
InfiniteTalk: lip-synced portrait video from a single image in ComfyUI#
This ComfyUI InfiniteTalk workflow creates natural, speech-synchronized portrait videos from a single reference image plus an audio clip. It blends WanVideo 2.1 image-to-video generation with the MultiTalk talking-head model to produce expressive lip motion and stable identity. If you need short social clips, video dubs, or avatar updates, InfiniteTalk turns a still photo into a fluid talking video in minutes.
InfiniteTalk builds on the excellent MultiTalk research by MeiGen-AI. For background and attributions, see the open source project: MeiGen-AI/MultiTalk.
Key models in Comfyui InfiniteTalk workflow#
- MultiTalk (GGUF, InfiniteTalk variant): Drives phoneme-aware facial motion from audio so the mouth and jaw movements track speech naturally. Reference: Kijai/WanVideo_comfy_GGUF › InfiniteTalk and upstream idea: MeiGen-AI/MultiTalk.
- WanVideo 2.1 I2V 14B (GGUF): The primary image-to-video generator that preserves identity, lighting and pose while animating frames. Recommended weights: city96/Wan2.1-I2V-14B-480P-gguf.
- Wan 2.1 VAE (bf16): Decodes latent frames to RGB with minimal color shift; provided in the WanVideo packs above.
- UMT5-XXL text encoder: Interprets your positive and negative prompts to nudge style, scene and motion context. Model family: google/umt5-xxl.
- CLIP Vision: Extracts visual embeddings from your reference image to lock identity and overall appearance.
- Wav2Vec2 (Tencent GameMate): Converts raw speech to robust audio features for MultiTalk embeddings, improving sync and prosody: TencentGameMate/chinese-wav2vec2-base.
Tip: this InfiniteTalk graph is built for GGUF. Keep the InfiniteTalk MultiTalk weights and the WanVideo backbone in GGUF to avoid incompatibilities. Optional fp8/fp16 builds are also available: Kijai/WanVideo_comfy_fp8_scaled and Kijai/WanVideo_comfy.
How to use Comfyui InfiniteTalk workflow#
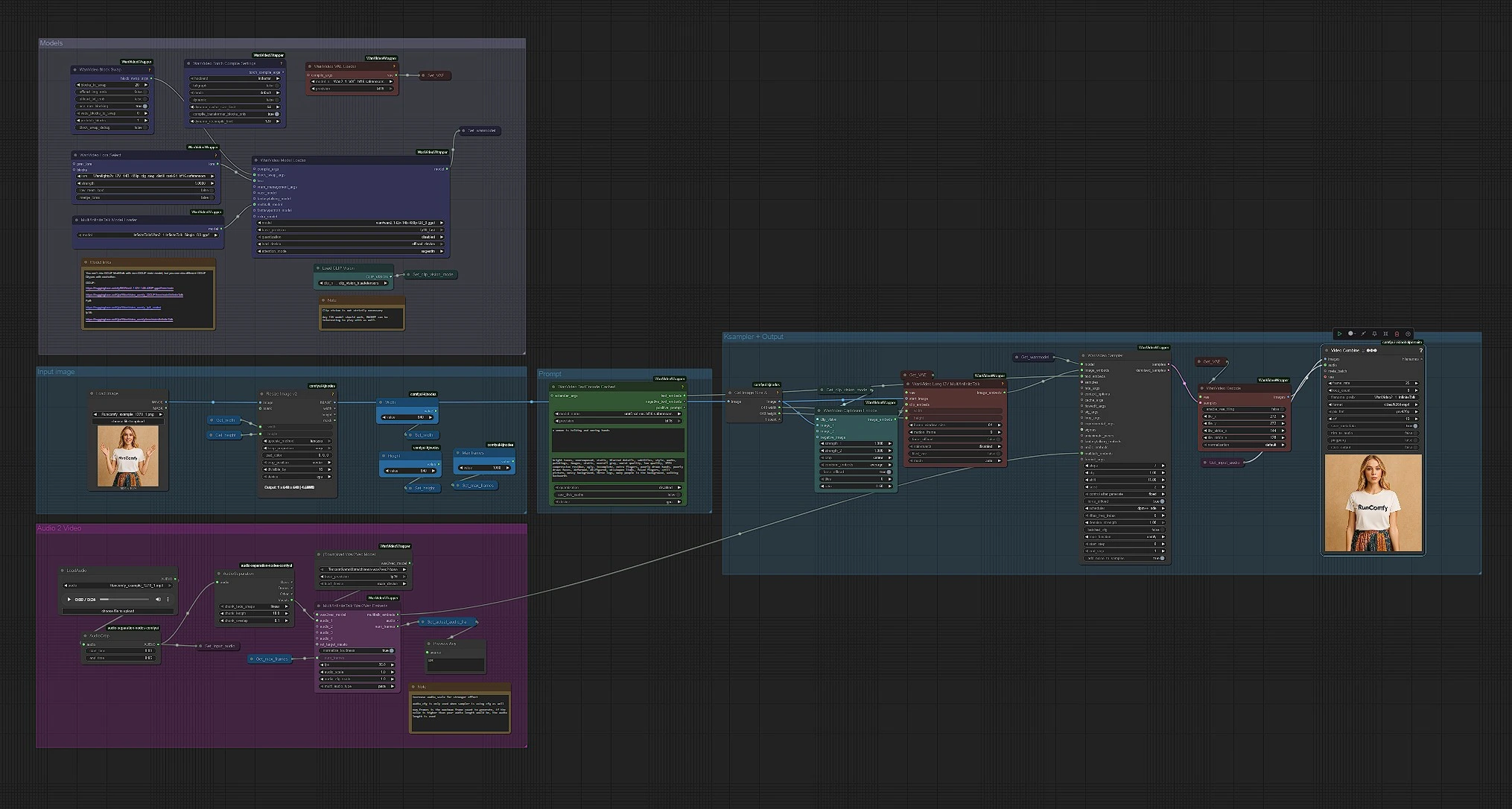
The workflow runs left to right. You provide three things: a clean portrait image, a speech audio file, and a short prompt to steer style. The graph then extracts text, image and audio cues, fuses them into motion-aware video latents, and renders a synced MP4.
Models#
This group loads WanVideo, VAE, MultiTalk, CLIP Vision and the text encoder. WanVideoModelLoader (#122) selects the Wan 2.1 I2V 14B GGUF backbone, while WanVideoVAELoader (#129) prepares the matching VAE. MultiTalkModelLoader (#120) loads the InfiniteTalk variant that powers speech-driven motion. You can optionally attach a Wan LoRA in WanVideoLoraSelect (#13) to bias look and motion. Leave these untouched for a fast first run; they are pre-wired for a 480p pipeline that’s friendly to most GPUs.
Prompt#
WanVideoTextEncodeCached (#241) takes your positive and negative prompts and encodes them with UMT5. Use the positive prompt to describe the subject and scene tone, not identity; identity comes from the reference photo. Keep the negative prompt focused on artifacts you want to avoid (blurs, extra limbs, gray backgrounds). Prompts in InfiniteTalk primarily shape lighting and movement energy while the face stays consistent.
Input image#
CLIPVisionLoader (#238) and WanVideoClipVisionEncode (#237) embed your portrait. Use a sharp, front-facing head-and-shoulders photo with even light. If needed, crop gently so the face has room to move; heavy cropping can destabilize motion. The image embeddings are passed forward to preserve identity and clothing details as the video animates.
Audio to MultiTalk#
Load your speech in LoadAudio (#125); trim it with AudioCrop (#159) for quick previews. DownloadAndLoadWav2VecModel (#137) fetches Wav2Vec2, and MultiTalkWav2VecEmbeds (#194) turns the clip into phoneme-aware motion features. Short 4–8 second cuts are great for iteration; you can run longer takes once you like the look. Clean, dry voice tracks work best; strong background music can confuse lip timing.
Image-to-video, sampling and output#
WanVideoImageToVideoMultiTalk (#192) fuses your image, CLIP Vision embeds and MultiTalk into frame-wise image embeddings sized by Width and Height constants. WanVideoSampler (#128) generates the latent frames using the WanVideo model from Get_wanmodel and your text embeds. WanVideoDecode (#130) converts latents to RGB frames. Finally, VHS_VideoCombine (#131) muxes frames and audio into an MP4 at 25 fps with a balanced quality setting, producing the final InfiniteTalk clip.
Key nodes in Comfyui InfiniteTalk workflow#
WanVideoImageToVideoMultiTalk (#192)#
This node is the heart of InfiniteTalk: it conditions the talking-head animation by merging the start image, CLIP Vision features and MultiTalk guidance at your target resolution. Adjust width and height to set aspect; 832×480 is a good default for speed and stability. Use it as the main place to align identity with motion before sampling.
MultiTalkWav2VecEmbeds (#194)#
Converts Wav2Vec2 features into MultiTalk motion embeddings. If lip motion is too subtle, raise its influence (audio scaling) in this stage; if over-exaggerated, lower the influence. Ensure the audio is speech-dominant for reliable phoneme timing.
WanVideoSampler (#128)#
Generates the video latents given image, text and MultiTalk embeddings. For first runs, keep the default scheduler and steps. If you see flicker, increasing total steps or enabling CFG can help; if motion feels too rigid, reduce CFG or sampler strength.
WanVideoTextEncodeCached (#241)#
Encodes positive and negative prompts with UMT5-XXL. Use concise, concrete language like “studio light, soft skin, natural color” and keep negative prompts focused. Remember that prompts refine framing and style, while mouth sync comes from MultiTalk.
Optional extras#
- Keep MultiTalk and WanVideo in the same deployment family (all GGUF or all non-GGUF) to avoid incompatibilities.
- Iterate with a 5–8 second audio crop and the default 480p size; upscale later if needed.
- If identity wobbles, try a cleaner source photo or a milder LoRA. Strong LoRAs can override likeness.
- Record speech in a quiet room and normalize levels; InfiniteTalk tracks phonemes best with clear, dry voice.
Acknowledgements#
The InfiniteTalk workflow represents a major leap in AI-powered video generation by combining ComfyUI’s flexible node system with the MultiTalk AI model. This implementation was made possible thanks to the original research and release by MeiGen-AI, whose MultiTalk project powers InfiniteTalk’s natural speech synchronization. Special thanks also go to the InfiniteTalk project team for providing the source reference, and to the ComfyUI developer community for enabling seamless workflow integration.
Additionally, credit goes to Kijai, who implemented InfiniteTalk into the Wan Video Sampler node, making it easier for creators to produce high-quality talking and singing portraits directly inside ComfyUI. The original resource link for InfiniteTalk is available here: InfiniteTalk Example Workflow.
Together, these contributions make it possible for creators to transform simple portraits into lifelike, continuous talking avatars, unlocking new opportunities for AI-driven storytelling, dubbing, and performance content.