
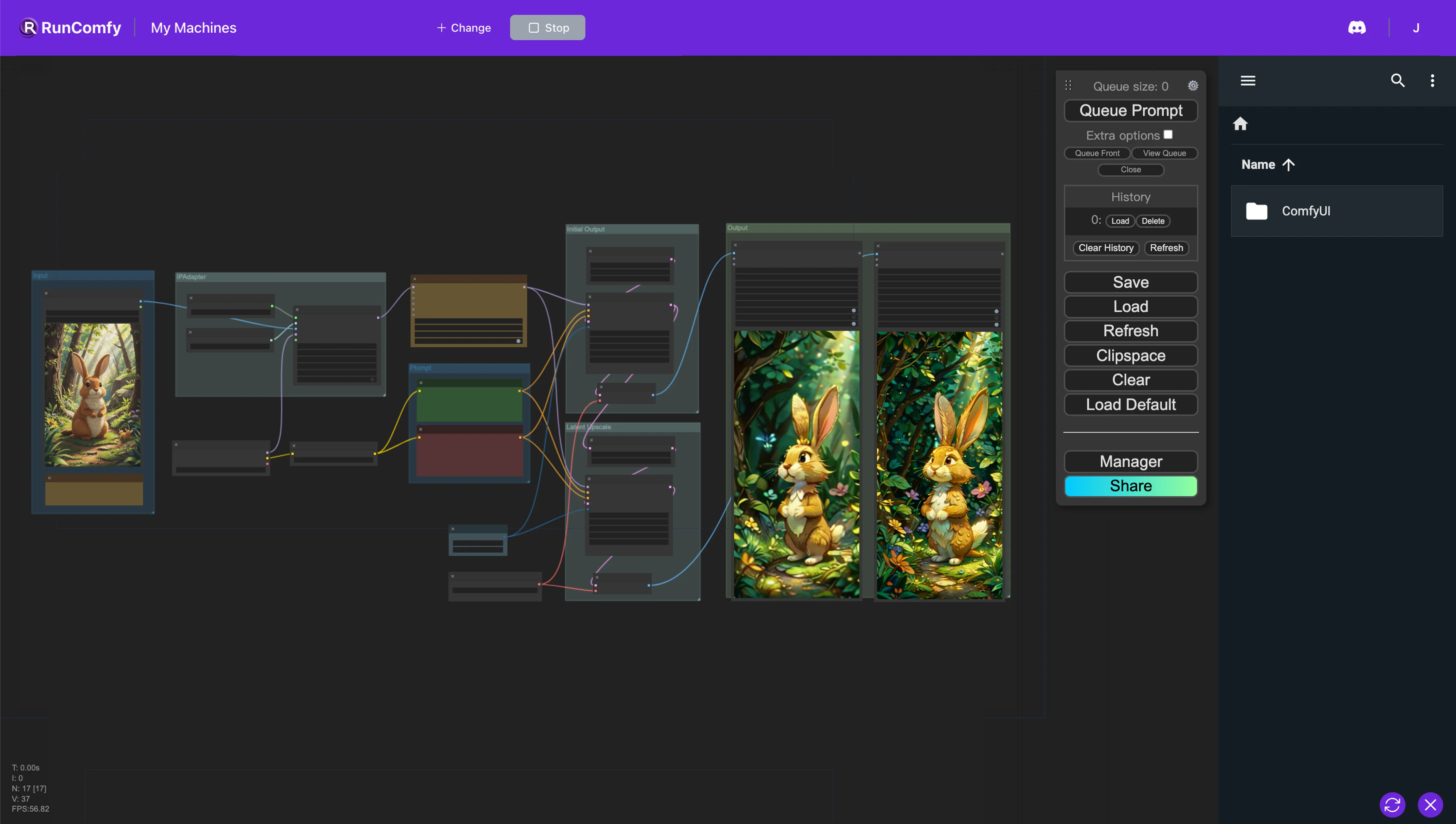
1. ComfyUI Workflow: AnimateDiff + IPAdapter | Image to Video#
This ComfyUI workflow is designed for creating animations from reference images by using AnimateDiff and IP-Adapter. The AnimateDiff node integrates model and context options to adjust animation dynamics. Conversely, the IP-Adapter node facilitates the use of images as prompts in ways that can mimic the style, composition, or facial features of the reference image, significantly enhancing the customization and quality of generated animations or images.
2. Overview of AnimateDiff#
Please check out the details on How to use AnimateDiff in ComfyUI
3. Overview of IP-Adapter#
3.1. Introduction to IP-Adapter#
IP-Adapter stands for "Image Prompt Adapter," a novel approach for enhancing text-to-image diffusion models with the capability to use image prompts in image generation tasks. IP-Adapter aims to address the shortfalls of text prompts which often require complex prompt engineering to generate desired images. The introduction of image prompts, alongside text, allows for a more intuitive and effective way to guide the image synthesis process.
Different Models of IP-Adapter
The IP-Adapter suite includes a variety of models, each tailored for specific use cases and levels of image synthesis complexity. Here is an overview of the different models available:
3.1.1. v1.5 Models
ip-adapter_sd15: The standard model for version 1.5, which utilizes the power of IP-Adapter for image-to-image conditioning and text prompt augmentation.ip-adapter_sd15_light: A lighter version of the standard model, optimized for less resource-intensive applications while still leveraging IP-Adapter technology.ip-adapter-plus_sd15: An enhanced model that produces images more closely aligned with the original reference, improving on the fine details.ip-adapter-plus-face_sd15: Similar to IP-Adapter Plus, with a focus on more accurate facial feature replication in the generated images.ip-adapter-full-face_sd15: A model that emphasizes full-face details, likely offering a "face swap" effect with high fidelity.ip-adapter_sd15_vit-G: A variant of the standard model using the Vision Transformer (ViT) BigG image encoder for more detailed image feature extraction.
3.1.2. SDXL Models
ip-adapter_sdxl: The base model for the SDXL, which is designed to handle larger and more complex image prompts.ip-adapter_sdxl_vit-h: The SDXL model paired with the ViT H image encoder, balancing performance with computational efficiency.ip-adapter-plus_sdxl_vit-h: An advanced version of the SDXL model with enhanced image prompt detail and quality.ip-adapter-plus-face_sdxl_vit-h: An SDXL variant focused on face details, ideal for projects where facial accuracy is paramount.
3.1.3. FaceID Models
FaceID: A model using InsightFace to extract Face ID embeddings, offering a unique approach to face-related image generation.FaceID Plus: An improved version of the FaceID model, combining InsightFace for facial features and CLIP image encoding for global facial features.FaceID Plus v2: An iteration on FaceID Plus with an improved model checkpoint and the ability to set a weight on the CLIP image embedding.FaceID Portrait: A model similar to FaceID but designed to accept multiple images of cropped faces for more diverse face conditioning.
3.1.4. SDXL FaceID Models
FaceID SDXL: The SDXL version of FaceID, maintaining the same InsightFace model as the v1.5 but scaled for SDXL applications.FaceID Plus v2 SDXL: An SDXL adaptation of FaceID Plus v2 for high-definition image generation with enhanced fidelity.
3.2. Key Features of IP-Adapter#
3.2.1. Text and Image Prompt Integration: The IP-Adapter's unique capability to use both text and image prompts enables multimodal image generation, providing a versatile and powerful tool for controlling diffusion model outputs.
3.2.2. Decoupled Cross-Attention Mechanism: The IP-Adapter employs a decoupled cross-attention strategy that enhances the model's efficiency in processing diverse modalities by separating text and image features.
3.2.3. Lightweight Model: Despite its comprehensive functionality, the IP-Adapter maintains a relatively low parameter count (22M), offering performance that rivals or exceeds that of fine-tuned image prompt models.
3.2.4. Compatibility and Generalization: The IP-Adapter is designed for broad compatibility with existing controllable tools and can be applied to custom models derived from the same base model for enhanced generalization.
3.2.5. Structure Control: IP-Adapter supports detailed structure control, enabling creators to guide the image generation process with greater precision.
3.2.6. Image-to-Image and Inpainting Capabilities: With support for image-guided image-to-image translation and inpainting, the IP-Adapter broadens the scope of possible applications, enabling creative and practical uses in a variety of image synthesis tasks.
3.2.7. Customization with Different Encoders: The IP-Adapter allows for the use of various encoders, such as OpenClip ViT H 14 and ViT BigG 14, to process reference images. This flexibility facilitates handling different image resolutions and complexities, making it a versatile tool for creators looking to tailor the image generation process to specific needs or desired outcomes.
The incorporation of IP-Adapter technology in image generation projects not only simplifies the creation of complex and detailed images but also significantly enhances the quality and fidelity of the generated images to the original prompts. By bridging the gap between text and image prompts, IP-Adapter provides a powerful, intuitive, and efficient approach to controlling the nuances of image synthesis, making it an indispensable tool in the arsenal of digital artists, designers, and creators working within the ComfyUI workflow or any other context that demands high-quality, customized image generation.
