
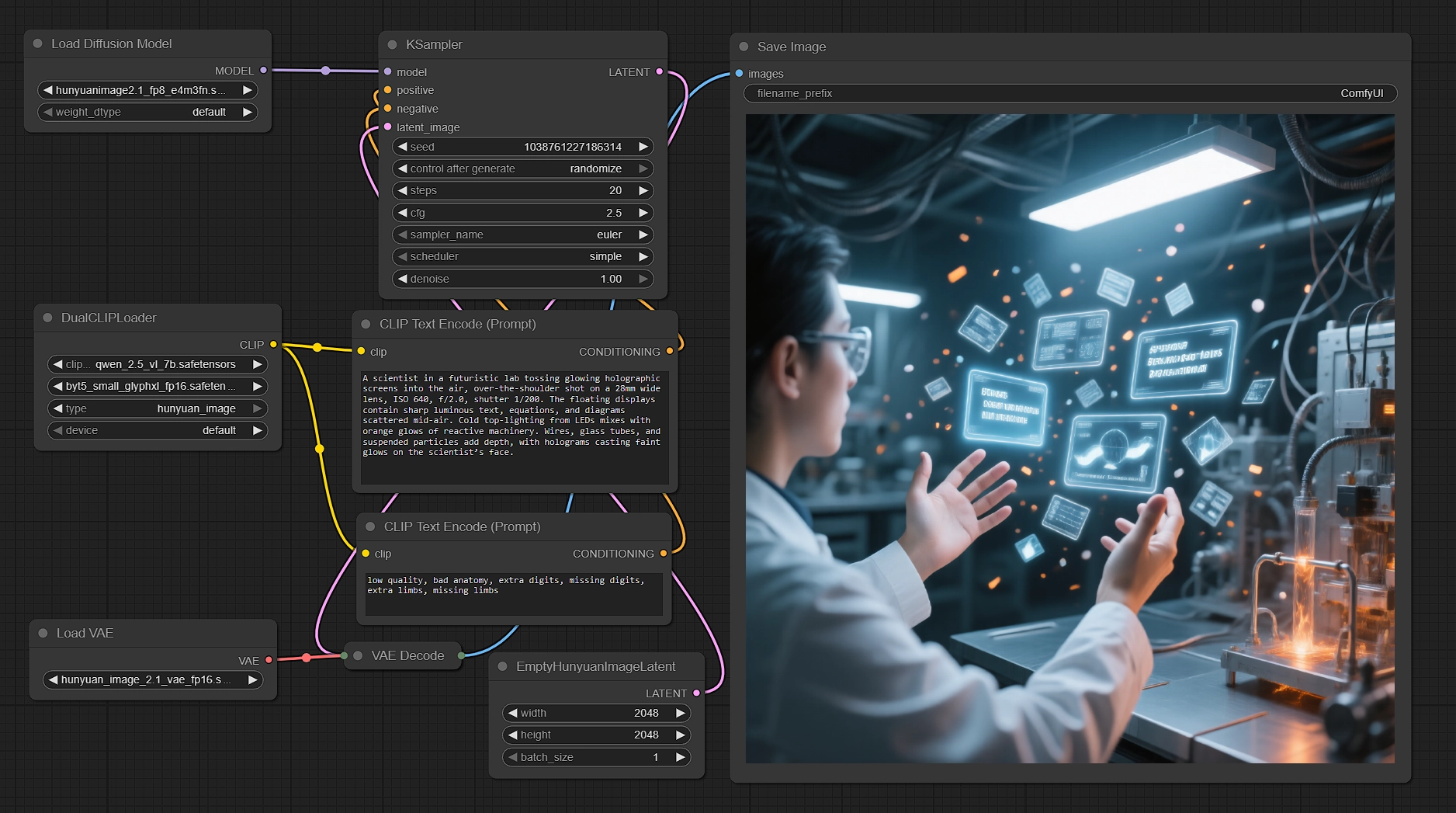










Generate native 2K images with Hunyuan Image 2.1 in ComfyUI#
This workflow turns your prompts into crisp, native 2048×2048 renders using Hunyuan Image 2.1. It pairs Tencent’s diffusion transformer with dual text encoders to lift semantic alignment and text rendering quality, then samples efficiently and decodes through the matching high‑compression VAE. If you need production‑ready scenes, characters, and clear text in image at 2K while retaining speed and control, this ComfyUI Hunyuan Image 2.1 workflow is built for you.
Creators, art directors, and technical artists can drop in multilingual prompts, fine‑tune a few knobs, and consistently get sharp results. The graph ships with a sensible negative prompt, a native 2K canvas, and an FP8 UNet to keep VRAM in check, showcasing what Hunyuan Image 2.1 can deliver out of the box.
Key models in Comfyui Hunyuan Image 2.1 workflow#
- HunyuanImage‑2.1 by Tencent. Base text‑to‑image model with a diffusion transformer backbone, dual text encoders, a 32× VAE, RLHF post‑training, and meanflow distillation for efficient sampling. Links: Hugging Face · GitHub
- Qwen2.5‑VL‑7B‑Instruct. Multimodal vision‑language encoder used here as the semantic text encoder to improve prompt understanding across complex scenes and languages. Link: Hugging Face
- ByT5 Small. Tokenizer‑free byte‑level encoder that strengthens character and glyph handling for text rendering inside images. Links: Hugging Face · Paper
How to use Comfyui Hunyuan Image 2.1 workflow#
The graph follows a clear path from prompt to pixels: encode text with two encoders, prepare a native 2K latent canvas, sample with Hunyuan Image 2.1, decode through the matching VAE, and save the output.
Text encoding with dual encoders#
- The
DualCLIPLoader(#33) loads Qwen2.5‑VL‑7B and ByT5 Small configured for Hunyuan Image 2.1. This dual setup lets the model parse scene semantics while staying robust to glyphs and multilingual text. - Enter your main description in
CLIPTextEncode(#6). You can write in English or Chinese, mix camera hints and lighting, and include text‑in‑image instructions. - A ready‑to‑use negative prompt in
CLIPTextEncode(#7) suppresses common artifacts. You can adapt it to your style or leave it as is for balanced results.
Latent canvas at native 2K#
EmptyHunyuanImageLatent(#29) initializes the canvas at 2048×2048 with a single batch. Hunyuan Image 2.1 is designed for 2K generation, so native 2K sizes are recommended for best quality.- Adjust width and height if needed, keeping aspect ratios Hunyuan supports. For alternative ratios, stick to model‑friendly dimensions to avoid artifacts.
Efficient sampling with Hunyuan Image 2.1#
UNETLoader(#37) loads the FP8 checkpoint to reduce VRAM while preserving fidelity, then feedsKSampler(#3) for denoising.- Use the positive and negative conditionings from the encoders to steer composition and clarity. Tweak seed for variety, steps for quality vs speed, and guidance for prompt adherence.
- The workflow focuses on the base model path. Hunyuan Image 2.1 also supports a refiner stage; you can add one later if you want extra polish.
Decode and save#
VAELoader(#34) brings in the Hunyuan Image 2.1 VAE, andVAEDecode(#8) reconstructs the final image from the sampled latent with the model’s 32× compression scheme.SaveImage(#9) writes the output to your chosen directory. Set a clear filename prefix if you plan to iterate across seeds or prompts.
Key nodes in Comfyui Hunyuan Image 2.1 workflow#
DualCLIPLoader (#33)#
This node loads the pair of text encoders that Hunyuan Image 2.1 expects. Keep the model type set for Hunyuan, and select Qwen2.5‑VL‑7B and ByT5 Small to combine strong scene understanding with glyph‑aware text handling. If you iterate on style, adjust the positive prompt in tandem with guidance rather than swapping encoders.
CLIPTextEncode (#6 and #7)#
These nodes turn your positive and negative prompts into conditioning. Keep the positive prompt concise up top, then add lens, lighting, and style cues. Use the negative prompt to suppress artifacts like extra limbs or noisy text; trim it if you find it overly restrictive for your concept.
EmptyHunyuanImageLatent (#29)#
Defines the working resolution and batch. The default 2048×2048 aligns with Hunyuan Image 2.1’s native 2K capability. For other aspect ratios, choose model‑friendly width and height pairs and consider increasing steps slightly if you move far from square.
KSampler (#3)#
Drives the denoising process with Hunyuan Image 2.1. Increase steps when you need finer micro‑detail, decrease for quick drafts. Raise guidance for stronger prompt adherence but watch for over‑saturation or rigidity; lower it for more natural variation. Switch seeds to explore compositions without changing your prompt.
UNETLoader (#37)#
Loads the Hunyuan Image 2.1 UNet. The included FP8 checkpoint keeps memory usage modest for 2K output. If you have ample VRAM and want maximum headroom for aggressive settings, consider a higher‑precision variant of the same model from the official releases.
VAELoader (#34) and VAEDecode (#8)#
These nodes must match the Hunyuan Image 2.1 release to decode correctly. The model’s high‑compression VAE is key to fast 2K generation; pairing the correct VAE avoids color shifts and blocky textures. If you change the base model, always update the VAE accordingly.
Optional extras#
- Prompting
- Hunyuan Image 2.1 responds well to structured prompts: subject, action, environment, camera, lighting, style. For text in image, quote the exact words you want and keep them brief.
- Speed and memory
- The FP8 UNet is already efficient. If you need to squeeze further, disable large batches and prefer fewer steps. Optional GGUF loader nodes are present in the graph but disabled by default; advanced users can swap them in when experimenting with quantized checkpoints.
- Aspect ratios
- Stick to native 2K‑friendly sizes for best results. If you venture to wide or tall formats, verify a clean render and consider a small step increase.
- Refinement
- Hunyuan Image 2.1 supports a refiner stage. To try it, add a second sampler after the base pass with a refiner checkpoint and a light denoise to preserve structure while boosting micro‑detail.
- References
- Hunyuan Image 2.1 model details and downloads: Hugging Face · GitHub
- Qwen2.5‑VL‑7B‑Instruct: Hugging Face
- ByT5 Small and paper: Hugging Face · Paper
Acknowledgements#
This workflow implements and builds upon the following works and resources. We gratefully acknowledge @Ai Verse and Hunyuan for Hunyuan Image 2.1 Demo for their contributions and maintenance. For authoritative details, please refer to the original documentation and repositories linked below.
Resources#
- Hunyuan/Hunyuan Image 2.1 Demo
- Docs / Release Notes: Hunyuan Image 2.1 Demo tutorial from @Ai Verse
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.

