
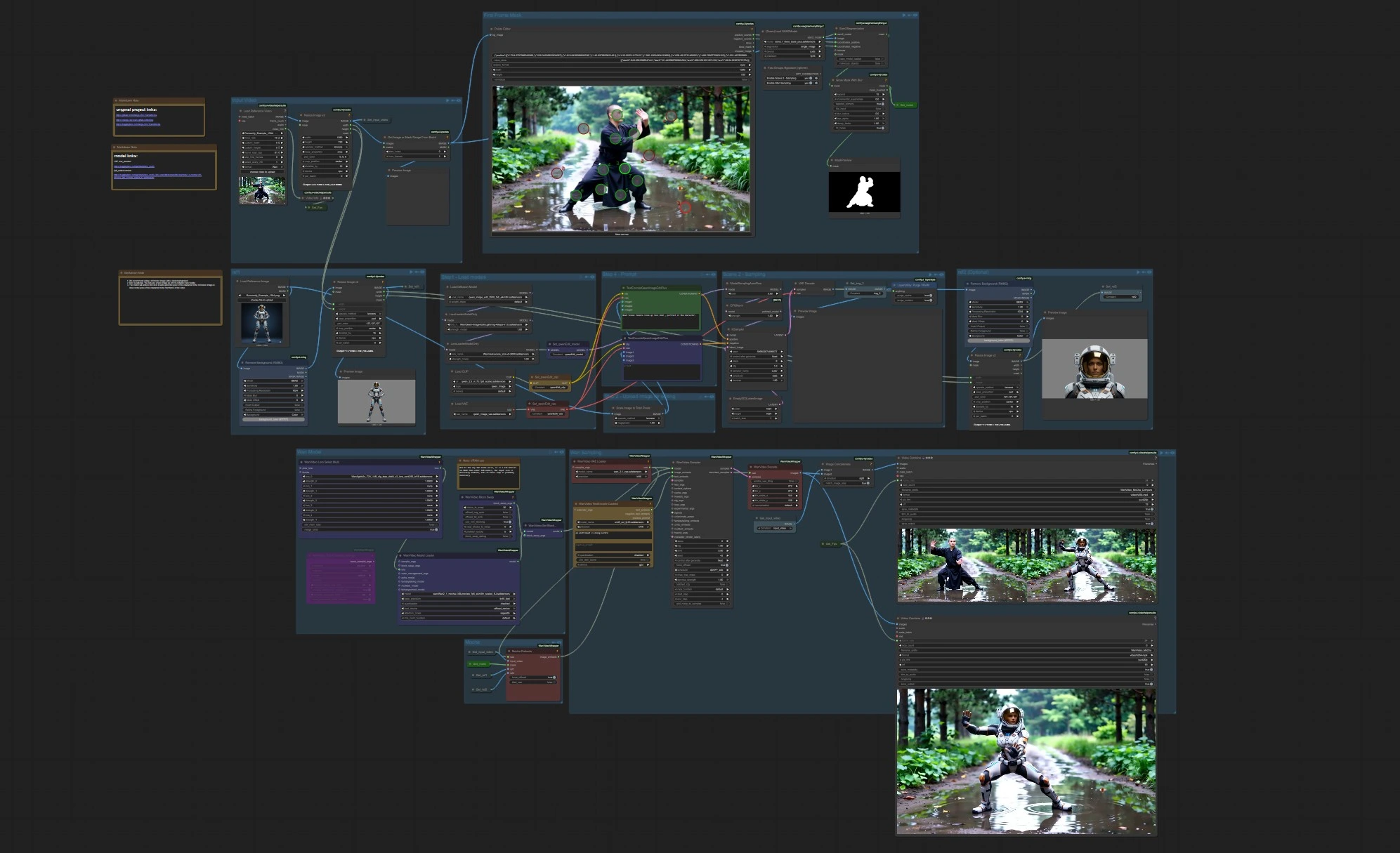
Video Character Replacement (MoCha) workflow for ComfyUI#
This workflow delivers end‑to‑end Video Character Replacement (MoCha): swap a performer in a real video with a new character while preserving motion, lighting, camera perspective, and scene continuity. Built around the Wan 2.1 MoCha 14B preview, it aligns a reference identity to the source performance, then synthesizes a coherent, edited clip and an optional side‑by‑side comparison. It is designed for filmmakers, VFX artists, and AI creators who need precise, high‑quality character swaps with minimal manual cleanup.
The pipeline combines robust first‑frame masking with Segment Anything 2 (SAM 2), MoCha’s motion‑aware image embeddings, WanVideo sampling/decoding, and an optional portrait assist that improves face fidelity. You provide a source video and one or two reference images; the workflow produces a finished replacement video plus an A/B compare, making iterative evaluation of Video Character Replacement (MoCha) fast and practical.
Key models in Comfyui Video Character Replacement (MoCha) workflow#
- Wan 2.1 MoCha 14B preview. Core video generator for character replacement; drives temporally coherent synthesis from MoCha image embeddings and text prompts. Model weights distributed in the WanVideo Comfy format by Kijai, including fp8 scaled variants for efficiency. Hugging Face: Kijai/WanVideo_comfy, Kijai/WanVideo_comfy_fp8_scaled
- MoCha (Orange‑3DV‑Team). Identity/motion conditioning method and reference implementation that inspired the embedding stage used here; helpful for understanding reference selection and pose alignment for Video Character Replacement (MoCha). GitHub, Hugging Face
- Segment Anything 2 (SAM 2). High‑quality, point‑guided segmentation to isolate the actor in the first frame; clean masks are crucial for stable, artifact‑free swaps. GitHub: facebookresearch/segment-anything-2
- Qwen‑Image‑Edit 2509 + Lightning LoRA. Optional single‑image assist that generates a clean, close‑up portrait to use as a second reference, improving facial identity preservation in difficult shots. Hugging Face: Comfy‑Org/Qwen‑Image‑Edit_ComfyUI, lightx2v/Qwen‑Image‑Lightning
- Wan 2.1 VAE. Video VAE used by the Wan sampler/decoder stages for efficient latent processing. Hugging Face: Kijai/WanVideo_comfy
How to use Comfyui Video Character Replacement (MoCha) workflow#
Overall logic
- The workflow takes a source clip, prepares a first‑frame mask, and encodes your character references into MoCha image embeddings. Wan 2.1 then samples the edited frames and decodes them to video. In parallel, a small image‑editing branch can generate a portrait to act as an optional second reference for face detail. The graph also renders a side‑by‑side comparison to quickly assess your Video Character Replacement (MoCha) result.
Input Video
- Load a video in “Input Video.” The workflow normalizes frames (default 1280×720 crop) and preserves the clip’s frame rate automatically for the final export. The first frame is exposed for inspection and downstream masking. A preview node shows the raw input frames so you can confirm cropping and exposure before you proceed.
First Frame Mask
- Use the interactive points editor to click positive points on the actor and negative points on the background; SAM 2 converts these clicks into a precise mask. A small grow‑and‑blur step expands the mask to guard against edge halos and motion between frames. The resulting matte is previewed, and the same mask is sent to the MoCha embedding stage. Good masking in this group materially improves stability in Video Character Replacement (MoCha).
ref1
- “ref1” is your main character identity image. The workflow removes the background, centers the crop, and resizes to match the video’s working resolution. For best results, use a clean‑background reference whose pose roughly matches the source actor in the first frame; the MoCha encoder benefits from similar viewpoint and lighting.
ref2 (Optional)
- “ref2” is optional but recommended for faces. You can supply a portrait directly, or let the workflow generate one in the sampling branch below. The image is background‑removed and resized like ref1. When present, ref2 reinforces facial features so identity holds up during motion, occlusions, and perspective changes.
Step1 - Load models
- This group loads the Wan 2.1 VAE and the Wan 2.1 MoCha 14B preview model, plus an optional WanVideo LoRA for distillation. These assets drive the main video sampling stage. The model set here is VRAM‑intensive; a block‑swap helper is included later to fit large sequences on modest GPUs.
Step 2 - Upload image for editing
- If you prefer to build ref2 from your own still, drop it here. The branch scales the image and routes it into the Qwen encoder for conditioning. You can skip this entire branch if you already have a good face portrait.
Step 4 - Prompt
- Provide a short text cue that describes the intended close‑up portrait (for example, “Next Scene: Camera close up face shot, portrait of the character”). Qwen‑Image‑Edit uses this to refine or synthesize a clean face image that becomes ref2. Keep the description simple; this is an assist, not a full restyle.
Scene 2 - Sampling
- The Qwen branch runs a quick sampler to generate a single portrait image under the Lightning LoRA. That image is decoded, previewed, and, after light background removal, forwarded as ref2. This step often boosts face fidelity without changing your core Video Character Replacement (MoCha) look.
Mocha
- The
MochaEmbedsstage encodes the source video, first‑frame mask, and your reference image(s) into MoCha image embeddings. Embeddings capture identity, texture, and local appearance cues while respecting the original motion path. If ref2 exists, it is used to strengthen facial detail; otherwise, ref1 alone carries the identity.
Wan Model
- The Wan model loader pulls the Wan 2.1 MoCha 14B preview into memory and (optionally) applies a LoRA. A block‑swap tool is wired so you can trade speed for memory when needed. This model choice sets the overall capacity and coherence of Video Character Replacement (MoCha).
Wan Sampling
- The sampler consumes the Wan model, MoCha image embeddings, and any text embeddings to generate edited latent frames, then decodes them back to images. Two outputs are produced: the final swap video and a side‑by‑side comparison with the original frames. Frame rate is passed through from the loader so motion pacing matches the source automatically.
Key nodes in Comfyui Video Character Replacement (MoCha) workflow#
MochaEmbeds(#302). Encodes the source clip, first‑frame mask, and ref images into MoCha image embeddings that steer identity and appearance. Favor a ref1 pose that matches the first frame, and include ref2 for a clean face if you see drift. If edges shimmer, grow the mask slightly before embedding to avoid background leakage.Sam2Segmentation(#326). Converts your positive/negative clicks into a first‑frame mask. Prioritize clean edges around hair and shoulders; add a few negative points to exclude nearby props. Expanding the mask a small amount after segmentation helps stability when the actor moves.WanVideoSampler(#314). Drives the heavy lifting of Video Character Replacement (MoCha) by denoising latents into frames. More steps improve detail and temporal stability; fewer steps speed iteration. Keep the scheduler consistent across runs when you’re comparing changes to references or masks.WanVideoSetBlockSwap(#344). When VRAM is tight, enable deeper block swapping to fit the Wan 2.1 MoCha 14B path on smaller GPUs. Expect some speed loss; in return you can keep resolution and sequence length.VHS_VideoCombine(#355). Writes the final MP4 and embeds workflow metadata. Use the same frame rate as the source (already wired through) and yuv420p output for broad player compatibility.
Optional extras#
- Tips for clean swaps
- Use a ref1 with a plain background and a pose close to the first frame.
- Keep ref2 as a sharp, frontal face portrait to stabilize identity.
- If you see edge halos, expand and lightly blur the first‑frame mask, then re‑embed.
- Heavy scenes benefit from the block‑swap helper; otherwise keep it off for speed.
- The workflow renders an A/B compare video; use it to judge changes quickly.
- Useful references
- MoCha by Orange‑3DV‑Team: GitHub, Hugging Face
- Wan 2.1 MoCha 14B (Comfy format): Kijai/WanVideo_comfy, Kijai/WanVideo_comfy_fp8_scaled
- Segment Anything 2: facebookresearch/segment-anything-2
- Qwen Image Edit + Lightning LoRA: Comfy‑Org/Qwen‑Image‑Edit_ComfyUI, lightx2v/Qwen‑Image‑Lightning
Acknowledgements#
This workflow implements and builds upon the following works and resources. We gratefully acknowledge the Benji’s AI Playground of “Video Character Replacement (MoCha)” for Video Character Replacement (MoCha) for their contributions and maintenance. For authoritative details, please refer to the original documentation and repositories linked below.
Resources#
- Authors of “Video Character Replacement (MoCha)”/Video Character Replacement (MoCha)
- Docs / Release Notes @Benji’s AI Playground: YouTube video
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.
