
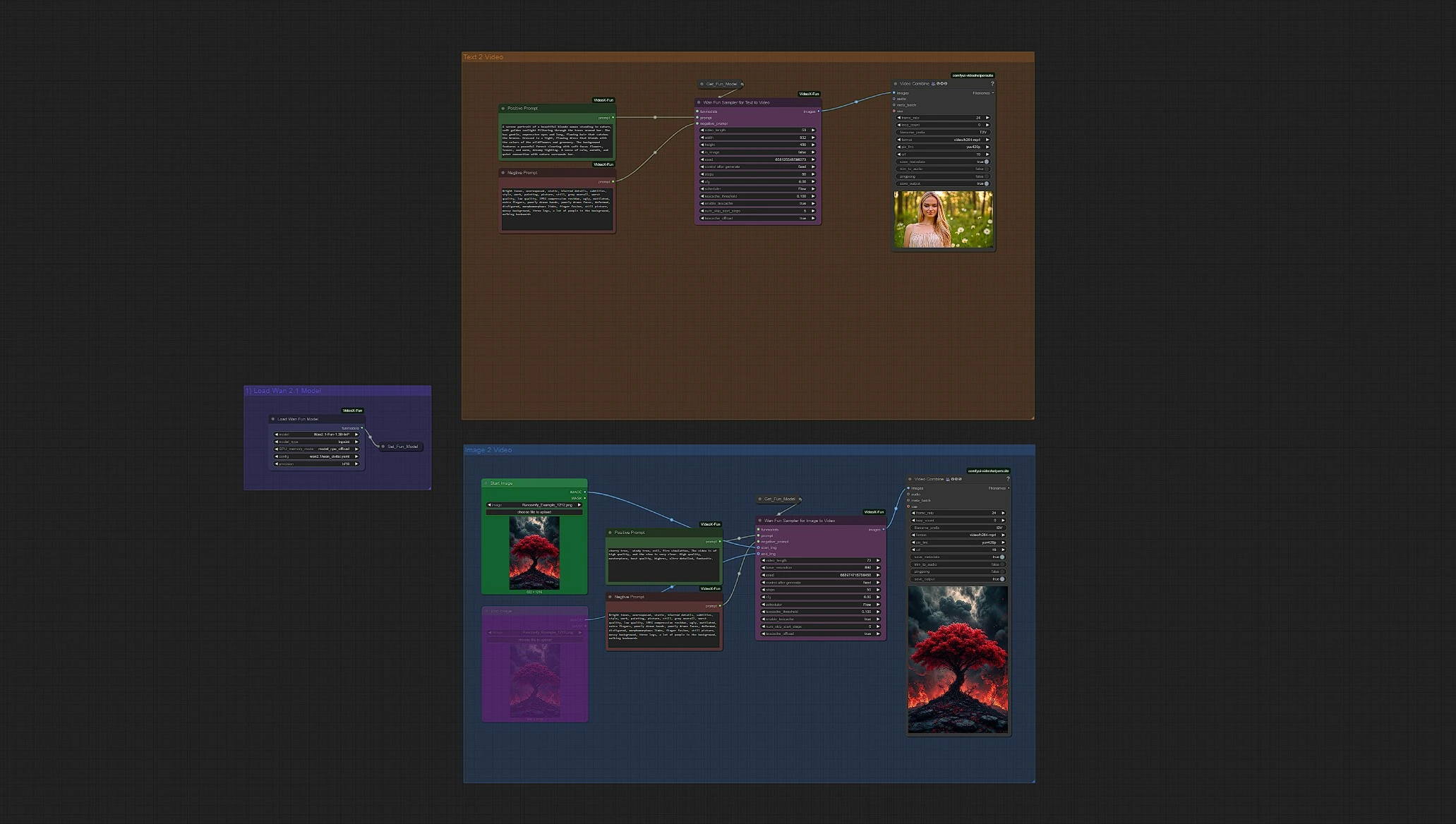
Wan 2.1 Fun | Image-to-Video and Text-to-Video AI Generation#
Wan 2.1 Fun Image-to-Video and Text-to-Video offers a highly versatile AI video generation workflow that brings both static visuals and pure imagination to life. Powered by the Wan 2.1 Fun model family, this workflow lets users animate a single image into a full video or generate entire motion sequences directly from text prompts—no initial footage required.
Whether you're crafting surreal dreamscapes from a few words or turning a concept art piece into a living moment, this Wan 2.1 Fun setup makes it easy to produce coherent, stylized video outputs. With support for smooth transitions, flexible duration settings, and multilingual prompts, Wan 2.1 Fun is perfect for storytellers, digital artists, and creators looking to push visual boundaries with minimal overhead.
Why Use Wan 2.1 Fun Image-to-Video + Text-to-Video?#
The Wan 2.1 Fun Image-to-Video and Text-to-Video workflow provides an easy and expressive way to generate high-quality video from either an image or a simple text prompt:
- Convert a single image into motion with automatic transitions and effects
- Generate videos directly from text prompts, with smart frame prediction
- Includes InP (start/end frame prediction) for controlled visual narratives
- Works with 1.3B and 14B model variants for scalable quality and speed
- Great for creative ideation, storytelling, animated scenes, and cinematic sequences
Whether you're visualizing a scene from scratch or animating a still image, this Wan 2.1 Fun workflow offers fast, accessible, and visually impressive results using Wan 2.1 Fun models.
How to Use the Wan 2.1 Fun Image-to-Video + Text-to-Video?#
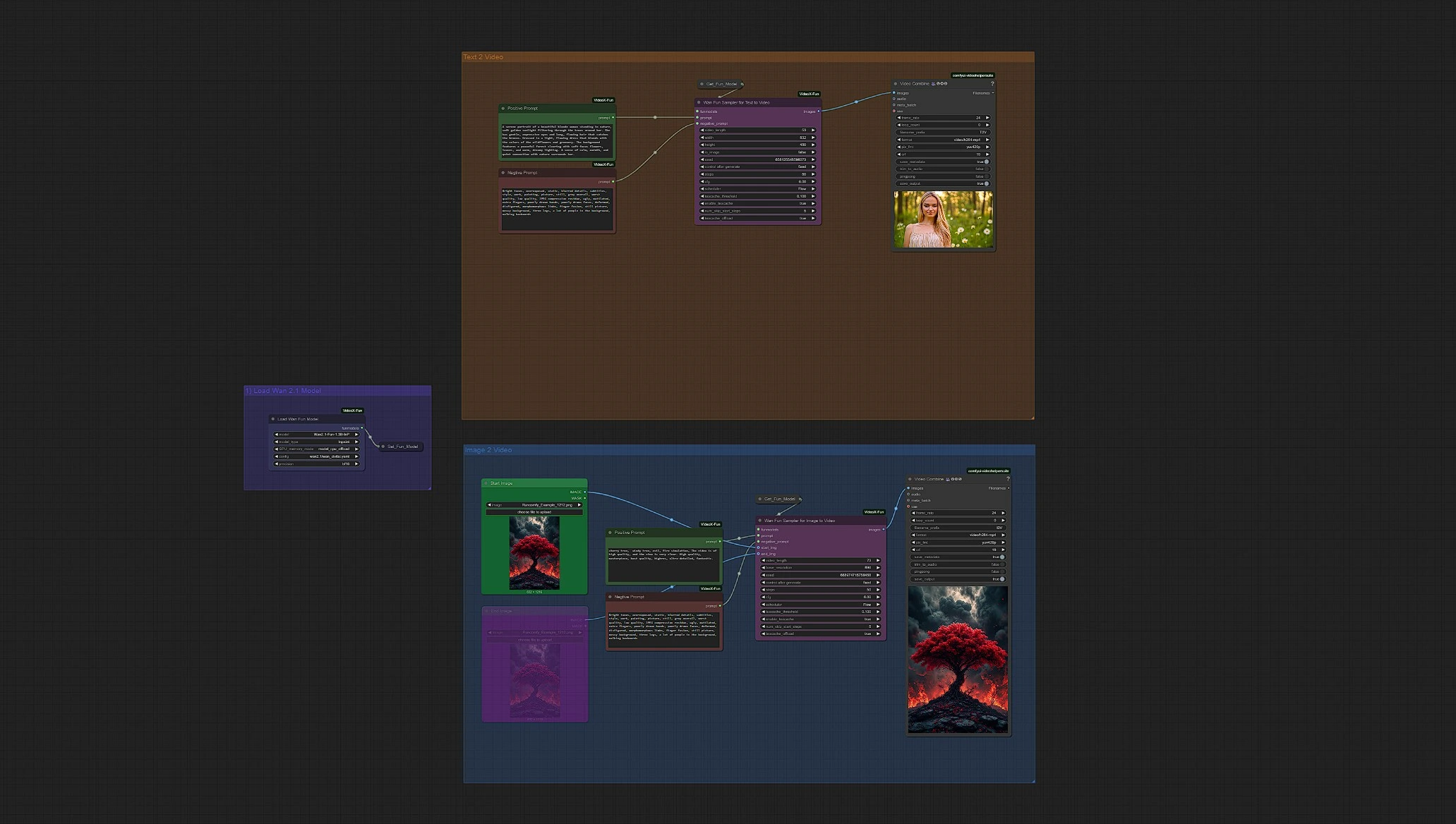
Wan 2.1 Fun Image-to-Video + Text-to-Video Overview#
Load WanFun Model: Load the appropriate Wan 2.1 Fun model variant (1.3B or 14B)Enter Prompts or Upload Image: Supports both text prompts and image inputs using their separate groupSet Inference Settings: Adjust frames, duration, resolution, and motion optionsWan Fun Sampler: Uses WanFun for start/end prediction and temporal coherenceSave Video: Output video is rendered and saved automatically after sampling
Quick Start Steps:#
- Select your
Wan 2.1 Funmodel in the Load Model Group - Enter positive and negative prompts to guide generation
- Choose your input mode:
- Upload an image for Image-to-Video Group
- Or rely on text prompts alone for Text-to-Video Group
- Adjust settings in the
Wan Fun Samplernode (frames, resolution, motion options) - Run the workflow by clicking the
Queue Promptbutton - View and download your final Wan 2.1 Fun video from the Video Save node (
Outputsfolder)
1 - Load WanFun Model#
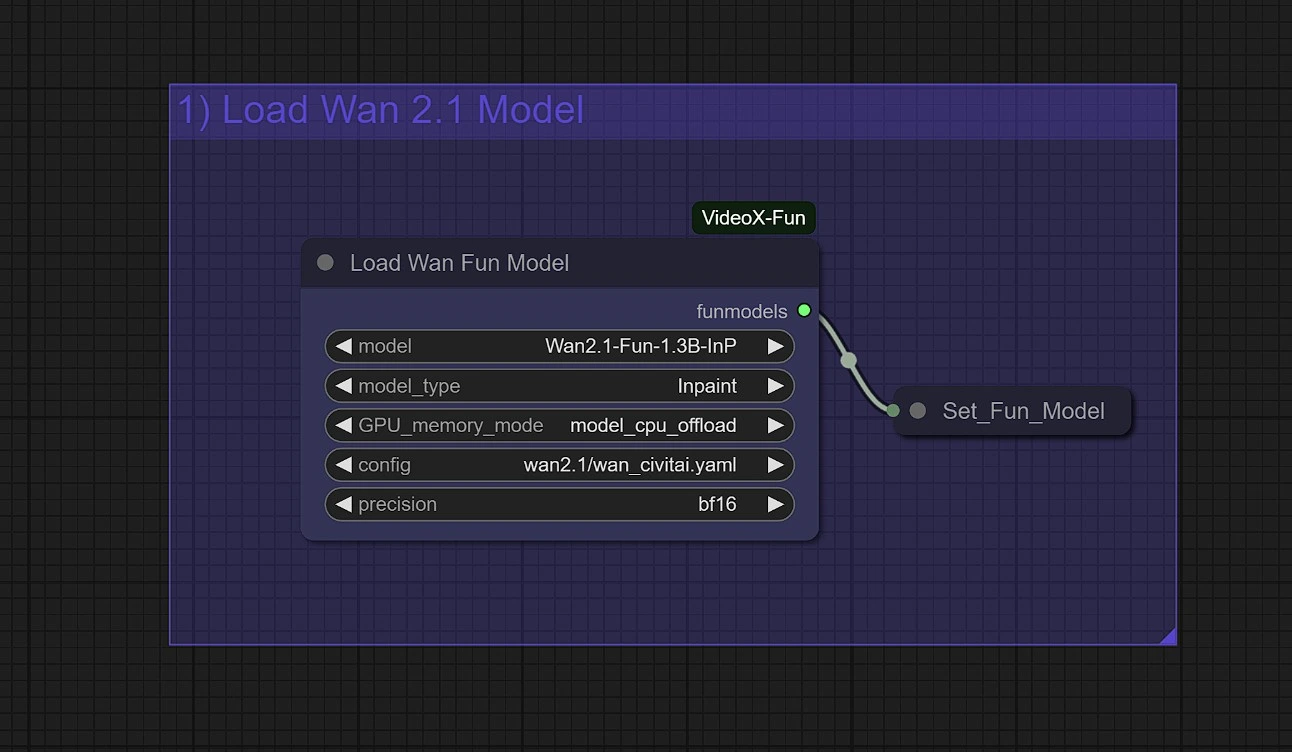
Choose the right model variant for your task:
Wan2.1-Fun-Control (1.3B / 14B): For guided video generation with Depth, Canny, OpenPose, and trajectory controlWan2.1-Fun-InP (1.3B / 14B): For text-to-video with start and end frame prediction
Memory Tips for Wan 2.1 Fun:
- use
model_cpu_offloadfor faster generation with 1.3B Wan 2.1 Fun - use
sequential_cpu_offloadto reduce GPU memory usage with 14B Wan 2.1 Fun
2 - Enter Prompts#
In the appropriate you choose, Image-2-Video group or Text-2-Video Group, enter your positive and negative promopt.
- Positive Prompt:
- drive the motion, detailing, and depth of your video restyle
- using descriptive and artistic language can enhance your final Wan 2.1 Fun output
- Negative Prompt:
- using longer negative prompts such as "Blurring, mutation, deformation, distortion, dark and solid, comics." can increase stability Wan 2.1 Fun
- adding words such as "quiet, solid" can increase dynamism in Wan 2.1 Fun videos
3 - Image 2 Video Group with Wan 2.1 Fun#
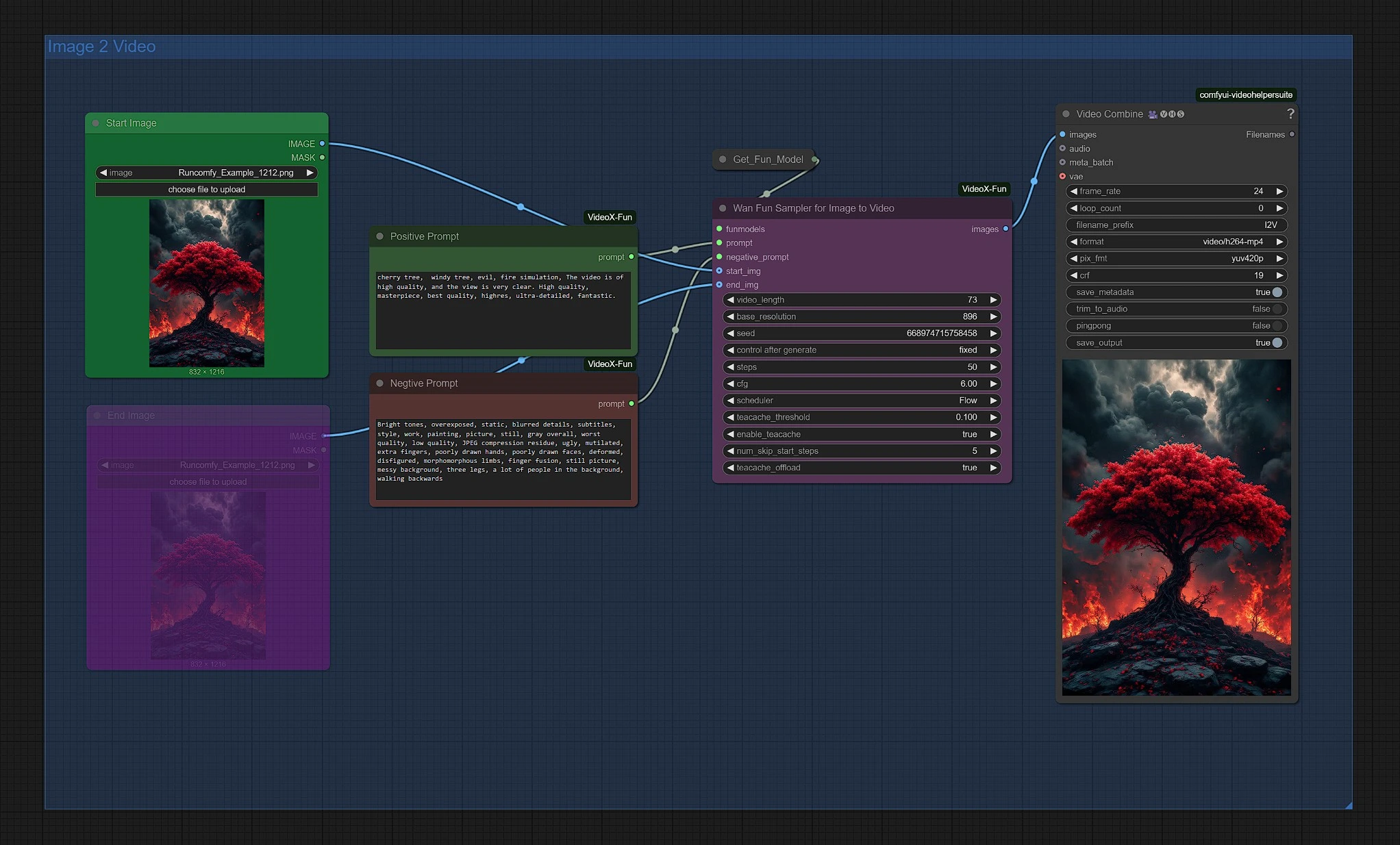
Upload your start image to initiate Wan 2.1 Fun generation. You can adjust the resolution and duration in the Wan Fun Sampler node.
[Optional] Unmute the end image node; this image will serve as the final image, with the in-between rendered through the Wan 2.1 sampler.
Your final Wan 2.1 Fun video is located in the Outputs folder of the Video Save node.
4 - Text 2 Video Group with Wan 2.1 Fun#
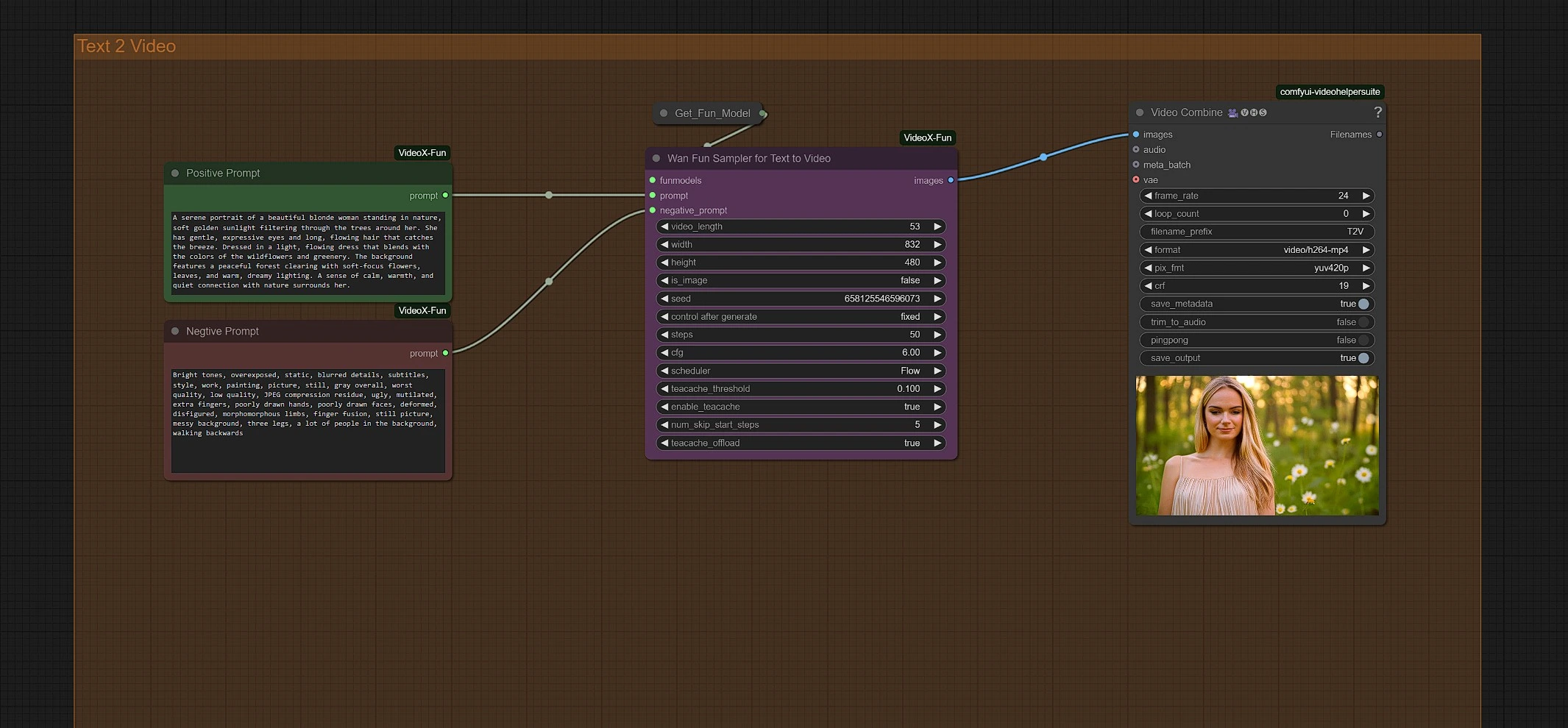
Enter your prompts to initiate generation. You can adjust the resolution and duration in the Wan Fun Sampler node.
Your final Wan 2.1 Fun video is located in the Outputs folder of the Video Save node.
Acknowledgement#
The Wan 2.1 Fun Image-to-Video and Text-to-Video workflow was developed by bubbliiiing and hkunzhe, whose work on the Wan 2.1 Fun model family has made prompt-based video generation more accessible and flexible. Their contributions enable users to turn both still images and pure text into dynamic, stylized videos with minimal setup and maximum creative freedom using Wan 2.1 Fun. We deeply appreciate their innovation and ongoing impact in the AI video generation space.