
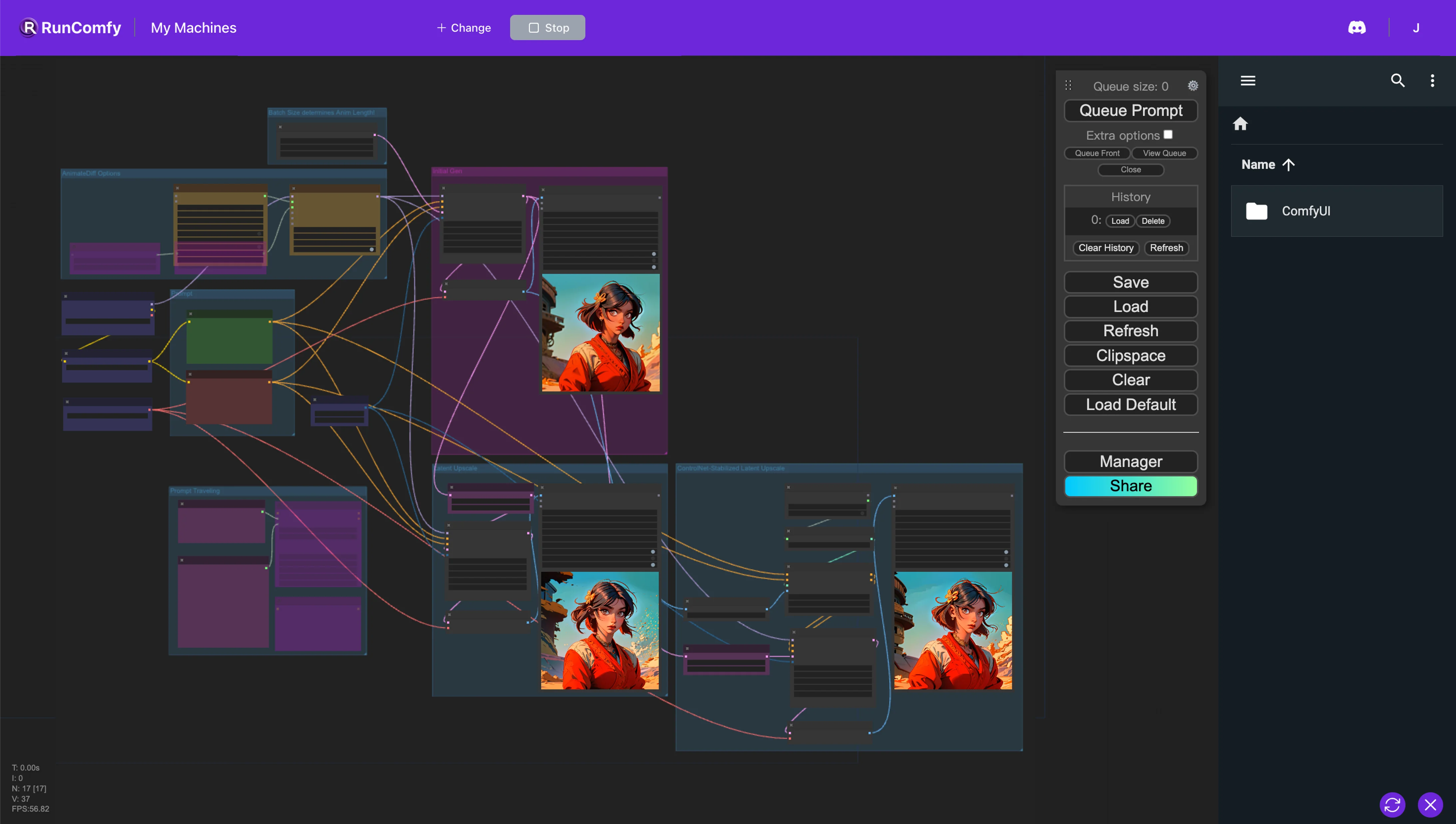
1. ComfyUI AnimateDiff Workflow#
This ComfyUI AnimateDiff workflow is designed for users to delve into the sophisticated features of AnimateDiff across AnimateDiff V3, AnimateDiff SDXL, and AnimateDiff V2 versions. It facilitates exploration of a wide range of animations, incorporating various motions and styles. After creating animations with AnimateDiff, Latent Upscale is employed for achieving high-resolution outcomes using two approaches. The first leverages traditional latent upscaling within ComfyUI, with adjustments such as denoising strength and upscale factor. The second, Control Net Assisted Latent Upscale, offers more precise enhancements by integrating a line art preprocessor and the suitable control net model, significantly improving the artwork while maintaining its original essence.
2. Overview of AnimateDiff#
2.1. Introduction to AnimateDiff#
AnimateDiff emerges as a pioneering framework, designed to breathe life into images generated by text-to-image models, such as Stable Diffusion. This tool allows users to seamlessly integrate motion into static images, transforming them into personalized animated visuals. The framework is built on the premise of enhancing existing text-to-image models with a motion modeling module, trained on video clips to capture realistic motion dynamics. This process eliminates the need for model-specific adjustments, offering a universal solution for animating personalized images.
2.2. Different versions of AnimateDiff#
2.2.1. AnimateDiff V3: Revolutionizing Motion with New Technologies
AnimateDiff V3 introduces a groundbreaking motion module, encapsulating the latest advancements in animation technology. At the heart of this evolution lies the Domain Adapter LoRA module, a mechanism that prepares the motion module by training on static video frames. This setup enables AnimateDiff to adeptly navigate the complexities of motion, ensuring animations are both nuanced and flexible. Unlike its predecessor, V3 doesn't surpass V2 across all dimensions but introduces varied motion capabilities, enriching the user's creative toolkit.
2.2.2. AnimateDiff SDXL: High-Resolution Video Animation
For enthusiasts of high-definition visuals, AnimateDiff SDXL presents an enticing option. This Beta version supports the creation of high-resolution videos (1024x1024 resolution with 16 frames), accommodating various aspect ratios with or without personalized models. Despite being in Beta, SDXL promises to elevate the quality of animated content, with more refined versions anticipated shortly.
2.2.3. AnimateDiff V2: Classic Motion and Camera Movement Controls
AnimateDiff V2 stands as the foundational version that significantly improved sample quality through enhanced resolution and batch size training. It introduced MotionLoRA, facilitating control over eight fundamental camera movements, including Zoom In/Out, Pan Left/Right, Tilt Up/Down, and Rolling Clockwise/Anticlockwise. This version is ideal for users seeking to incorporate dynamic camera movements into their animations, offering a robust set of tools for creating dramatic visual narratives.

