
Hunyuan Video 1.5 ComfyUI workflow: fast text-to-video and image-to-video with 1080p super resolution#
This workflow wraps Hunyuan Video 1.5 in ComfyUI to deliver fast, coherent video generation on consumer GPUs. It supports both text-to-video and image-to-video, then optionally upscales to 1080p using a dedicated latent upsampler and a distilled super-resolution model. Under the hood, Hunyuan Video 1.5 couples a Diffusion Transformer with a 3D causal VAE and a selective sliding-tile attention strategy to balance quality, motion fidelity, and speed.
Creators, product teams, and researchers can use this ComfyUI Hunyuan Video 1.5 workflow to iterate quickly from prompts or a single still image, preview at 720p, and finish with crisp 1080p output when needed.
Key models in Comfyui Hunyuan Video 1.5 workflow#
- HunyuanVideo 1.5 720p Image-to-Video UNet. Produces motion and temporal coherence from a start image. Weights are provided in the Comfy-Org repackage on Hugging Face Comfy-Org/HunyuanVideo_1.5_repackaged.
- HunyuanVideo 1.5 720p Text-to-Video UNet. Generates videos directly from text prompts using the same core architecture, tuned for prompt-first workflows. See the repackage repository above.
- HunyuanVideo 1.5 1080p Super-Resolution UNet (distilled). Refines 720p latents to higher detail while preserving motion and scene structure. Included in the same repackage on Hugging Face.
- HunyuanVideo 1.5 3D VAE. Encodes and decodes video latents for efficient generation and tiled decoding.
- HunyuanVideo 1.5 Latent Upsampler 1080p. Rescales latent sequences to 1920×1080 before SR refinement for speed and memory efficiency.
- Qwen 2.5 VL 7B text encoder and ByT5 Small text encoder. Provide robust instruction-following and tokenization for diverse prompts, repackaged for this workflow in the Hugging Face bundle above. ByT5’s original model card: google/byt5-small.
- SigCLIP Vision (ViT-L/14, 384). Extracts high-quality visual features from the start image to guide image-to-video conditioning: Comfy-Org/sigclip_vision_384.
How to use Comfyui Hunyuan Video 1.5 workflow#
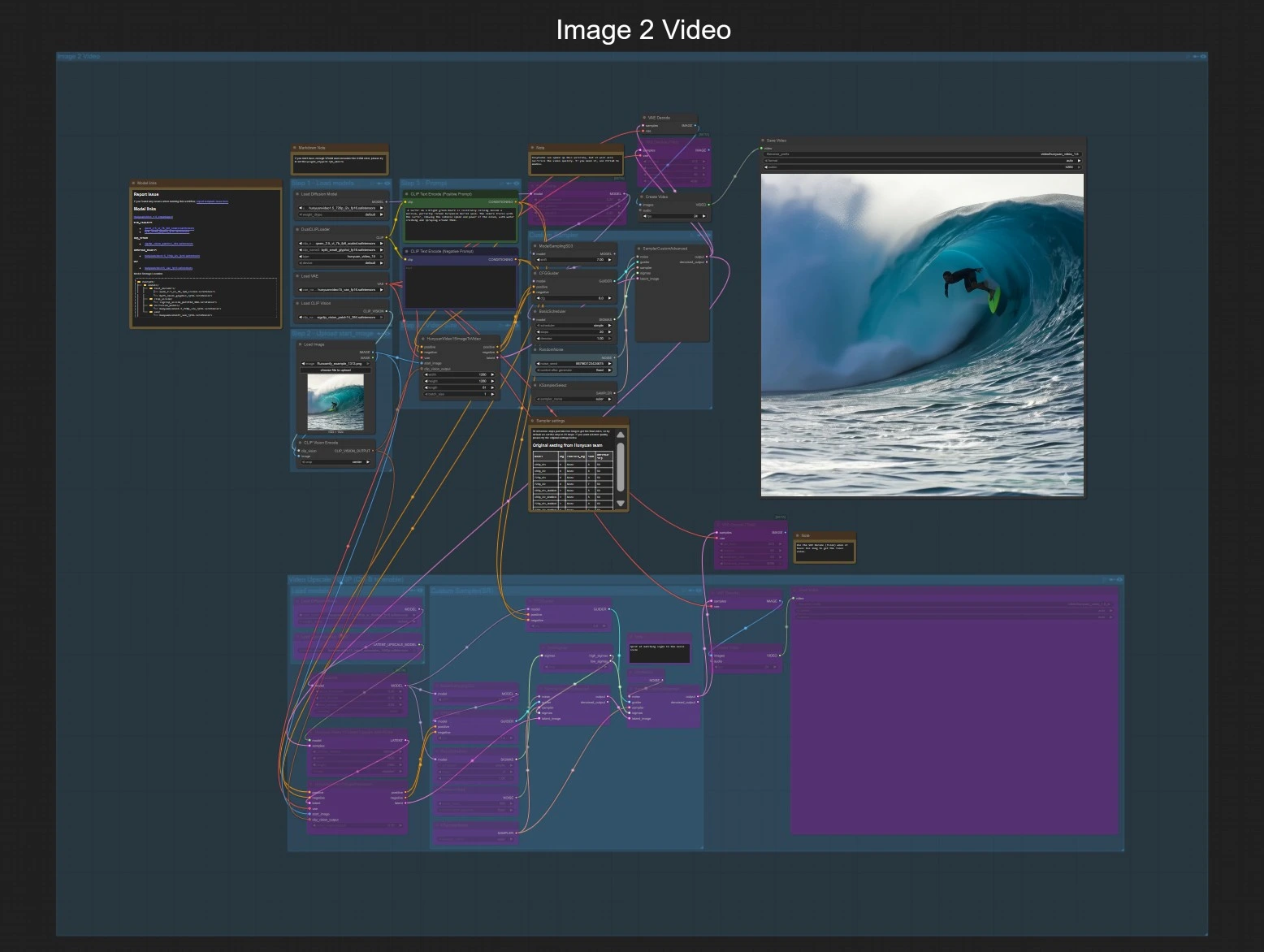
This graph exposes two independent paths that share the same export and optional 1080p finishing stage. Choose either Image to Video or Text to Video, then optionally enable the 1080p group to finalize.
Image to Video#
Step 1 — Load models The loaders bring in the Hunyuan Video 1.5 UNet for image-to-video, the 3D VAE, the dual text encoders, and SigCLIP vision. This primes the workflow to accept a single start image and a prompt. No user action is needed beyond confirming models are available.
Step 2 — Upload start image Provide a clean, well-exposed image in LoadImage (#80). The graph encodes this image with CLIPVisionEncode (#79) so Hunyuan Video 1.5 can anchor motion and style to your reference. Favor images that roughly match your target aspect ratio to reduce cropping or padding.
Step 3 — Prompt Write your description in CLIP Text Encode (Positive Prompt) (#44). Use the negative prompt CLIP Text Encode (Negative Prompt) (#93) to steer away from unwanted artifacts or styles. Keep prompts concise but specific about subject, motion, and camera behavior.
Step 4 — Video size and duration HunyuanVideo15ImageToVideo (#78) sets spatial resolution and the number of frames to synthesize. Longer sequences require more VRAM and time, so start shorter and scale up once you like the motion.
Custom sampling The sampler stack (ModelSamplingSD3 (#130), CFGGuider (#129), BasicScheduler (#126), KSamplerSelect (#128), RandomNoise (#127), SamplerCustomAdvanced (#125)) controls guidance strength, steps, sampler type, and seed. Raise steps for more detail and stability, and use a fixed seed to reproduce results when iterating on prompts.
Preview and save The latent sequence is decoded with VAEDecode (#8), framed into a video at 24 fps with CreateVideo (#101), and written by SaveVideo (#102). This gives you a quick 720p preview ready to review.
1080p finishing (optional) Toggle the “Video Upscale 1080P” group to enable the finishing chain. The latent upsampler expands to 1920×1080, then the distilled super-resolution UNet refines detail in two phases. VAEDecodeTiled and a second CreateVideo/SaveVideo pair export the 1080p result.
Text to Video#
Step 1 — Load models The loaders fetch the Hunyuan Video 1.5 720p text-to-video UNet, the 3D VAE, and the dual text encoders. This path does not require a start image.
Step 3 — Prompt Enter your description in the positive encoder CLIP Text Encode (Positive Prompt) (#149) and optionally add a negative prompt in CLIP Text Encode (Negative Prompt) (#155). Describe scene, subject, motion, and camera, keeping language concrete.
Step 4 — Video size and duration EmptyHunyuanVideo15Latent (#183) allocates the initial latent with your chosen width, height, and frame count. Use this to set how long and how large your video should be.
Custom sampling ModelSamplingSD3 (#165), CFGGuider (#164), BasicScheduler (#161), KSamplerSelect (#163), RandomNoise (#162), and SamplerCustomAdvanced (#166) collaborate to turn noise into a coherent video guided by your text. Adjust steps and guidance to trade speed for fidelity, and fix the seed to make runs comparable.
Preview and save The decoded frames are assembled by CreateVideo (#168) and saved by SaveVideo (#167) for a fast 720p review at 24 fps.
1080p finishing (optional) Enable the “Video Upscale 1080P” group to upscale latents to 1080p and refine with the distilled SR UNet. The two-stage sampling improves sharpness while preserving motion. A tiled decoder and a second save stage export the final 1080p video.
Key nodes in Comfyui Hunyuan Video 1.5 workflow#
HunyuanVideo15ImageToVideo (#78) Generates a video by conditioning on a start image and your prompts. Adjust its resolution and total frames to match your creative target. Higher resolutions and longer clips increase VRAM and time. This node is central to image-to-video quality because it fuses CLIP-Vision features with text guidance before sampling.
EmptyHunyuanVideo15Latent (#183) Initializes the latent grid for text-to-video with width, height, and frame count. Use it to define sequence length up front so the scheduler and sampler can plan a stable denoising trajectory. Keep aspect ratio consistent with your intended output to avoid extra padding later.
CFGGuider (#129) Sets classifier-free guidance strength, balancing prompt adherence against naturalness. Increase guidance to follow the prompt more strictly; lower it to reduce oversaturation and flicker. Use moderate values during base generation and lower guidance for super-resolution refinement.
BasicScheduler (#126) Controls the number of denoising steps and the schedule. More steps usually mean better detail and stability but longer renders. Pair step count with sampler choice for best results; this workflow defaults to a fast, general-purpose sampler.
SamplerCustomAdvanced (#125) Executes the denoising loop with your selected sampler and guidance. In the 1080p finishing chain, it works in two phases split by SplitSigmas to first establish structure at higher noise then refine low-noise details. Keep seeds fixed while tuning steps and guidance so you can compare outputs reliably.
HunyuanVideo15LatentUpscaleWithModel (#109) Rescales the latent sequence to 1920×1080 using the dedicated upsampler from the repackaged weights. Upscaling in latent space is faster and more memory-friendly than pixel-space resizing, and it sets the stage for the distilled SR model to add fine detail. Larger targets demand more VRAM; keep 16:9 for best throughput.
HunyuanVideo15SuperResolution (#113) Refines the upscaled latent with the 1080p SR distilled UNet from the Hunyuan Video 1.5 bundle, optionally taking start-image and CLIP-Vision cues for consistency. This adds crisp textures and line work while maintaining motion. The SR weights are available in Comfy-Org/HunyuanVideo_1.5_repackaged.
EasyCache (#116) Caches intermediate model states to accelerate preview iterations. Enable it when you want faster turnaround, and disable for maximum quality on your final pass. It is especially useful when iterating on prompts with the same resolution and duration.
Optional extras#
- Keep prompts concrete. Describe subject, motion verbs, and camera moves. Use a short negative prompt to suppress artifacts you repeatedly see.
- Favor clean, high-contrast start images for image-to-video. Match the aspect ratio to your target resolution to minimize padding.
- For speed, iterate at shorter durations and 720p; switch on the 1080p group only for final runs.
- If VRAM is tight, toggle tiled VAE decode and consider loading weights in a lower precision setting exposed by the model loader.
- Fix seeds while tuning steps, guidance, and wording to make changes measurable across runs.
Acknowledgements#
This workflow implements and builds upon the following works and resources. We gratefully acknowledge Comfy.org for the Hunyuan Video 1.5 workflow tutorial for their contributions and maintenance. For authoritative details, please refer to the original documentation and repositories linked below.
Resources#
- Hunyuan Video 1.5 Source
- Docs / Release Notes: Hunyuan Video 1.5 Source
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.
