
Generate ENTIRE AI WORLDS (Vace Wan 2.1): Cinematic video-to-video worldbuilding with true camera tracking#
Generate ENTIRE AI WORLDS (Vace Wan 2.1) is a production‑ready ComfyUI workflow by Mickmumpitz for transforming live‑action footage into new environments while keeping the original camera motion. It swaps backgrounds, preserves perspective and scale, and composites a masked actor into fully regenerated worlds driven by text and reference imagery.
Built on the Wan 2.1 VACE stack, this workflow is ideal for filmmakers, VFX artists, and creators who need fast previz or polished shots. You can direct the scene with prompts, start from an optional reference image, and choose between a high‑speed FP8 pipeline or a low‑VRAM GGUF pipeline. The result is seamless worldbuilding that lets you truly Generate ENTIRE AI WORLDS (Vace Wan 2.1) from everyday plates.
Key models in Comfyui Generate ENTIRE AI WORLDS (Vace Wan 2.1) workflow#
- Wan 2.1 14B text‑to‑video diffusion model. Core generator used to synthesize the new world in a temporally consistent way. Repackaged weights for ComfyUI are available in the Comfy‑Org release on Hugging Face. Comfy‑Org/Wan_2.1_ComfyUI_repackaged
- Wan 2.1 VACE Module 14B. Provides VACE embeddings that bind generation to scene structure, enabling accurate background replacement and camera tracking. Kijai/WanVideo_comfy
- Wan 2.1 VAE. Handles latent encode/decode for video frames. Comfy‑Org/Wan_2.1_ComfyUI_repackaged (VAE split)
- uMT5‑XXL text encoder. Encodes prompts for Wan 2.1’s conditioning space. A packaged encoder compatible with this workflow is provided alongside the Wan 2.1 splits. Comfy‑Org/Wan_2.1_ComfyUI_repackaged (text_encoders)
- Wan 2.1 14B VACE GGUF (quantized UNet). A quantized alternative for lower VRAM GPUs that powers the GGUF path without the full FP8 model. QuantStack/Wan2.1_14B_VACE‑GGUF
- FILM: Frame Interpolation for Large Motion. Optional post process to boost motion smoothness by interpolating additional frames. google‑research/frame‑interpolation
- Optional LightX step‑distill LoRA for Wan 2.1. A speed‑oriented LoRA that pairs well with short step counts while keeping structure and identity. Kijai/WanVideo_comfy (LoRA)
How to use Comfyui Generate ENTIRE AI WORLDS (Vace Wan 2.1) workflow#
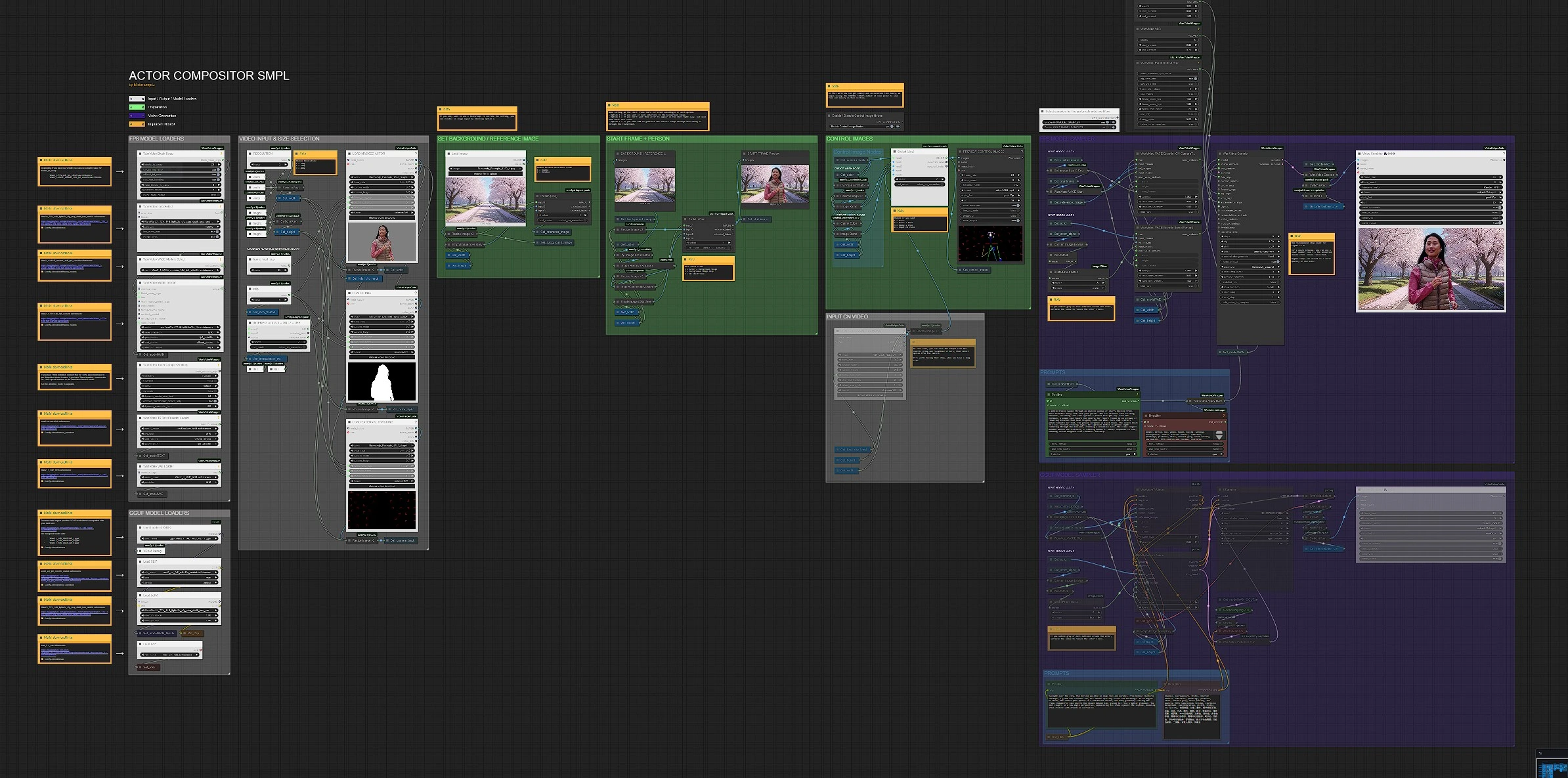
This workflow follows a two‑pass VACE strategy: first, it encodes scene motion from control images to lock camera movement; second, it encodes the actor insert and blends it into the regenerated environment. You can run the FP8 path for maximum speed or the GGUF path for low VRAM. The sections below map to the on‑graph groups so you can operate the entire Generate ENTIRE AI WORLDS (Vace Wan 2.1) pipeline with confidence.
VIDEO INPUT & SIZE SELECTION#
The input area lets you pick the working resolution and basic clip controls. Use the resolution switch to choose a preset (720p, 576p, or 480p), which feeds Set_width (#370) and Set_height (#369) so every stage stays in sync. You can cap the number of frames to keep turnarounds fast and set a small skip if you want to offset the in‑point. For stability and memory, keep sequences within the recommended range; the graph labels call out that 81 frames is a sensible ceiling for most GPUs. These choices apply globally to control images, VACE encodes, and final renders.
Note: The input video can also be generated through another workflow, MASK_AND_TRACK. You can download its workflow file here: workflow.json. After downloading, drag the file into a new workflow tab and run it to obtain the input video.
SET BACKGROUND / REFERENCE IMAGE#
A background plate and an optional reference image guide the visual style. Load a background still, then the graph resizes it to match your working size. If you want a style anchor instead of a hard backplate, enable the reference_image through the selector; this image guides color, composition, and tone without dictating geometry. The reference route is helpful when you want the model to Generate ENTIRE AI WORLDS (Vace Wan 2.1) that echo a specific look, while the text prompt handles the rest. Switch it off when you prefer text‑only control.
START FRAME + PERSON#
Use this section to decide how generation begins. With a ready actor still, Image Remove Background Rembg (mtb) (#1433) pulls a clean mask and ImageCompositeMasked (#1441) places the actor on your chosen background to form a start frame. The Start Frame switch (ImpactSwitch, #1760) offers three modes: composite actor plus background, background only, or no start frame. Start frames help anchor identity and layout; background‑only lets the character “enter” over time; no start frame asks the model to establish both subject and world from text and reference. A live preview block shows what that start looks like before you commit downstream.
CONTROL IMAGES#
Control images lock the camera’s motion so perspective and parallax feel real. Feed a camera‑track video into the group; the graph can derive OpenPose and Canny layers, then blend them to create a strong structure signal. The Control Image Nodes switch (ImpactSwitch, #1032) lets you pick Track only, Track+Pose, Canny+Pose, or an externally prepared control video. Review the stack with the preview combine to ensure silhouettes and edges read clearly. For long sequences, you can save and later re‑load this control video to avoid recomputing; that’s especially useful when you iterate prompts or masks while continuing to Generate ENTIRE AI WORLDS (Vace Wan 2.1).
INPUT CN VIDEO#
If you have already exported a “control images” video, drop it here to bypass preprocessing. Select the corresponding option in the control image switch so the rest of the pipeline uses your cached structure. This keeps camera tracking consistent across runs and dramatically reduces iteration time on long takes.
FP8 MODEL LOADERS#
The FP8 branch loads the full Wan 2.1 model stack. WanVideoModelLoader (#4) brings in the T2V 14B backbone and the VACE module, plus an optional LightX LoRA for fast, coherent sampling. WanVideoVAELoader (#26) supplies the VAE, and WanVideoBlockSwap (#5) exposes a VRAM‑saving strategy by swapping blocks to device memory as needed. This branch is the fastest way to Generate ENTIRE AI WORLDS (Vace Wan 2.1) when you have the VRAM headroom.
FP8 MODEL SAMPLER#
Prompts are encoded by WanVideoTextEncodeSingle for positive and negative text, then refined through WanVideoApplyNAG to keep phrasing consistent. The first pass, WanVideo VACE Encode (CN‑CameraTrack) (#948), reads the control images to produce motion‑aware embeddings. The second pass, WanVideo VACE Encode (InsertPerson) (#1425), injects the actor using a clean alpha and a mask that you can gently grow or shrink to avoid halos. WanVideoSampler (#2) then renders the sequence, WanVideoDecode (#1) turns latents into frames, and a simple switch chooses between the original frame rate or a FILM‑interpolated stream before the final video combine.
GGUF MODEL LOADERS#
The GGUF branch is designed for low‑VRAM workflows. UnetLoaderGGUF (#1677) loads a quantized Wan 2.1 VACE UNet, CLIPLoader (#1680) provides the text encoder, and a LoRA can be applied with LoraLoader (#2420). A standard ComfyUI VAELoader (#1676) handles decode. This route trades speed for footprint while preserving the same two‑pass VACE logic so you can still Generate ENTIRE AI WORLDS (Vace Wan 2.1) on modest hardware.
GGUF MODEL SAMPLER#
In the quantized path, WanVaceToVideo (#1724) turns VACE embeddings, text conditioning, and your reference into a guided latent. WanVideoNAG and WanVideoEnhanceAVideoKJ help maintain identity and local detail, after which KSampler (#1726) generates the final latent sequence. VAEDecode (#1742) produces frames, an optional FILM step adds temporal smoothness, and the video combine writes the result to disk. Use this path when VRAM is tight or when you need long, steady shots.
PROMPTS#
There are two prompt panels. The FP8 side uses the Wan T5 text encoder, while the GGUF side uses a CLIP conditioning path; both receive positive and negative text. Keep positive prompts cinematic and specific to the world you want, and reserve negative prompts for compression artifacts, over‑saturation, and unwanted foreground clutter. You can mix prompts with a soft reference image to steer color and lighting while still letting the model Generate ENTIRE AI WORLDS (Vace Wan 2.1) that match your intent.
Key nodes in Comfyui Generate ENTIRE AI WORLDS (Vace Wan 2.1) workflow#
WanVideo VACE Encode (CN-CameraTrack)(#948) First‑stage VACE pass that analyzes your control images to lock camera motion. Match width, height, and length with your chosen working size and clip duration so embeddings line up with downstream sampling. If you rely on external control video, keep its frame count consistent to avoid timing drifts. Reference implementation and node behavior follow the WanVideo wrapper. Source: kijai/ComfyUI‑WanVideoWrapperWanVideo VACE Encode (InsertPerson)(#1425) Second‑stage VACE pass that injects the actor using the alpha matte and a cleaned mask. If you see faint edges, adjust the upstream mask shrink/expand (DilateErodeMask, #2391) to pull the matte in slightly. This pass ties the insert to scene motion so scale and parallax remain natural. Source: kijai/ComfyUI‑WanVideoWrapperWanVaceToVideo(#1724 and #1729) Bridges VACE conditioning into the sampler. Set output dimensions to the same working size, and use the control clip’s frame count so trims are not required later. Pair with a single reference image when you want a cohesive look across the shot without over‑constraining layout. Source: kijai/ComfyUI‑WanVideoWrapperWanVideoSampler(#2) FP8 sampler that renders the final sequence from Wan 2.1 using your text embeddings and VACE image embeddings. It supports VRAM‑saving block swap and works well with the LightX step‑distill LoRA for fast, identity‑safe results at low step counts. Sources: kijai/ComfyUI‑WanVideoWrapper, Kijai/WanVideo_comfy (LoRA)KSampler(#1726) GGUF branch sampler. Start with a small number of steps to preserve the actor and reduce over‑sharpening; the LightX LoRA is tuned for this regime. If detail washes out, increase steps modestly or lean into theEnhance A Videoblock to regain micro‑texture without drifting motion. Source: ComfyUI coreFILM VFI(#2019 and #1757) Optional frame interpolation controlled by the interpolation switch. Use it to smooth fast motion or extend duration without re‑rendering. If you notice temporal wobble on thin structures, disable it for those shots or reduce the interpolation factor. Source: google‑research/frame‑interpolation
Optional extras#
- Keep clip lengths manageable; the graph’s guidance of up to roughly 81 frames per run balances stability and memory on common GPUs.
- If you are iterating prompts, save the “control images” video once and switch to the Input CN Video path to avoid recomputing structure.
- To remove faint edges around the subject, nudge the actor mask with
DilateErodeMaskin the insert path until halos disappear. - Low VRAM or long takes: choose the GGUF branch; high VRAM and fast iteration: choose the FP8 branch.
- For start framing, use “Background only” when you want the subject to enter later, or “No start frame” when you want the model to fully establish the scene from text and reference.
With these steps, you can confidently run the workflow end‑to‑end and Generate ENTIRE AI WORLDS (Vace Wan 2.1) that hold up under real camera motion.
Acknowledgements#
This workflow implements and builds upon @mickmumpitz works and resources. We gratefully acknowledge Mickmumpitz's Workflow Tutorial for the instructional workflow, and thank him for his contributions and maintenance. For authoritative details, please refer to the original documentation and repositories linked below.
Resources#
- YouTube/Workflow Tutorial
- Docs / Release Notes from Mickmumpitz Youtube: Workflow Tutorial
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by Mickmumpitz.
