
Qwen Image LoRA 推論: トレーニングに一致した AI Toolkit 推論を ComfyUI で#
Qwen Image LoRA 推論は、AI Toolkit でトレーニングされた LoRA を Qwen Image に ComfyUI で適用するための、プロダクション準備が整った RunComfy ワークフローです。それは、RC Qwen Image (RCQwenImage) に中心を置いています。これは、Qwen Image 専用の推論パイプラインを実行し、lora_path と lora_scale を介してアダプターを注入する、RunComfy が作成したオープンソースのカスタムノードです(source)。
なぜ Qwen Image LoRA 推論が ComfyUI で異なるように見えるのか#
AI Toolkit プレビューは、Qwen Image 独自の条件付けとガイダンス実装を備えたモデル特有の推論パイプラインによって生成されます。Qwen Image サンプリングを一般的な ComfyUI グラフとして再構築すると、パイプラインのデフォルト(および LoRA が適用される正確なルート)がしばしば変更されるため、同じプロンプト/ステップ/シードでもドリフトすることがあります。出力が一致しない場合、それは通常、パイプラインレベルの不一致であり、「間違ったつまみ」ではありません。
RCQwenImage カスタムノードが行うこと#
RCQwenImage は、Qwen Image 推論をプレビューに整合したパイプラインにラップし、そのパイプライン内で AI Toolkit LoRA を lora_path / lora_scale を介して適用するため、このモデルファミリーのサンプリング動作を一貫して保ちます。参照実装: `src/pipelines/qwen_image.py`。
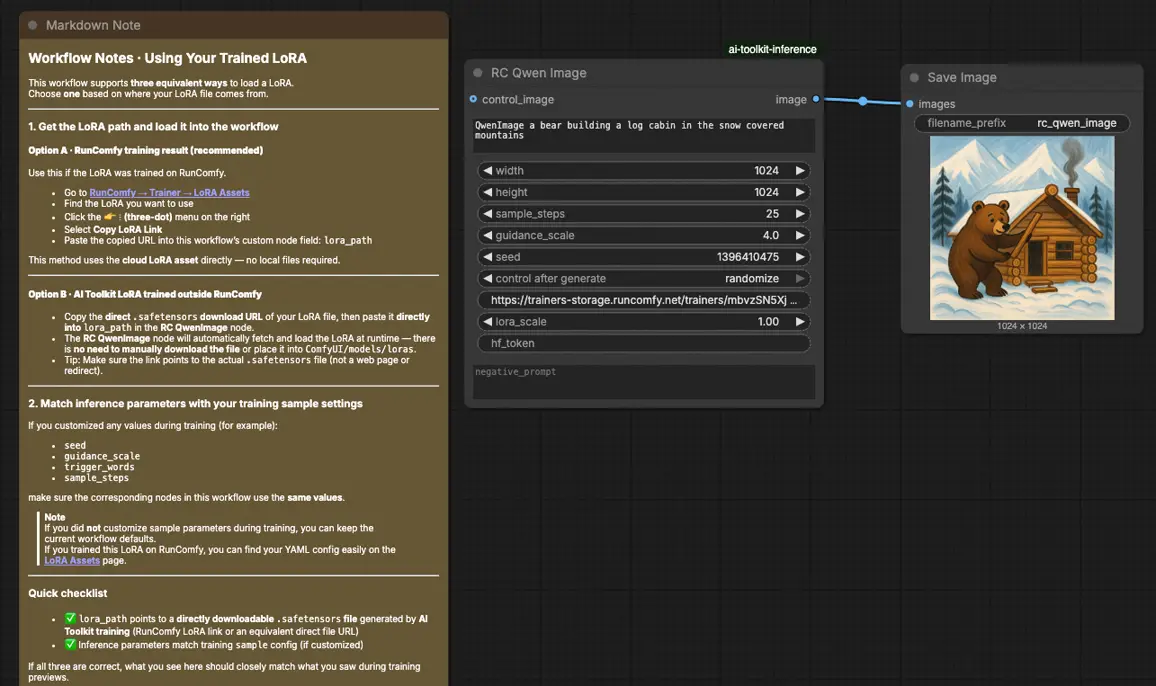
Qwen Image LoRA 推論ワークフローの使用方法#
ステップ 1: ワークフローを開く#
ComfyUI でクラウド保存されたワークフローを開きます
ステップ 2: LoRA をインポートする(2 つのオプション)#
- オプション A(RunComfy トレーニング結果): RunComfy → Trainer → LoRA Assets → LoRA を見つける → ⋮ → LoRA リンクをコピー

- オプション B(RunComfy 以外でトレーニングされた AI Toolkit LoRA): LoRA の直接
.safetensorsダウンロードリンクをコピーして、その URL をlora_pathに貼り付けます(ComfyUI/models/lorasにダウンロードする必要はありません)
ステップ 3: Qwen Image LoRA 推論用の RCQwenImage カスタムノードを設定する#
ノードの残りのパラメータを設定します(これらは、結果を比較するときに AI Toolkit プレビューサンプリングに使用したものと一致する必要があります):
prompt: テキストプロンプト(トレーニング中に使用したトリガートークンを含める場合があります)negative_prompt: オプション; トレーニングプレビューで否定を使用しなかった場合は空のままにしますwidth/height: 出力解像度(Qwen Image の場合は 32 の倍数を推奨)sample_steps: Qwen Image パイプラインで使用される推論ステップの数guidance_scale: ガイダンスの強さ(Qwen Image は「真の CFG」スケールを使用します; 調整前にプレビュー値を反映することから始めます)seed: 再現性のための固定シード; ベースラインを検証した後にのみ変更しますlora_scale: LoRA の強さ(プレビューの強さから始め、小刻みに調整します)
トレーニングの整合性メモ: トレーニングサンプル設定を調整した場合は、AI Toolkit トレーニング YAML を開いて width、height、sample_steps、guidance_scale、および seed を反映します。RunComfy でトレーニングした場合は、Trainer → LoRA Assets → Config を使用して、同じプレビュー値を RCQwenImage にコピーします。

ステップ 4: Qwen Image LoRA 推論を実行する#
ワークフローをキューに入れ、実行します。SaveImage ノードは生成された画像を標準の ComfyUI 出力ディレクトリに書き込みます。
Qwen Image LoRA 推論のトラブルシューティング#
Ostris AI Toolkit で Qwen Image LoRA をトレーニングした後で ComfyUI で実行しようとする際に直面する多くの問題は、パイプライン + LoRA 注入の不一致 に帰着します。
RunComfy の RC Qwen Image (RCQwenImage) カスタムノードは、AI Toolkit プレビューサンプリングと整合するように推論 パイプラインに整合 するために構築されており、Qwen Image 専用の推論パイプライン(一般的なサンプラーグラフではない)を実行し、lora_path / lora_scale を介してアダプターを そのパイプライン内で 注入します。
(1)Qwen-Image Loras が ComfyUI で機能しない#
なぜこれが起こるのか
これはしばしば次のように報告されます:
- 多くの
lora key not loaded警告、または - LoRA は「実行される」が、AI Toolkit サンプリングのように出力が変化しない。
実際には、ComfyUI が最新の Qwen LoRA キーマッピングを含むビルドにまだない、または ワークフローで使用される Qwen Image モジュール名と一致しない一般的なパスを通じて LoRA をロードしている ことからしばしば発生します。
どのように修正するか
- ComfyUI を「nightly / development」チャンネルに切り替え、更新 し、同じワークフローを再実行します。複数のユーザーがこれにより
lora key not loadedスパムが削除され、Qwen-Image LoRAs が正しく適用されると報告しています。 - RCQwenImage を使用し、
lora_path/lora_scale経由でのみ LoRA を渡します(その上に余分な LoRA ローダーノードを積み重ねないでください)。RCQwenImage は、AI Toolkit スタイルの推論と一貫した パイプラインレベルの LoRA 注入ポイント を維持します。 - AI Toolkit プレビューと比較する際には、
width、height、sample_steps、guidance_scale、seed、およびlora_scaleのプレビュースケール値を正確に反映してください。
(2)Qwen 画像生成と Qwen lighting 8 ステップ LoRA を使用した出力品質の問題#
なぜこれが起こるのか
ComfyUI を更新した後で、Qwen Image の出力が歪んだり「奇妙」になったりし、コンソールに Lightning 8 ステップ LoRA の lora key not loaded と表示されると報告されます。これは速度/品質の LoRA が 実際には適用されていない ことを意味しますが、画像はまだ生成されます。
どのように修正するか(ユーザー検証済み + トレーニングに一致)
- ComfyUI nightly に切り替えて更新 します。これは、Qwen-Image Lightning LoRAs における
lora key not loadedの最も一貫した修正として報告されています。 - ネイティブ Comfy ワークフローを使用している場合、ユーザーは最新の nightly でモデルローダーとモデルサンプリングノードの間に
LoraLoaderModelOnlyを挿入することで成功を報告しています。 - トレーニングプレビューの整合性(AI Toolkit)の場合、まず RCQwenImage を通じて検証し(パイプラインに整合)、ベースラインが一致した後にのみ
lora_scaleを調整します。
(3)Qwen Image キャラクター LoRA がトレーニングサンプルと異なる#
なぜこれが起こるのか
一般的な報告は: AI Toolkit トレーニングサンプルは問題ないが、ComfyUI では LoRA が「ほとんど影響を与えない」です。Qwen Image では、通常次のいずれかを意味します:
- LoRA が実際に適用されていない(しばしば
lora key not loaded/ 古い Qwen サポートを伴う)、または - LoRA は Qwen Image がモジュールをパッチすることを期待する方法と一致しないグラフ/ローダールートを介してロードされている。
どのように修正するか(ユーザー検証済み + トレーニングに一致)
- RCQwenImage を介して LoRA を検証します(単一ノード、パイプラインに整合した注入を
lora_path/lora_scale経由で行います)。ここで LoRA 効果が現れるが手動グラフでは現れない場合、パイプライン/ローダーの不一致 が確認され、トレーニングの失敗ではないことがわかります。 - AI Toolkit プレビューサンプルに一致させる際には、解像度/ステップ/ガイダンス/シードを診断中に変更しないでください。まずプレビュースケール値を一致させ、次に
lora_scaleを小刻みに調整します。
今すぐ Qwen Image LoRA 推論を実行する#
RunComfy ワークフローを開き、lora_path を設定し、RCQwenImage を実行して、Qwen Image LoRA 推論を ComfyUI で AI Toolkit トレーニングプレビューに整合させます。

