
Janus-Pro is a cutting-edge autoregressive framework that unifies multimodal understanding and generation, addressing key limitations of previous approaches. By decoupling visual encoding into separate pathways while maintaining a single transformer architecture, Janus-Pro eliminates conflicts between perception and synthesis, enhancing both flexibility and performance in multimodal AI. With Janus-Pro, users can achieve a more refined balance between visual comprehension and content generation, making Janus-Pro a superior choice for next-generation AI solutions.
At the core of Janus-Pro’s design is its innovative dual-pathway visual encoding strategy, which allows Janus-Pro to process visual inputs more effectively without sacrificing its generative capabilities. Unlike traditional unified models that struggle with balancing understanding and generation, Janus-Pro optimizes both tasks by assigning them dedicated encoding pathways while still leveraging a single, powerful transformer for processing. This approach enables Janus-Pro to seamlessly adapt across diverse multimodal tasks, from image synthesis to text-guided generation, reinforcing Janus-Pro’s ability to outperform existing AI frameworks.
A major challenge in unified multimodal models is maintaining high performance across a wide range of tasks without requiring task-specific architectures. Janus-Pro overcomes this with its streamlined yet highly adaptable framework, surpassing previous unified models and even matching or exceeding the performance of specialized task-specific solutions. With its simplicity, flexibility, and superior effectiveness, Janus-Pro represents a significant step forward in multimodal AI. Janus-Pro is setting a new benchmark for next-generation unified models, proving that Janus-Pro is the future of multimodal AI technology.
1.1 How to Use Janus-Pro Workflow?#
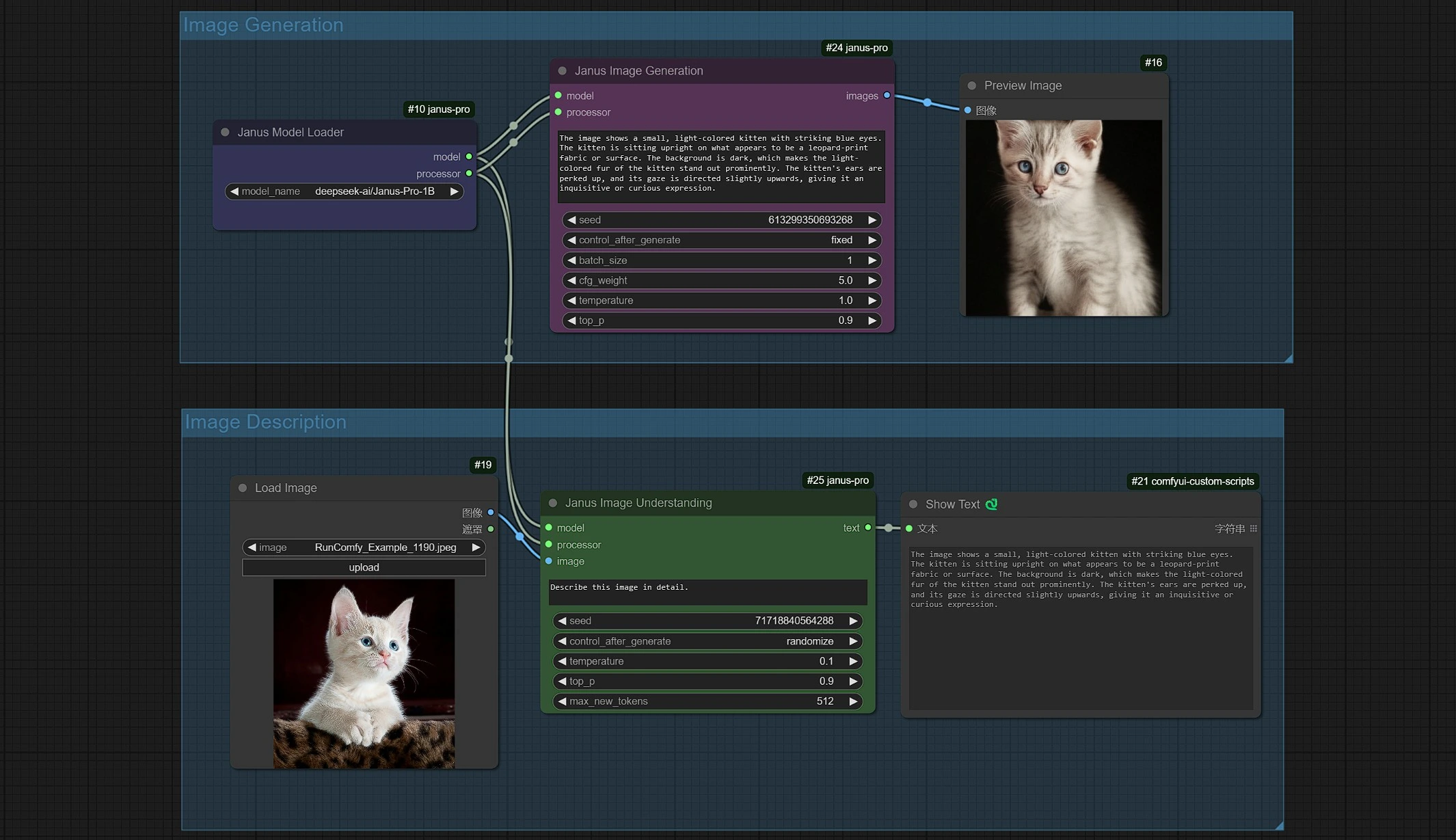
You can use Janus-Pro workflow in 2 ways
- Janus-Pro Image generation
- Janus-Pro Image Description (OCR, Captions, Describe...etc)
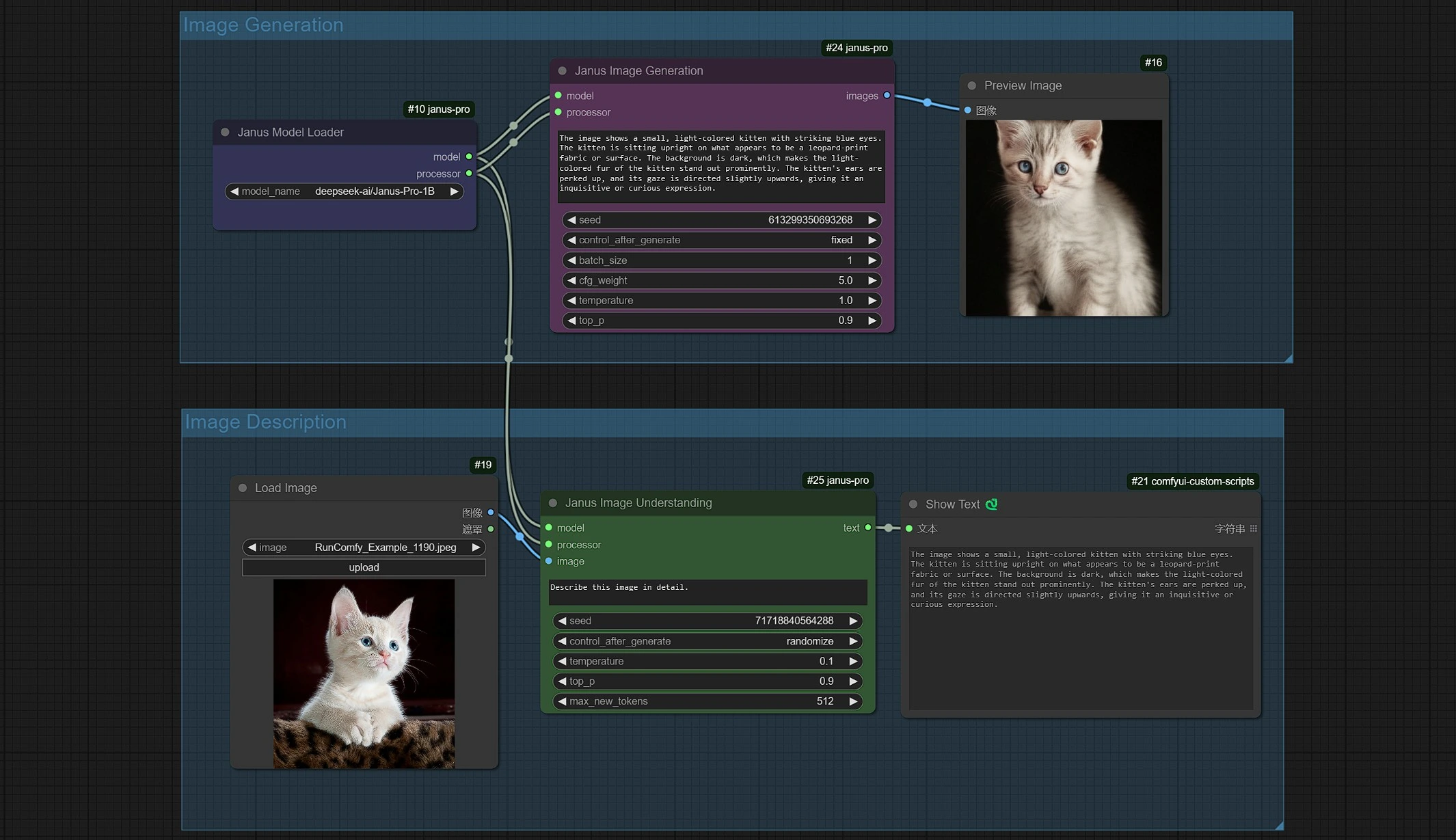
1.2 Janus-Pro Image Generation#
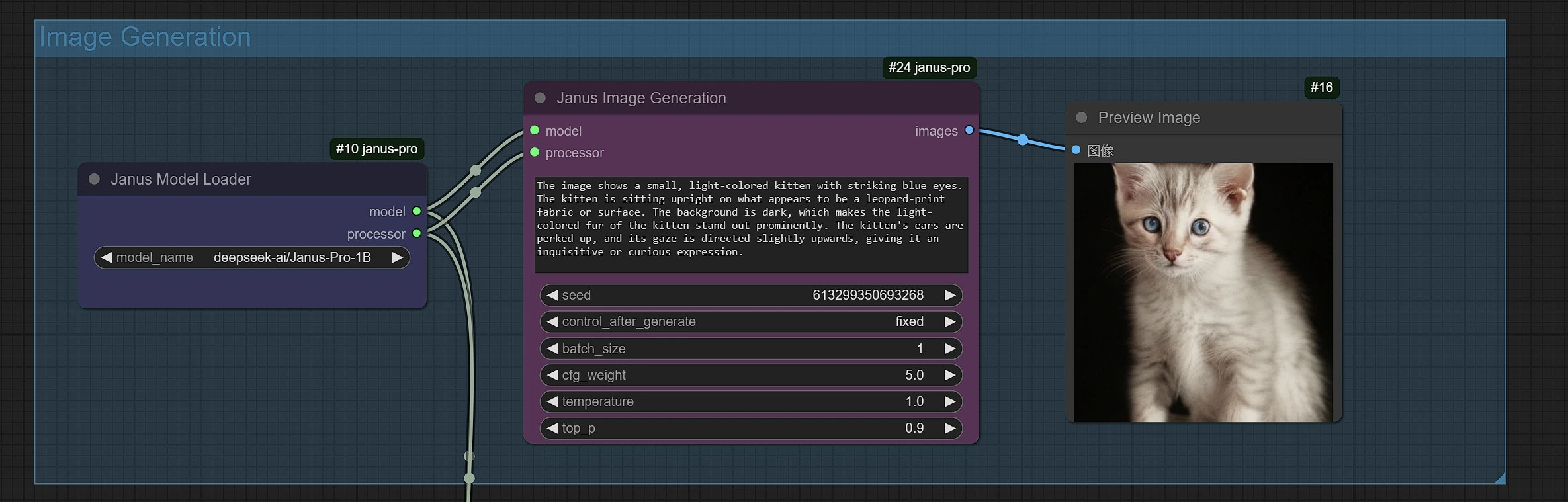
- The Janus Image Generation Sampler lets you enter prompts.
- You can use Janus-Pro-1B or Janus-Pro-7B model.
- Janus-Pro Image generation is currently restricted to a 1:1 Square (384*384 px) ratio.
The Janus-Pro models will be auto-downloaded in your cloud runcomfy machine upon running for the first time. This may take 2-5 minutes when queuing for the first time. Models Link -
- Janus-Pro-1B - https://huggingface.co/deepseek-ai/Janus-Pro-1B
- Janus-Pro-7B - https://huggingface.co/deepseek-ai/Janus-Pro-7B
The models will be downloaded in : Comfyui/models/Janus-Pro
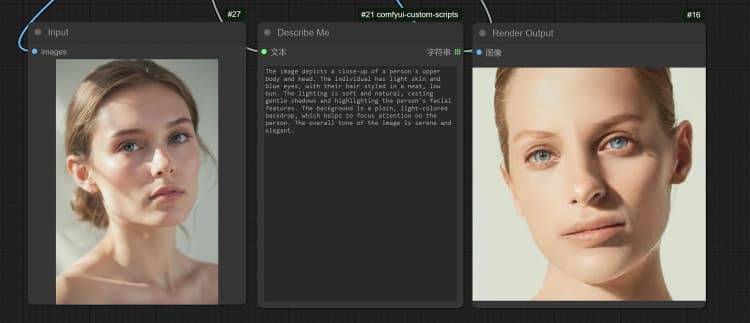
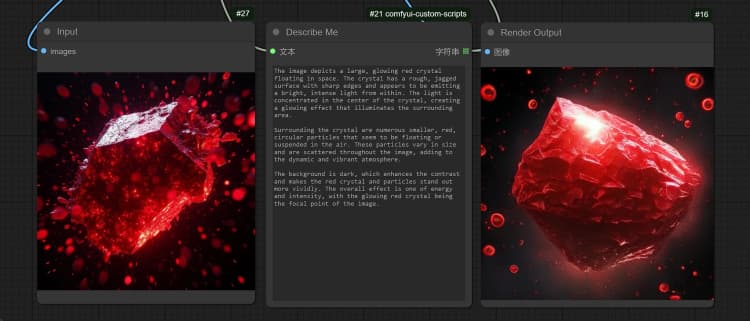
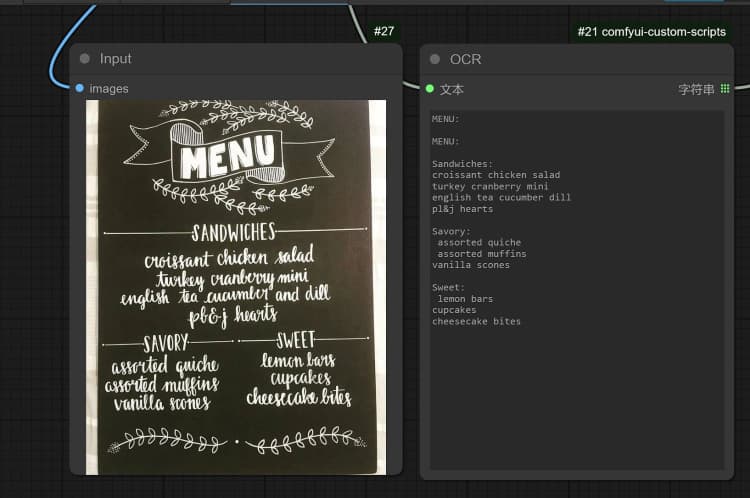
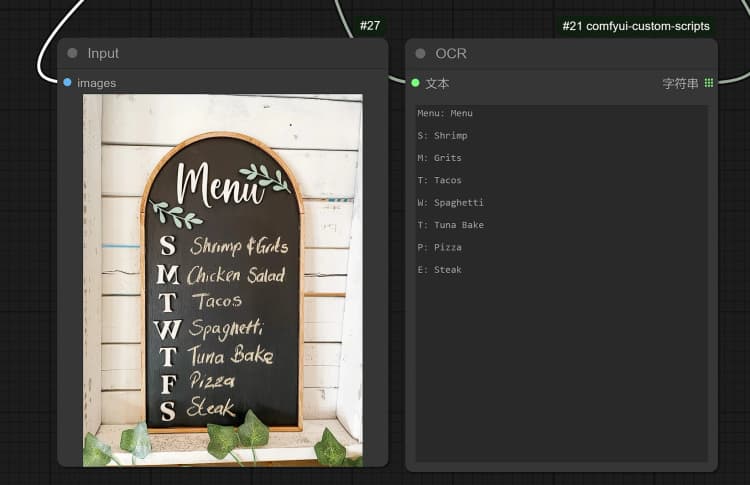
1.3 Janus-Pro Image Description#
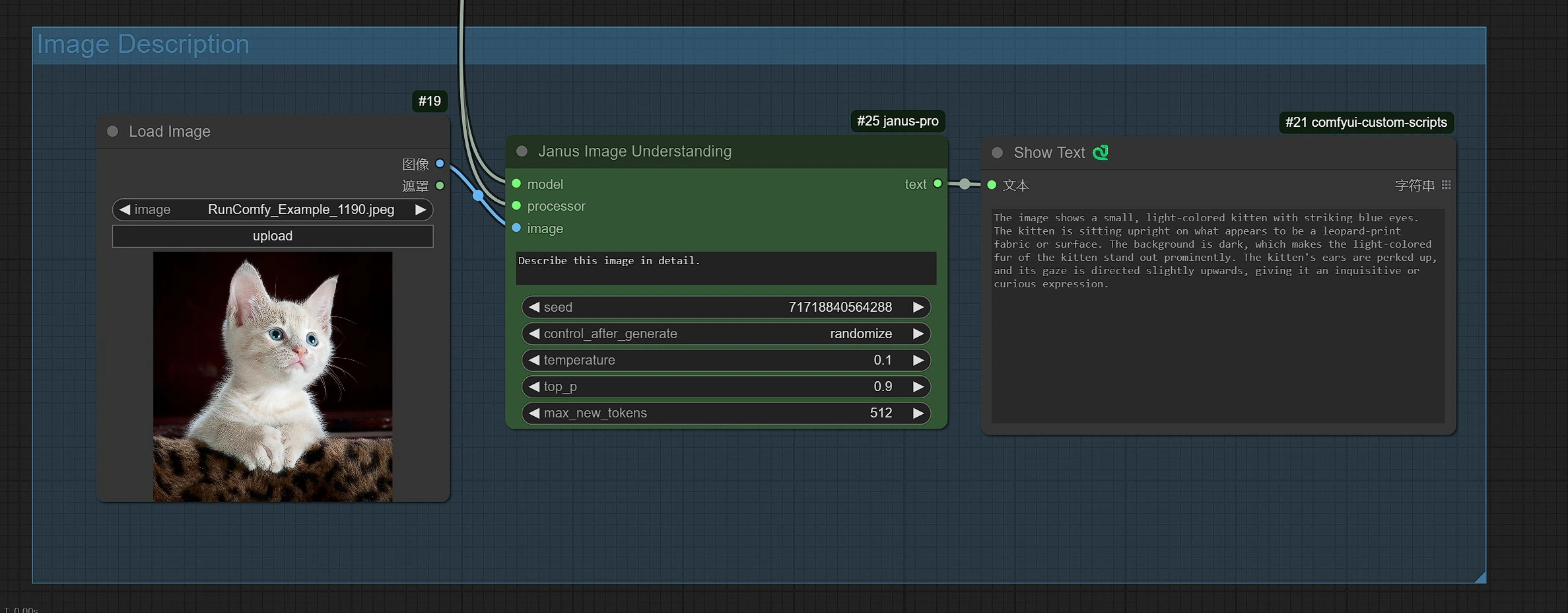
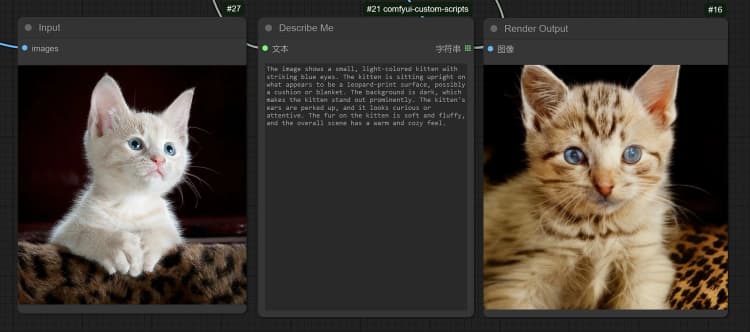
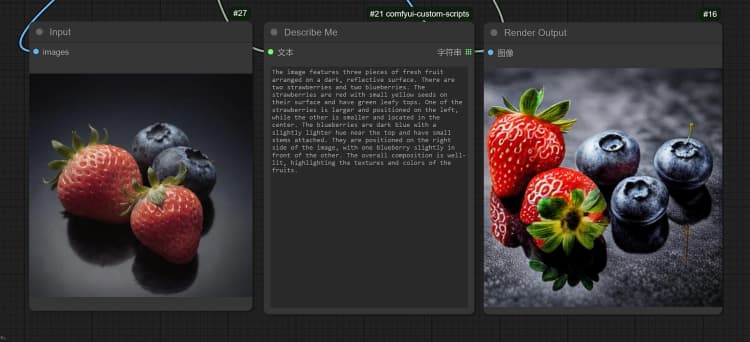
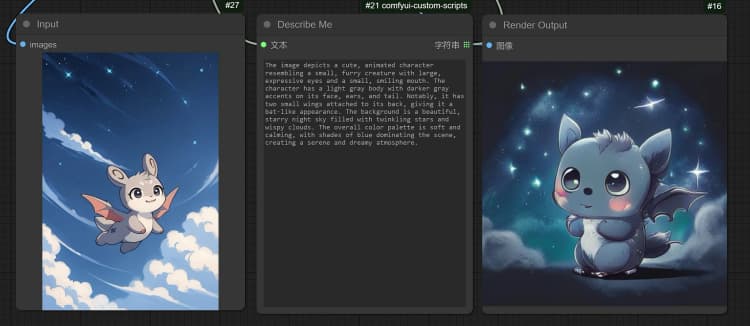
- Click and Upload an Image in the Load Image Node for Janus-Pro processing.
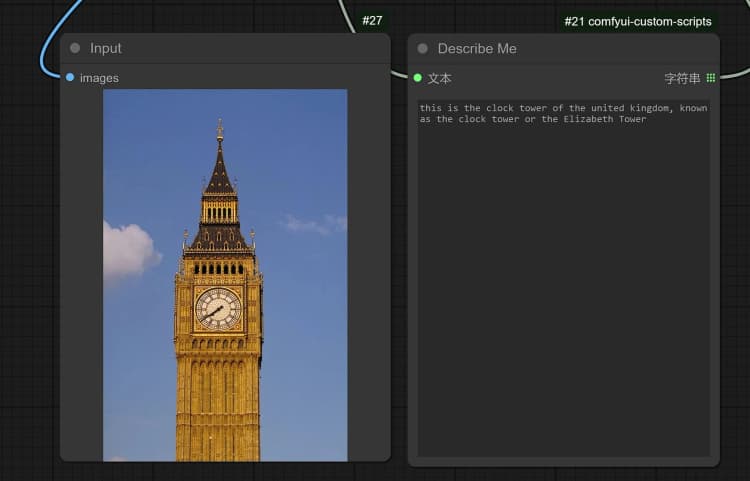
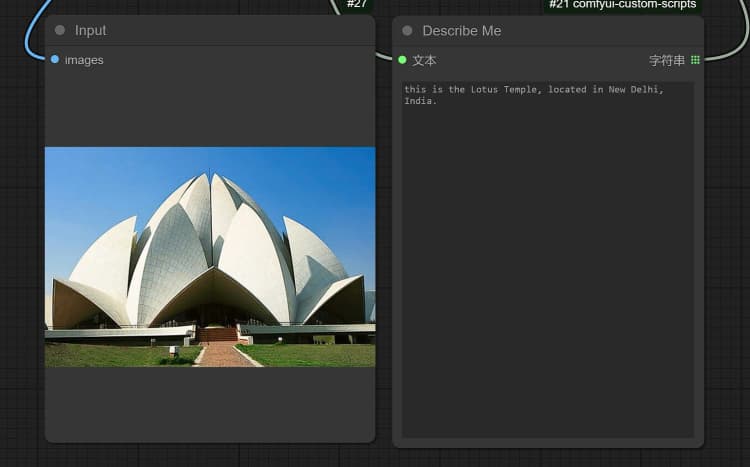
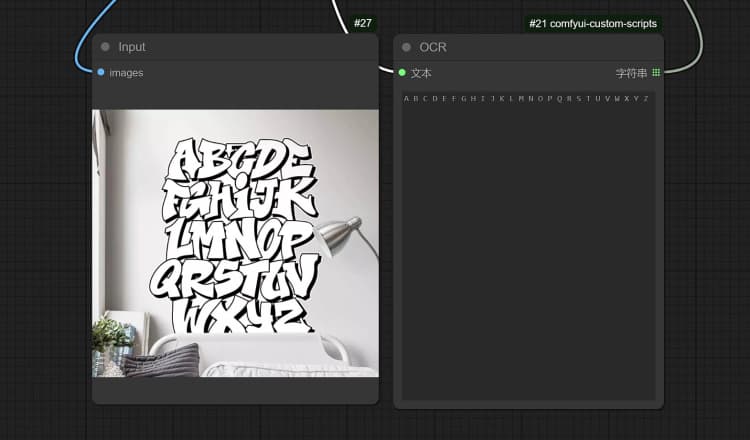
- You can perform : OCR, Captions, Detailed Description using the Janus-Pro Image Understanding Node. Simply type your request in the Type Box provided in the node.
Example Question: “Describe this image in detail, where is this located, what is written in it… etc.”
Janus-Pro sets a new standard for multimodal AI by seamlessly integrating understanding and generation within a unified framework. Janus-Pro’s innovative dual-pathway encoding enhances flexibility, resolving conflicts that hinder traditional models. By surpassing previous unified architectures and rivaling task-specific solutions, Janus-Pro paves the way for more efficient and versatile AI systems. As a powerful and adaptable framework, Janus-Pro stands at the forefront of next-generation multimodal intelligence, proving that Janus-Pro is the future of multimodal AI.


