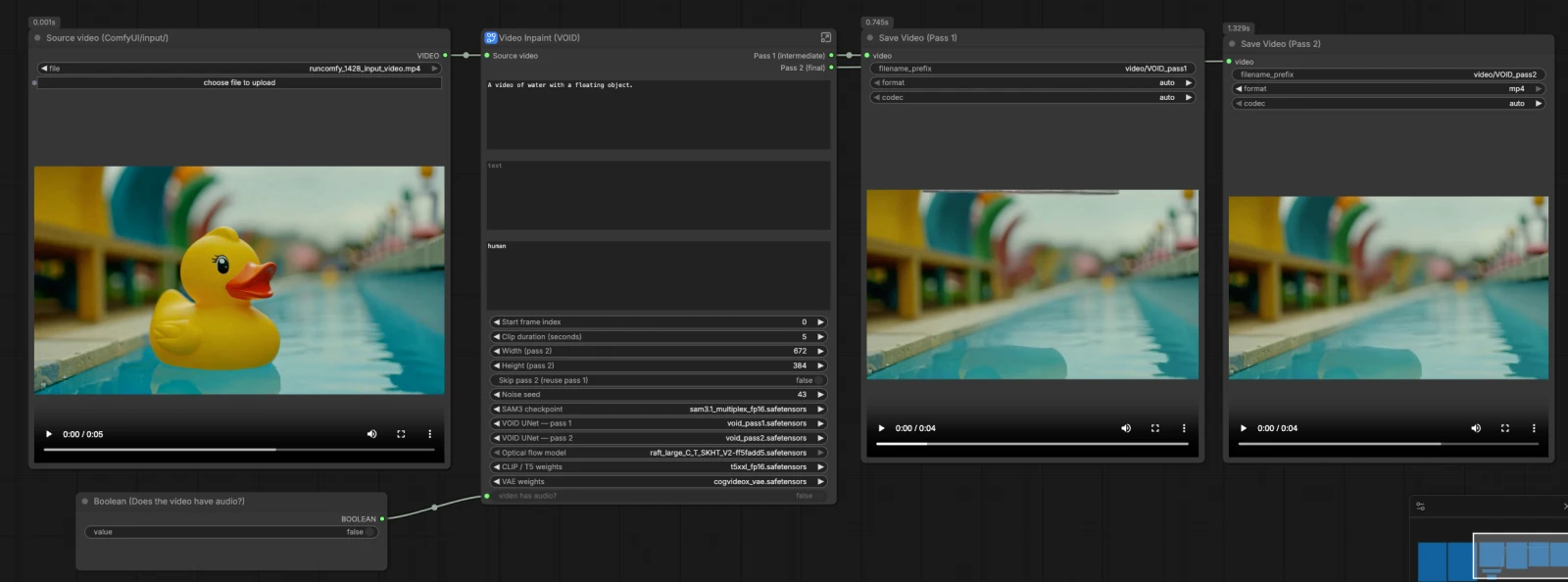
この VOID ビデオインペイント ComfyUI ワークフローは、クリップからオブジェクトとその視覚的インタラクションを時間的な一貫性を持って除去します。Meta の SAM3 テキスト駆動型セグメンテーションを組み合わせてマスクを定義し、Netflix VOID の2パスビデオインペイントを使用して時間経過とともに穴を埋め、不要なオブジェクトとその近くの効果がなかったかのように見える結果を生成します。
クリエイター、編集者、および VFX チームは、単一フレームのクリーンアップが動作中にちらついたり壊れたりする場合に、VOID ビデオインペイント ComfyUI に頼ることができます。このワークフローは2つのクリップを出力します:Pass 1 は高速な中間結果として、Pass 2 はより強い時間的安定性を持つ洗練された結果として。ソースビデオ、削除するオブジェクトを説明する短い SAM3 フレーズ、および保持したいシーンを説明するインペイントプロンプトを提供してください。
ComfyUI VOID ビデオインペイント ComfyUI ワークフローの主要モデル#
- VOID: ビデオオブジェクトとインタラクションの削除。時間的推論を伴うビデオオブジェクト削除のための2パス拡散; リファレンス実装とチェックポイントは Netflix により提供されています。GitHub および Hugging Face
- Segment Anything Model 3.1 Multiplex (SAM3.1)。オブジェクトマスクを生成するために使用されるテキストおよびプロンプト可能な画像セグメンテーション。Hugging Face
- RAFT: Recurrent All-Pairs Field Transforms。Pass 1 から Pass 2 までノイズをワープするために使用される光フロー。arXiv および VOID モデルパックのウェイトは Hugging Face にあります。
- CogVideoX VAE。インペイント中のビデオフレームのエンコードとデコードのための潜在コーデック。Hugging Face
- T5-XXL テキストエンコーダー (fp16)。ポジティブおよびネガティブプロンプトを拡散モデルの条件に変換する言語バックボーン。Hugging Face
ComfyUI VOID ビデオインペイント ComfyUI ワークフローの使用方法#
この VOID ビデオインペイント ComfyUI グラフは明確なパスに従います:モデルとソースクリップをロードし、SAM3 を使用してオブジェクトマスクを作成し、プロンプトとマスクから共有条件を構築し、Pass 1 を実行してコンテンツを確立し、次にワープされたノイズで Pass 2 を実行して安定した動きを実現します。オーディオは処理されたセグメントに一致するようにオプションでトリムされます。ワークフローは Pass 1 と Pass 2 の両方のビデオを保存するため、比較したり迅速に移動したりできます。
モデル#
このグループは、VOID ビデオインペイント ComfyUI に必要なすべてのコンポーネントをロードします。CLIPLoader (#2) は T5-XXL テキストエンコーダーを、VAELoader (#3) は CogVideoX VAE を提供します。UNETLoader (#144) は Pass 1 のための VOID UNet を初期化し、UNETLoader (#143) は Pass 2 のための VOID UNet をセットアップします。OpticalFlowLoader (#142) は後でパス間のノイズワープを駆動する RAFT モデルをロードします。
入力ビデオ (ComfyUI/input/ にファイルを配置)#
Source video (ComfyUI/input/) ローダーをクリップに向けて、次に GetVideoComponents (#166) がそれをフレーム、オーディオ、fps に分割します。ImageFromBatch (#145) はマスクをプレビューするための代表的なフレームを選択します。GetImageSize (#43) と単純な数学ノードはクリップの長さと一貫したスライスのためのインデックスを計算します。開始フレームと期間を提供して、処理したいセクションにターゲットを絞ります。
マスク作成#
Image Segmentation (SAM3) サブグラフは、VOID ビデオインペイント ComfyUI のためのフレームごとのオブジェクトマスクを生成します。SAM3_Detect (#75) は選択されたフレーム上でオブジェクトをセグメント化するためにあなたの SAM3 テキストプロンプトを使用し、CLIPTextEncode (#78) がフレーズをエンコードします。マスクは MaskPreview (#132) でプレビューされ、カバレッジを確認し、必要に応じて表現を洗練できます。「テーブル上の赤いカップ」や「青いジャケットを着た人」のようなクリーンで具体的なフレーズは、SAM3 が適切な対象を特定するのに役立ちます。
共有: テキスト & マスクの条件付け#
Positive Prompt (CLIPTextEncode (#6)) は、除去後にシーンがどのように見えるべきかを記述する必要があります。除去の行為を記述しないでください。Negative Prompt (CLIPTextEncode (#7)) は、望まないアーティファクトをオプションで挙げます。VOIDInpaintConditioning (#10) は、プロンプト、VAE、受信フレーム、SAM3 マスク、およびターゲット寸法を融合して、両方のパスで使用される潜在条件パックを作成します。これは、オブジェクトがなくなった後に VOID に何を保持し、動きと外観がどのように感じられるべきかを伝えるようなものです。
Pass 1: サンプル (ランダムノイズ → DDIM)#
VOID ビデオインペイント ComfyUI の Pass 1 は、標準のランダムノイズを使用して妥当な埋め合わせを確立します。RandomNoise (#141) がプロセスをシードし、BasicScheduler (#138) と VOIDSampler (#133) が拡散スケジュールを定義し、CFGGuider (#140) がプロンプトをモデルにミックスします。SamplerCustomAdvanced (#49) は潜在クリップを合成し、VAEDecode (#45) がそれをフレームに戻します。CreateVideo (#46) はオーディオをオプションで添付し、洗練前に検査できる中間の Pass 1 ビデオを書き込みます。
Pass 2: サンプル (ワープノイズ → DDIM)#
Pass 2 は、Pass 1 のフレームからワープされたノイズを初期化として使用することで時間的安定性を向上させます。VOIDWarpedNoise (#31) は RAFT 光フローを使用して Pass 1 のフレームから時間的に整列されたノイズを作成し、VOIDWarpedNoiseSource (#32) がそれをサンプリングに供給します。CFGGuider (#136)、BasicScheduler (#137)、および VOIDSampler (#134) が2番目のサンプラーをセットアップし、SamplerCustomAdvanced (#35) がインペイントされたコンテンツを洗練します。VAEDecode (#36) が最終フレームを生成します。スキップをトグルすると、ComfySwitchNode (#150) が Pass 1 フレームを直接出力にルーティングして迅速なプレビューを行います。
出力ビデオサイズ#
幅と高さのコントロールは、Pass 2 の潜在解像度とワープノイズジェネレーターを駆動します。これらの値は、VOID ビデオインペイント ComfyUI におけるシャープネス、安定性、および計算負荷に影響を与えます。コンテンツの目標と利用可能なメモリに一致する寸法を選択してください。同じサイズがパイプライン全体で一貫して使用され、動きとマスクが整列します。
Pass 2 をスキップ#
迅速な確認が必要な場合は、スキップコントロールを使用して VOID ビデオインペイント ComfyUI が Pass 1 を再利用し、Pass 2 を実行しないようにします。ComfySwitchNode (#150) は最終出力のために Pass 1 と Pass 2 の画像を自動的に選択します。これは、マスクの表現やプロンプトを調整している間に粗いカットや繰り返しの際に役立ちます。最終的なレンダリングのために時間的一貫性を確立するために Pass 2 を再度オンにします。
オーディオのトリム#
クリップにオーディオがある場合、VOID ビデオインペイント ComfyUI はそれをトリムして再アタッチし、出力の長さが処理されたセグメントに一致するようにします。TrimAudioDuration (#158) は音声を同期させ、ComfySwitchNode (#174) は無音クリップを安全に処理します。GetVideoComponents (#166) からの fps が Pass 1 と Pass 2 の CreateVideo ノードの両方を駆動し、ドリフトを回避します。"video has audio?" スイッチを正しく設定して期待通りの結果を得てください。
ComfyUI VOID ビデオインペイント ComfyUI ワークフローの主要ノード#
SAM3_Detect (#75)#
短い SAM3 フレーズからオブジェクトマスクを生成します。マスクが緩すぎたりきつすぎたりする場合は、ターゲットとそのコンテキストをよりよく説明するように表現を洗練してください。また、必要に応じてエッジをシャープにするための内部洗練コントロールを調整することもできます。強力なマスクは、後のインペイントをより安定させます。
VOIDInpaintConditioning (#10)#
ポジティブプロンプト、ネガティブプロンプト、VAE、フレーム、SAM3 マスクから条件付けバンドルを構築します。ポジティブプロンプトは、残るシーンを記述する必要があります。「X を除去する」のような表現は避けてください。ネガティブプロンプトは、一貫したアーティファクトが現れる場合にのみ使用してください。生成された潜在および条件信号は両方のパスに供給されます。
SamplerCustomAdvanced (#49) - Pass 1#
ランダムノイズで最初のパスのために VOID サンプリングを実行します。ノイズシードは再現性を制御します。異なるフィルパターンを望む場合は変更してください。サンプラーとスケジューラーを Pass 1 UNet とペアにしておいてください。このパスを検査して、構成と基本的な動きを確認してください。
VOIDWarpedNoise (#31)#
Pass 1 のフレームから計算された RAFT 光フローを使用して時間的に整列されたノイズを作成します。これにより、Pass 2 に動きの手がかりが保存され、ちらつきが減少します。動きが不安定に見える場合は、マスクの品質を再検討するか、Pass 1 で異なるシードを試して、より良いベースを生成してください。
SamplerCustomAdvanced (#35) - Pass 2#
ワープノイズから始めて、インペイントされた領域を洗練します。テクスチャを固定し、時間を超えて細部を安定させるために使用します。出力がすでに安定している場合は、時間を節約するために Pass 2 をスキップできます。それ以外の場合は、最終的な配信のために有効にしておいてください。
ComfySwitchNode (#150) - スキップコントロール#
最終出力のために Pass 1 と Pass 2 フレームを切り替えます。これを使用して品質を A/B チェックしたり、プロンプトや SAM3 マスクを調整している間に繰り返しを迅速にすることができます。最終的な VOID ビデオインペイント ComfyUI の結果を得るためにオフにしてください。
オプションの追加機能#
- 除去後に見たい世界のためにポジティブプロンプトを書いてください。例えば「空のキッチンカウンター、日中、清潔なタイル」のように、「カップを取り除く」とは書かないでください。
- SAM3 フレーズを具体的に保ち、「青いジャケットを着た人」や「テーブル上の赤いカップ」のようにし、小さな編集の後にマスクプレビューでカバレッジを確認してください。
- 開始フレームと期間を使用して、処理を関連するセクションに制限します。長いクリップはセグメントで処理するのが最適です。
- 草稿のために Pass 2 をスキップし、最終的な安定化のために VOID ビデオインペイント ComfyUI で有効にします。
- 幅と高さを調整して、詳細と GPU メモリのバランスを取ります。高解像度はシャープに見えますが、計算コストが増加します。
謝辞#
このワークフローは、以下の作品とリソースを実装し、構築しています。Netflix による VOID モデル、Comfy-Org による VOID と SAM3.1 モデルファイル、RunComfy による Cloud Save ワークフローソースの貢献とメンテナンスに感謝します。権威ある詳細については、以下にリンクされたオリジナルのドキュメントとリポジトリを参照してください。
リソース#
- Netflix/void-model
- GitHub: [netflix/void-model](https://github.com/netflix/json
- Comfy-Org/void-model
- Hugging Face: Comfy-Org/void-model
- Comfy-Org/sam3.1
- Hugging Face: Comfy-Org/sam3.1
- RunComfy/Cloud Save source
- Docs / Release Notes: Cloud Save source
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.
