
Fantasy Portrait: Expression-rich portrait animation in ComfyUI#
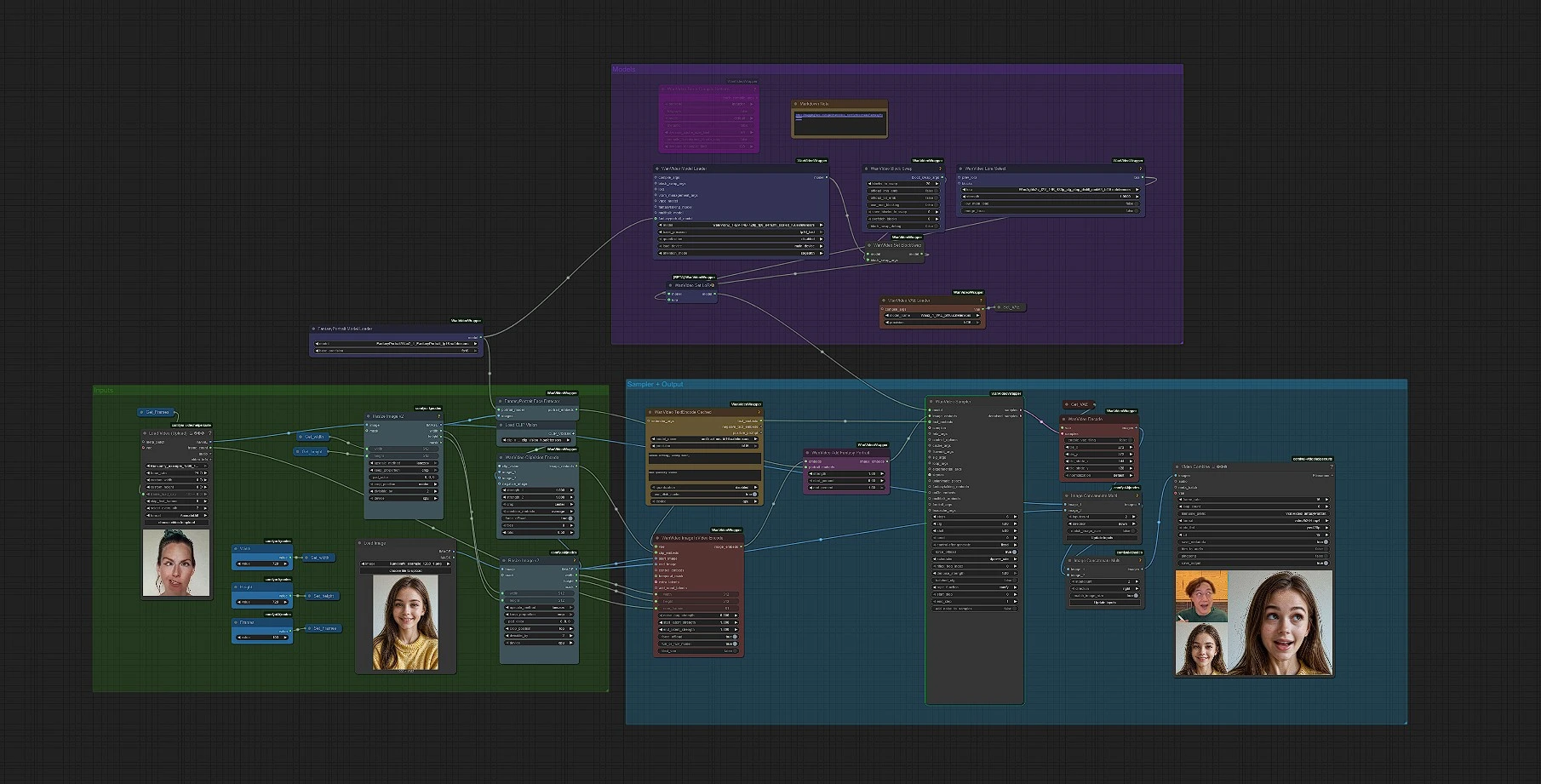
This workflow turns a single still image into a high-fidelity Fantasy Portrait animation. It integrates the Fantasy-AMAP FantasyPortrait model with expression-augmented diffusion transformers and wraps it in a Wan Video 2.1 image-to-video pipeline, so you can generate identity-preserving, emotion-dense talking shots with minimal setup. It is designed for creators who want cinematic Fantasy Portrait motion from a single photo, with clear controls for framing, duration, and style.
The pipeline is fully automated: drop in a portrait, choose your resolution and frame count, optionally add a prompt and LoRA, then render to MP4. Under the hood, the graph detects the face, encodes image and text guidance, fuses Fantasy Portrait identity embeddings into Wan’s I2V conditioner, samples a video, and decodes frames before saving the final clip.
Key models in ComfyUI Fantasy Portrait workflow#
FantasyPortrait (Fantasy-AMAP)
Core identity and expression module. Provides expression-augmented embeddings that preserve subject traits while enabling nuanced facial motion. GitHub | Paper (arXiv)
WanVideo 2.1 I2V (14B, 720p)
Video diffusion backbone used for sampling the animation from the portrait and text/image conditioning. Quantized, Comfy-ready weights are available via Kijai’s model pack. Hugging Face: Kijai/WanVideo_comfy
UMT5-XXL encoder
High-capacity text encoder used for prompt guidance in the video sampler. Example weight: umt5-xxl-enc-bf16.safetensors in Kijai/WanVideo_comfy
Wan 2.1 VAE
Video-optimized VAE for encoding/decoding latents. Example weight: Wan2_1_VAE_bf16.safetensors in Kijai/WanVideo_comfy
How to use ComfyUI Fantasy Portrait workflow#
The workflow runs left to right from inputs to the final video. You’ll mainly set three things up front: image, dimensions, and duration. Then you can refine with a short prompt or a LoRA if you like.
1) Image input and sizing#
Load a single portrait into LoadImage, then it is resized for processing. Two resize stages ensure the image matches your chosen width and height while maintaining composition. Use the Width, Height, and Frames controls to define output size (default 720 × 720) and animation length. This keeps your Fantasy Portrait framing consistent across the pipeline.
2) Face detection and Fantasy Portrait embeddings#
FantasyPortraitModelLoader loads the FantasyPortrait weights, and FantasyPortraitFaceDetector extracts identity- and expression-aware portrait embeddings from your image. The core idea is to separate who the subject is from how they emote, so the final animation preserves identity while allowing expressive motion. You do not need to tune anything here unless you swap models.
3) Image and text conditioning#
For image guidance, CLIPVisionLoader with WanVideoClipVisionEncode produces robust visual features from the portrait. For text guidance, WanVideoTextEncodeCached uses the UMT5-XXL encoder to turn your positive and negative prompts into video-condition embeddings. A short, plain prompt like “natural studio close-up, gentle smile” is often enough for a clean Fantasy Portrait look.
4) I2V encoding with duration control#
VHS_LoadVideo is used as a convenient frame counter. You can leave the placeholder clip or load a reference with your preferred duration; its frame count feeds WanVideoImageToVideoEncode, which turns your start image plus image/text embeddings into I2V conditioning. If you prefer a fixed length, just set Frames directly and ignore the reference loader.
5) Fantasy Portrait fusion#
WanVideoAddFantasyPortrait merges the I2V conditioning with the portrait embeddings from step 2. This is what gives the final Fantasy Portrait animation its strong identity preservation and expressive detail. No extra inputs are required once your image is loaded.
6) LoRA and model setup#
WanVideoModelLoader loads Wan 2.1, then WanVideoLoraSelect optionally applies a lightweight I2V LoRA from the Kijai pack to bias motion or aesthetics without retraining. This is a good place to experiment if you want a slightly more stylized Fantasy Portrait while keeping identity intact.
7) Video sampling and decode#
WanVideoSampler generates latent frames using the fused conditioning. Keep prompts simple, increase steps moderately if you need more detail, and avoid over-constraining with long negatives. WanVideoDecode converts latents back to images, and the workflow concatenates previews before VHS_VideoCombine writes an MP4 (default 16 fps, yuv420p). The output filename prefix is set for convenience.
Key nodes in ComfyUI Fantasy Portrait workflow#
FantasyPortraitModelLoader (#138)#
Loads the FantasyPortrait weights. Swap here if you are testing a newer Fantasy-AMAP release. No tuning is required, but keep the precision consistent with your Wan model and VAE.
FantasyPortraitFaceDetector (#142)#
Extracts portrait embeddings from the resized image. Good results come from well-lit, front-facing photos with minimal occlusion. If motion looks off, verify the input crop and try a cleaner source image.
WanVideoImageToVideoEncode (#151)#
Builds Wan’s I2V conditioning from CLIP image features, your start image, and duration. Adjust width, height, and num_frames to control the render footprint and length. Longer sequences need more VRAM and time.
WanVideoAddFantasyPortrait (#150)#
Fuses Fantasy Portrait identity/expressions into the I2V conditioner. Use this to keep the subject recognizably the same across frames while enabling nuanced expression changes. No parameters typically require adjustment.
WanVideoSampler (#149)#
Generates the video latents. If you want sharper details, increase steps modestly. If motion drifts, reduce prompt complexity or try a different LoRA. Keep guidance coherent rather than verbose.
WanVideoTextEncodeCached (#155)#
Encodes positive/negative prompts with UMT5-XXL. Use short, descriptive phrases. Overly strong negative prompts (for example, heavy “bad quality” stacks) can suppress expression.
Tips#
- Start with square 720 × 720 and 4 to 6 seconds for quick iteration, then scale up if needed.
- Use a clean, front-lit portrait with visible eyes. Avoid heavy occlusions, sunglasses, or extreme angles.
- Keep Fantasy Portrait prompts concise. Describe lighting and mood, not identity.
- Try a gentle LoRA from the Kijai pack if you want a different motion feel without losing identity.
Acknowledgements#
This workflow leverages the Fantasy Portrait model from the Fantasy-AMAP team, integrating Expression-Augmented Diffusion Transformers into ComfyUI for a fully automated, high-quality portrait animation pipeline. Special thanks to kijai for creating and integrating the Wan Video Wrapper node, making it possible to seamlessly run portrait animation in a image-to-video framework. We also acknowledge the broader ComfyUI community for their ongoing contributions to open creative tools.
Links: