
⚠️ 重要なお知らせ:このComfyUI MultiTalk実装は現在、単一人物の生成のみサポートしています。複数人物の会話機能は近日公開予定です。
1. MultiTalkとは?#
MultiTalkは、MeiGen-AIが開発したオーディオ駆動型マルチパーソン会話動画生成のための革新的なフレームワークです。顔の動きのみをアニメーション化する従来のトーキングヘッド生成手法とは異なり、MultiTalk技術はオーディオ入力との完璧なリップシンクを維持しながら、人々が話し、歌い、交流するリアルな動画を生成できます。MultiTalkは静止写真をダイナミックなトーキング動画に変換し、人物に望む通りに話したり歌ったりさせます。
2. MultiTalkの仕組み#
MultiTalkは高度なAI技術を活用してオーディオ信号と視覚情報の両方を理解します。ComfyUI MultiTalk実装は最適な結果のためにMultiTalk + Wan2.1 + Uni3Cを組み合わせています:
オーディオ分析: MultiTalkは強力なオーディオエンコーダー(Wav2Vec)を使用して、リズム、トーン、発音パターンを含むスピーチの微妙なニュアンスを理解します。
視覚的理解: 堅牢なWan2.1動画拡散モデルの上に構築されたMultiTalkは、人体解剖学、表情、体の動きを理解します(t2v/i2v生成についてはWan2.1ワークフローをご覧ください)。
カメラ制御: Uni3C controlnetを備えたMultiTalkは微細なカメラの動きとシーン制御を可能にし、動画をよりダイナミックでプロフェッショナルにします。美しいカメラモーション転送についてはUni3Cワークフローをご確認ください。
完璧な同期: 洗練されたアテンションメカニズムにより、MultiTalkは自然な表情とボディランゲージを維持しながら、リップの動きをオーディオと完璧に同期させます。
指示追従: よりシンプルな手法とは異なり、MultiTalkはオーディオ同期を維持しながら、テキストプロンプトに従ってシーン、ポーズ、全体的な動作を制御できます。
3. ComfyUI MultiTalkの利点#
- 高品質リップシンク: MultiTalkはミリ秒レベルのリップシンク精度を実現し、特に歌唱シナリオで印象的です
- 多用途なコンテンツ制作: MultiTalkはカートゥンキャラクターを含む様々なキャラクタータイプでスピーチと歌唱の両方の生成をサポートします
- 柔軟な解像度: MultiTalkは任意のアスペクト比で480Pまたは720Pの動画を生成します
- 長尺動画サポート: MultiTalkは最大15秒の動画を作成します
- 指示追従: MultiTalkはテキストプロンプトを通じてキャラクターのアクションとシーン設定を制御します
4. ComfyUI MultiTalkワークフローの使い方#
MultiTalkステップバイステップ使用ガイド#
ステップ1:MultiTalk入力の準備
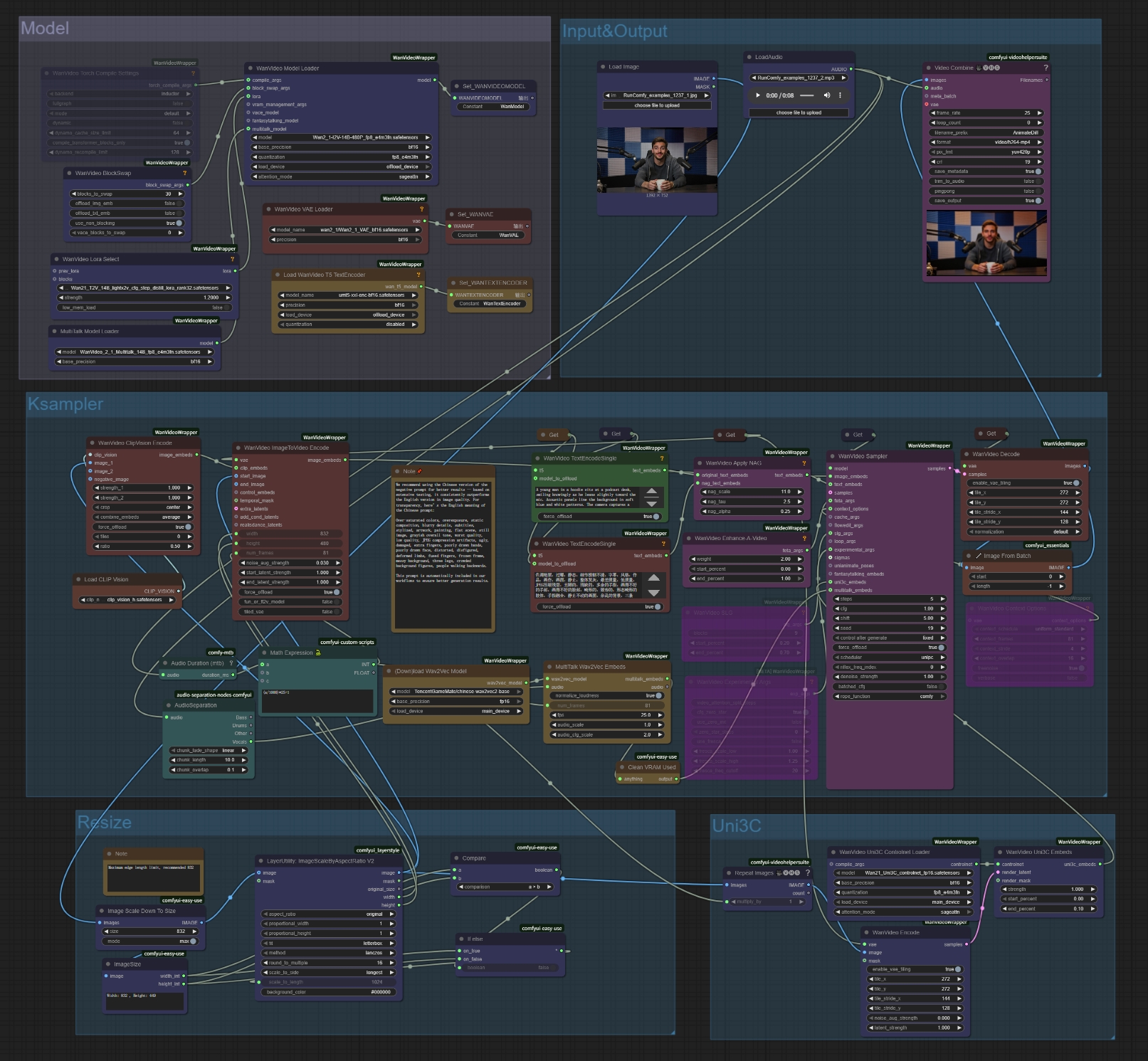
- 参照画像のアップロード: Load Imageノードで「choose file to upload」をクリック
- 最高のMultiTalk結果のために鮮明な正面写真を使用
- 画像は自動的に最適なサイズにリサイズされます(832px推奨)
- オーディオファイルのアップロード: LoadAudioノードで「choose file to upload」をクリック
- MultiTalkは様々なオーディオ形式(WAV、MP3など)をサポート
- クリアな音声/歌唱がMultiTalkで最良の結果をもたらします
- カスタム楽曲の作成には、同期された歌詞付きの高品質音楽を生成するAce-Step音楽生成ワークフローの使用を検討してください。
- テキストプロンプトの記述: MultiTalk生成のためにテキストエンコードノードに希望するシーンを記述
ステップ2:MultiTalk生成設定の構成
- サンプリングステップ: 20-40ステップ(高い = より良いMultiTalk品質、遅い生成)
- Audio Scale: 最適なMultiTalkリップシンクのために1.0を維持
- Embed Cond Scale: バランスの取れたMultiTalkオーディオコンディショニングのために2.0
- カメラ制御: 微細な動きのためにUni3Cを有効化、または静的なMultiTalkショットのために無効化
ステップ3:オプションのMultiTalk拡張
- LoRA加速: 最小限の品質損失でより速いMultiTalk生成のために有効化
- 動画拡張: MultiTalk後処理改善のための拡張ノードの使用
- ネガティブプロンプト: MultiTalk出力で避けたい要素を追加(ぼやけ、歪みなど)
ステップ4:MultiTalkで生成
- プロンプトをキューに入れてMultiTalk生成を待つ
- VRAM使用量を監視(MultiTalkには48GB推奨)
- MultiTalk生成時間:設定とハードウェアに応じて7-15分
5. 謝辞#
オリジナル研究: MultiTalkはMeiGen-AIがこの分野の主要研究者との協力により開発しました。オリジナル論文「Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation」はこの技術の画期的な研究を示しています。
ComfyUI統合: ComfyUI実装はComfyUI-WanVideoWrapperリポジトリを通じてKijaiが提供し、この高度な技術をより広いクリエイティブコミュニティに利用可能にしています。
基盤技術: Wan2.1動画拡散モデルの上に構築され、Wav2Vecのオーディオ処理技術を組み込んでおり、最先端AI研究の総合を表しています。
6. リンクとリソース#
- オリジナル研究: MeiGen-AI MultiTalk Repository
- プロジェクトページ: https://meigen-ai.github.io/multi-talk/
- ComfyUI統合: ComfyUI-WanVideoWrapper