
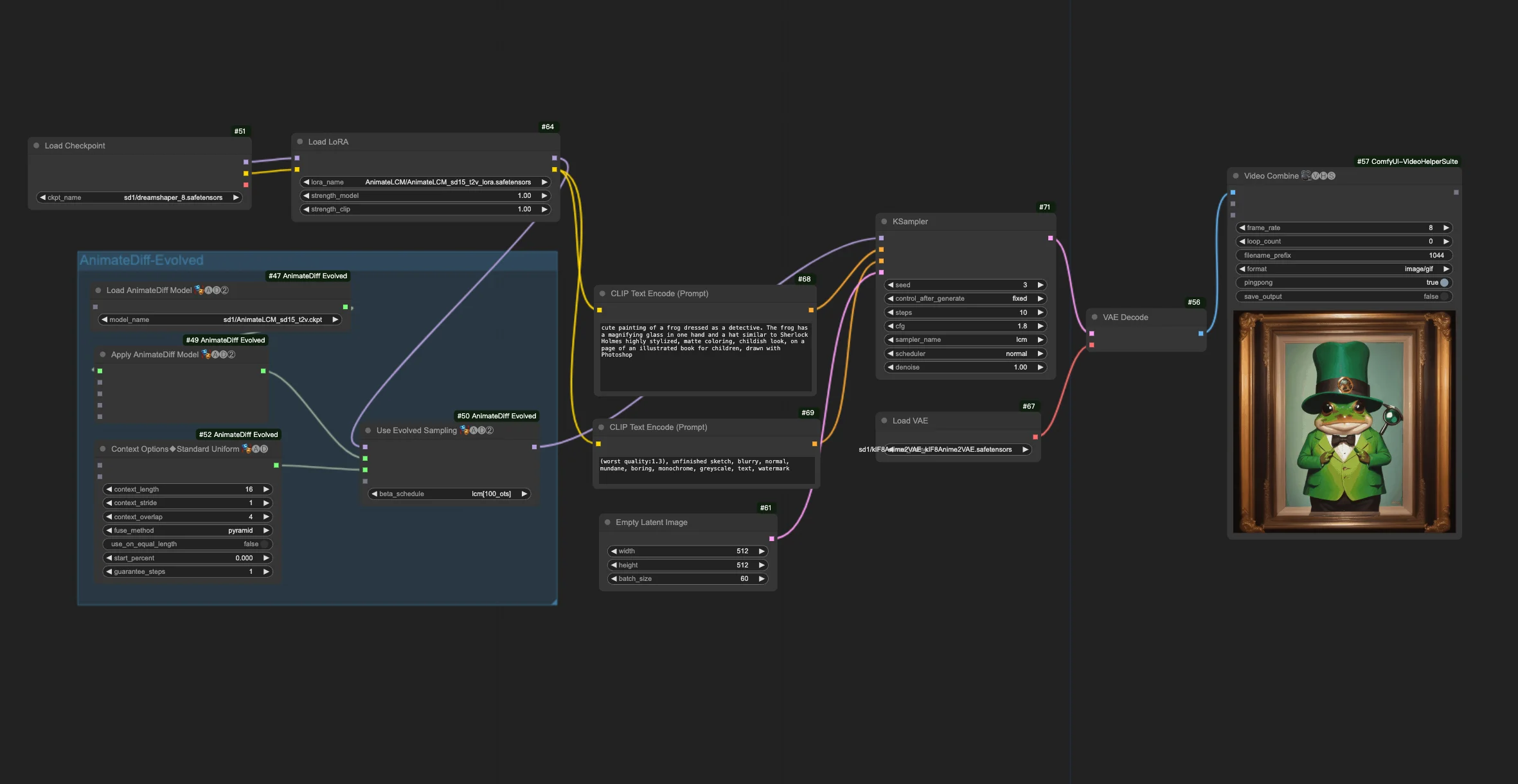
1. ComfyUI AnimateLCM Workflow#
The ComfyUI AnimateLCM Workflow is designed to enhance AI animation speeds. Building on the foundations of ComfyUI-AnimateDiff-Evolved, this workflow incorporates AnimateLCM to specifically accelerate the creation of text-to-video (t2v) animations. You can experiment with various prompts and steps to achieve desired results.
2. Overview of AnimateLCM#
The advent of technologies like SDXL, LCM, and SDXL Turbo has significantly boosted the pace of image generation. AnimateLCM further propels the progress in AI animation. It supports fast image-to-video generation and is aimed at enhancing the speed and efficiency of producing animated videos from static images or text descriptions, making it particularly useful for creating personalized animation effects quickly
2.1. Introduction to AnimateLCM#
AnimateLCM is designed to accelerate the animation of personalized diffusion models and adapters through decoupled consistency learning. It is inspired by the Consistency Model (CM), which distills pretrained image diffusion models to accelerate the sampling process, and its extension, the Latent Consistency Model (LCM), which focuses on conditional image generation. AnimateLCM leverages these foundations to enable the creation of videos with high fidelity in a few steps, building on the success of image diffusion and generation techniques to expand their capabilities into the video domain.
2.2. How to use AnimateLCM in Your ComfyUI Workflow#
This workflow builds on the ComfyUI-AnimateDiff-Evolved Workflow. The following are the configuring parameters in the "Use Evolved Sampling" node.
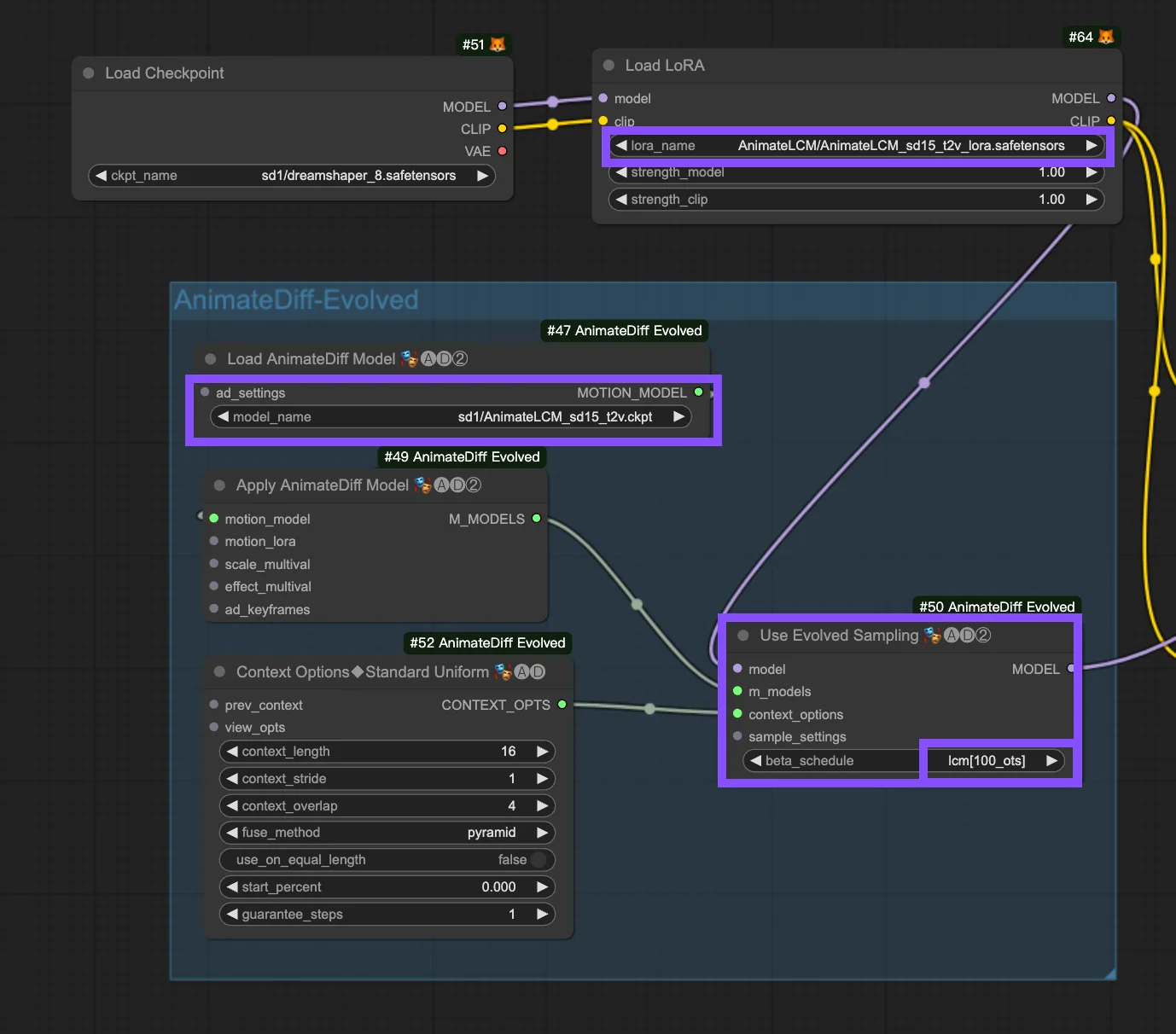
Models: Set checkpoint model and LoRA model.
- Checkpoint: This pertains to the StableDiffusion (SD) model inputs utilized for animation creation. Depending on the chosen motion models, compatibility may vary across SD versions, such as SD1.5 or SDXL.
- LoRA: Incorporating the AnimateLCM LoRA model to seamlessly integrate existing adapters for a variety of functions, enhancing efficiency and output quality with a focus on consistency learning without sacrificing sampling speed.
Motion Models (M Models): These are the outputs from the Apply AnimateDiff Model process, enabling the use of AnimateLCM Motion Model.
Context Options: These settings adjust AnimateDiff's operation during animation production, allowing for animations of any length via sliding context windows across the entire Unet or within the motion module specifically. They also enable timing adjustments for complex animation sequences. Refer here for a comprehensive guide on AnimateDiff
Beta Schedule in Sample Settings: Opt for LCM. Within AnimateDiff’s Sample Settings in ComfyUI, the "beta schedule" selection, including options like "lcm," "lineart," etc., fine-tunes the beta values that regulate noise levels throughout the diffusion process. This customization affects the visual style and fluidity of the animation. Each setting caters to specific animation or motion model needs.
- LCM (Latent Consistency Module): The "lcm" setting is tailored for LCM LoRAs, enhancing animation uniformity and reducing creation time. It achieves quicker convergence with fewer steps, requiring step reduction (to a minimum of ~4 steps) and other parameter adjustments for optimal detail retention.
- Linear (AnimateDiff-SDXL): Recommended for AnimateDiff with SDXL motion modules, this option strikes a balance between detail preservation and smooth motion, indicating compatibility with specific motion model versions.
- Sqrt_lineart (AnimateDiff): Similar to "lineart," this variant is designed for AnimateDiff processes, especially with V2 motion modules, modifying noise levels to complement the motion model’s output for more fluid transitions or movements.