
Gemma 4 テキスト生成 ComfyUI ワークフロー: イメージ、ビデオ、音声コンテキストを用いたマルチモーダルテキスト#
このGemma 4 テキスト生成 ComfyUIワークフローは、イメージと音声を理解しながら高品質のテキストを生成するコンパクトなRunComfy準備済みテンプレートであり、ビデオ例も含まれています。マルチモーダルプロンプト、製品レビューの要約、コンテンツ分析、ComfyUI内の軽量アシスタントプロトタイプの迅速な反復を目指しています。
このグラフは、ComfyUIのネイティブTextGenerateとCLIPLoaderを使用してGemma 4 E4Bを実行し、オプションのイメージ、音声、ビデオ入力を受け入れます。純粋なテキスト生成のためにシンプルに保つことも、メディアを接続してモデルの推論を導き、豊かな出力を生成することもできます。
Comfyui Gemma 4 テキスト生成 ComfyUIワークフローの主要モデル#
- Gemma 4 E4B 指示マルチモーダルモデル。視覚と音声の理解を伴うテキスト生成を提供し、簡潔な回答、要約、分析を行います。ComfyUI用のモデル資産は、コミュニティパックComfy-Org/gemma-4に整理されています。
- Gemma 4 E4B テキストエンコーダー (FP8 スケール)。ワークフローは、
TextGenerateノードの言語およびマルチモーダル入力をバックするパッケージ化されたエンコーダーの重みgemma4_e4b_it_fp8_scaled.safetensorsをロードします。ローカルユーザー向けの直接ファイルリンク: `text_encoders/gemma4_e4b_it_fp8_scaled.safetensors`.
Comfyui Gemma 4 テキスト生成 ComfyUIワークフローの使用方法#
全体のロジック: ワークフローはGemma 4エンコーダーをロードし、オプションのメディアを受け入れ、TextGenerateを使用してプレビューにレンダリングされる応答を生成します。テキストのみで実行するか、イメージと音声をプラグインして、例のグループを接続してビデオを拡張することもできます。
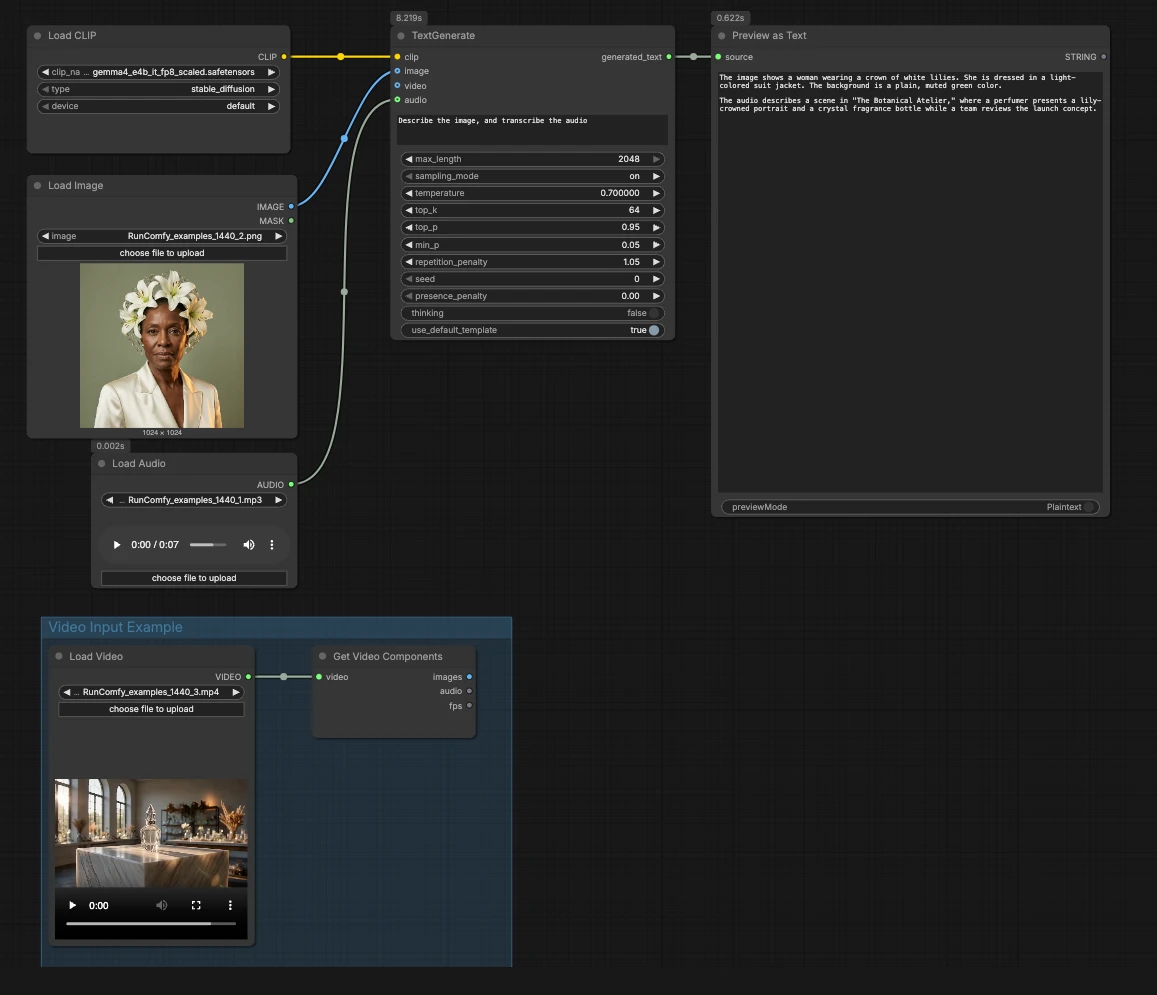
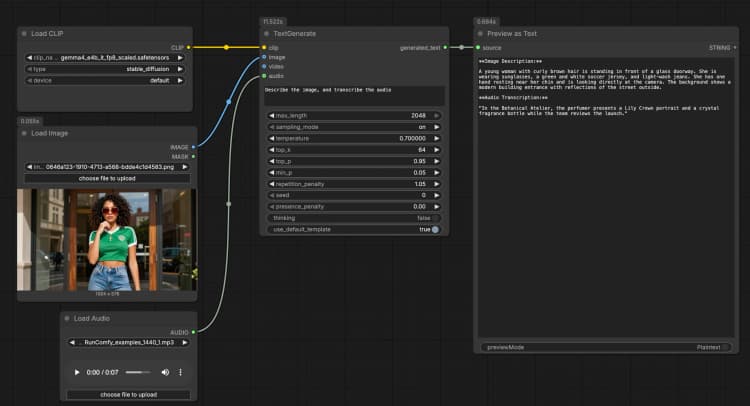
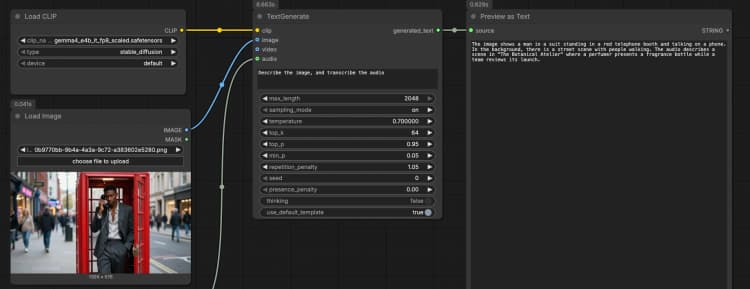
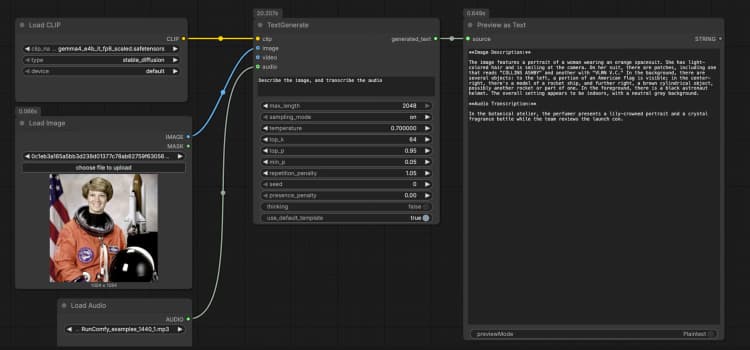
CLIPLoader(#3) ジェネレーターに必要なGemma 4 E4Bテキストエンコーダーをロードします。ローカルで実行する場合は、正しいトークナイザーとマルチモーダルエンコーダーを持つように、gemma4_e4b_it_fp8_scaled.safetensorsを選択します。管理環境では、通常正しいファイルが事前に選択されています。選択された重みが表示されたら、ここで何も調整する必要はありません。LoadImage(#2)を使用したイメージ入力 プロンプトの一部としてモデルが説明、OCR、または分析できる単一の参照イメージを提供します。例のファイルを自分のスクリーンショット、チャート、ドキュメント、または製品写真に置き換えます。イメージはTextGenerateに直接渡され、視覚コンテンツに基づいて応答が条件付けられます。テキストのみの動作を望む場合は、このノードを切断したままにしてください。LoadAudio(#5)を使用した音声入力 転写または音声に基づいた推論のために音声クリップを追加します。サンプルファイルをボイスノート、会議の抜粋、またはレビュー録音に置き換えます。音声ストリームはTextGenerateに供給され、イメージと一緒にそれを転写または要約するようモデルに依頼できます。テキストのみのタスクのためには、この入力を空にしておきます。- ビデオ入力例グループ “ビデオ入力例”グループは、
LoadVideo(#6)とGetVideoComponents(#7)を使用してビデオを同じフローに取り込む方法を示します。GetVideoComponentsは代表的なフレームとサウンドトラックを公開し、シーン、スライド、または画面上のテキストを分析できます。ビデオの理解を有効にするには、TextGenerateのimage入力にimages出力を接続し、audio入力にaudio出力を接続します。これにより、Gemma 4 テキスト生成 ComfyUI ワークフローはクリップからのフレームと音声を考慮することができます。 TextGenerate(#1)を用いたテキスト生成 これは、指示と任意の添付メディアを受け入れ、生成されたテキストを返すコアノードです。「イメージを説明し、音声を転写してから、2文の要約を書いてください」などの明確なプロンプトを提供します。このノードは視覚と音声のコンテキストを自動的に融合するため、プレースホルダーなしで自然な指示を書くことができます。使用ケースに応じてプロンプトを会話的またはタスク指向に保つことができます。PreviewAny(#4)を使用した結果の表示 生成されたテキストを表示し、メモや下流ツールにコピーすることができます。プロンプトを編集したりメディアを交換した後に再実行して、出力を迅速に比較します。このプレビューを使用して、各モダリティが回答にどれだけ影響を与えるかを検証します。
Comfyui Gemma 4 テキスト生成 ComfyUI ワークフローの主要ノード#
TextGenerate(#1) 最終出力を駆動し、ほとんどのチューニングが存在する場所です。応答がどれくらい長くなるか、どれくらい探求的に感じるかを、最大トークンとサンプリング温度を変更して調整します。回答の前により段階的な思考を望む場合は、オプションの推論モードを有効にします。実装の詳細については、ComfyUIテキスト生成ノードのソースコードをこちらでご覧ください。CLIPLoader(#3) テキストとマルチモーダル理解に必要なGemma 4 E4Bエンコーダーパッケージを選択してロードします。ローカルでモデルを維持する場合は、ファイルを以下に配置します: ComfyUI/models/text_encoders/gemma4_e4b_it_fp8_scaled.safetensors 選択後、モデルのバリアントを切り替えない限り、このノードを再訪する必要はほとんどありません。GetVideoComponents(#7) モデルにビデオを考慮させたい場合に便利です。フレームと音声を公開して、TextGenerateを両方に条件付けることができます。クリップが長い場合、迅速なターンアラウンドのためにフレームのセットを小さく選択します。より詳細が必要な場合は、スピードのコストでフレームサンプリングを増やします。
オプションの追加機能#
- 「添付されたイメージと音声を考慮してください」といった明確な指示で始めて、マルチモーダルグラウンディングを明確にします。
- 製品レビューの場合、利点、欠点、1文の評決を求めて出力を構造化します。
- タスクが純粋にテキストである場合、イメージと音声を切断して迅速に実行します。
- 実験をバッチ処理するには、異なるプロンプトで
TextGenerateノードを複製して、プレビューを並べて比較します。 - Gemma 4のモデルファイルとバリアントはコミュニティパックに整理されています。利用可能な資産をこちらで探索してください。
謝辞#
このワークフローは、以下の作品とリソースを実装し、基にしています。Gemma 4 ComfyUIモデルパッケージとE4BテキストエンコーダーのためのComfy-Org、組み込みのTextGenerateノードのためのComfy-Org (ComfyUIメンテナ)、公式Gemma 4チュートリアルとリリースブログのためのComfy.orgに心から感謝いたします。権威ある詳細については、以下にリンクされているオリジナルのドキュメントとリポジトリを参照してください。
リソース#
- ComfyUI ドキュメント/Gemma 4 ComfyUI ワークフロー例
- GitHub: Comfy-Org/ComfyUI
- Hugging Face: Comfy-Org/gemma-4
- ドキュメント / リリースノート: Gemma 4 ComfyUI ワークフロー例
- ComfyUI ブログ/新しいオープンソースモデルがComfyUIに登場: VOID, BiRefNet & Gemma 4
- GitHub: Comfy-Org/workflow_templates
- Hugging Face: Comfy-Org/gemma-4
- ドキュメント / リリースノート: 新しいオープンソースモデルがComfyUIに登場: VOID, BiRefNet & Gemma 4
- Comfy-Org/gemma-4
- Hugging Face: Comfy-Org/gemma-4
- Comfy-Org/gemma-4 E4B テキストエンコーダー
- Hugging Face: Comfy-Org/gemma-4: gemma4_e4b_it_fp8_scaled.safetensors
- Comfy-Org/ComfyUI TextGenerate ノード
注: 参照されたモデル、データセット、およびコードの使用は、それぞれの著者およびメンテナが提供するライセンスおよび条件に従います。

