
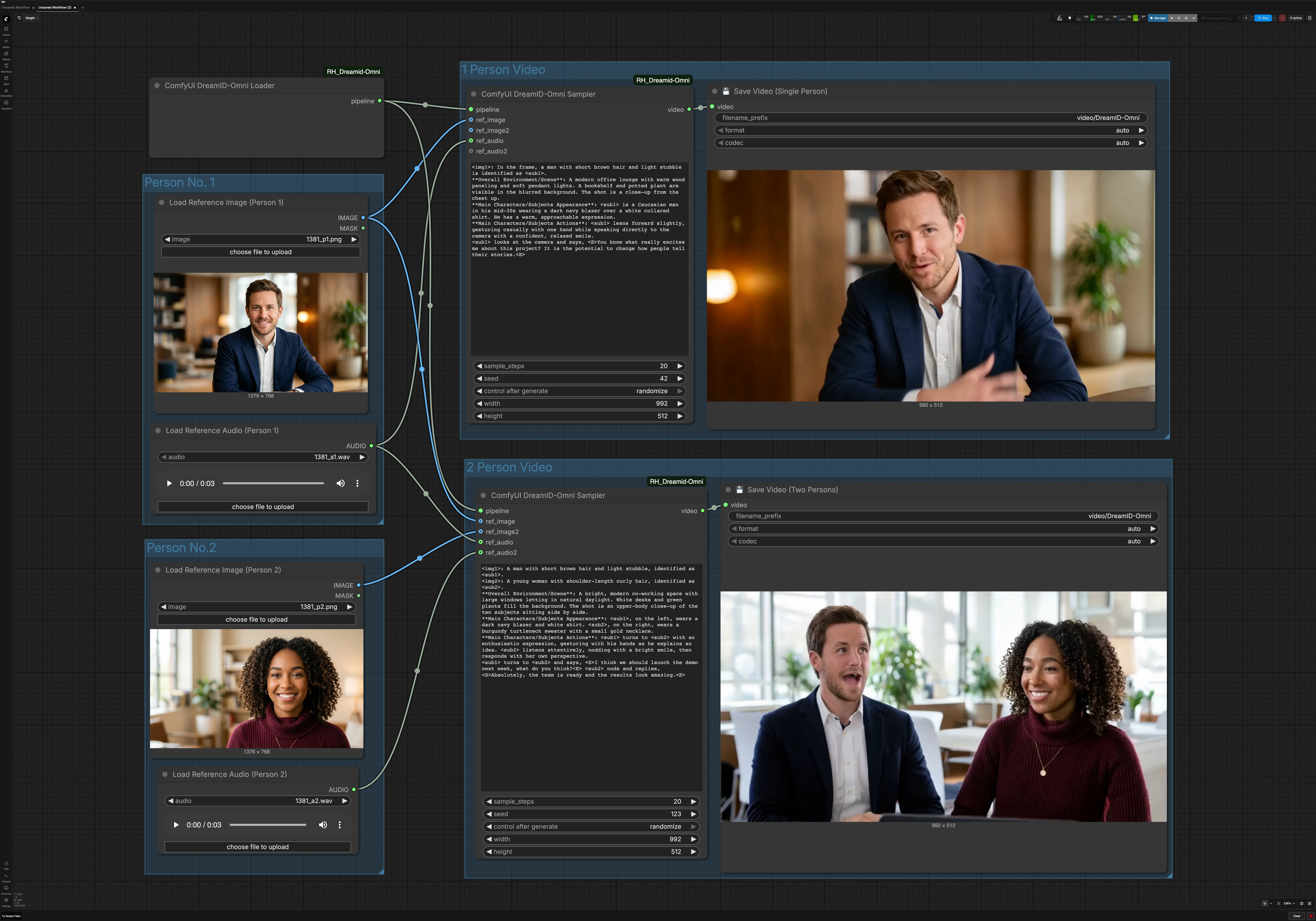
ComfyUI用DreamID-Omniシングル&デュアルキャラクタートーキングビデオワークフロー#
このワークフローは、1枚の参照写真と音声クリップをアイデンティティを保持するトーキングヘッドビデオに変換します。DreamID-Omniモデルによって駆動され、現代的なビデオバックボーンとMMAudio駆動のリップモーションを融合し、画像からの顔を保持しながら自然に話します。また、2人のキャラクターをサポートしており、2つの声に駆動される並列会話クリップを可能にします。
クリエイター、プロダクトチーム、研究者向けに設計されたComfyUIのDreamID-Omniワークフローは、デジタルアバター、パーソナライズされた発表、チュートリアルイントロ、およびAIダイアログシーンに最適です。写真と音声を提供し、オプションで短いプロンプトでショットを説明すると、グラフが共有準備の整った洗練されたビデオをレンダリングします。
Comfyui DreamID-Omniワークフローの主要モデル#
- DreamID-Omni。参照画像の人物をフレーム全体で保持し、音声に応じてリアルなリップムーブメントを実現するコアアイデンティティモジュール。詳細は公式リポジトリとウェイトを参照: DreamID-Omni および DreamID-Omni on Hugging Face。
- Wan 2.2ビデオ生成。高容量のビデオ拡散バックボーンであり、DreamID-Omniが顔のアイデンティティを操作する間、一貫した動き、照明、ショット構成を合成します。
- MMAudio。供給された音声に合わせて口の形と微妙な顔のキューを調整し、リップシンクのリアリズムを向上させる音声表現モデルです。
Comfyui DreamID-Omniワークフローの使用方法#
このグラフには2つの並列パスがあります。シングルパーソンパスは1枚の画像と1つの音声を使用します。2人のパスは2枚の画像と2つの音声を使用して会話クリップを生成します。共有のDreamID-Omniローダーが両方のパイプラインを初期化します。
人物1#
Load Reference Image (Person 1) (#6) を使用して、均一な照明と最小限の遮蔽のあるクリアな正面ポートレートを選択します。Load Reference Audio (Person 1) (#7) を使用して、キャラクターに話させたい音声を提供します。音声がクリーンであればあるほど、リップシンクが向上するため、音楽や強い背景ノイズのないスピーチを選びましょう。このペアはシングルパーソンモードと、2人モードが有効になっている場合には、左または最初の被写体に供給されます。
人物2#
対話を作成する際には、Load Reference Image (Person 2) (#9) と Load Reference Audio (Person 2) (#11) を使用します。コンポジションをバランス良く保つために、人物1のフレーミングに合った写真を選びます。2つ目の音声が1つ目と同じくらいの音量であることを確認し、急激な知覚シフトを避けます。シングルパーソンクリップのみを作成する場合、このグループを無視できます。
1人ビデオ#
シングルスピーカーパスは ComfyUI DreamID-Omni Sampler (#21) によって駆動されます。DreamID-Omniパイプラインを人物1の写真と音声と融合し、ノードのプロンプトエリアでの簡潔なシーン説明に従って一貫したショットをレンダリングします。プロンプトは背景、カメラ距離、態度を簡潔かつ実用的に記述してください。結果は 💾 Save Video (Single Person) (#4) によって書き出され、ファイルの名前とエクスポートが行われます。
2人ビデオ#
対話パスは ComfyUI DreamID-Omni Sampler (#22) を使用して1フレームに2つのアイデンティティを構成し、各口を対応する音声で駆動します。環境とインタラクションスタイルを設定する短いプロンプトを提供し、例えば共同作業スペース、カジュアルなトーン、誰が最初に話すかなどを指定します。これにより、カメラの配置とジェスチャーが安定し、DreamID-OmniとMMAudioがアイデンティティとリップアライメントを維持します。クリップは 💾 Save Video (Two Persons) (#5) によってエクスポートされます。
共有DreamID-Omniパイプライン#
ComfyUI DreamID-Omni Loader (#23) は両方のパスで使用されるDreamID-Omniコンポーネントを初期化します。通常、ここで調整する必要はありません。ウェイトとComfyUIノードが利用可能であれば、ローダーがパイプラインを準備し、サンプラーがレンダリングできるようにします。
Comfyui DreamID-Omniワークフローの主要ノード#
ComfyUI DreamID-Omni Loader (#23)#
DreamID-Omniパイプラインを初期化し、そのウェイトを下流のサンプラーで利用可能にします。ここには通常のユーザー入力はありません。複数のモデルバリアントを維持している場合は、レンダリングをキューに入れる前に正しいウェイトがインストールされていることを確認してください。
ComfyUI DreamID-Omni Sampler (#21)#
シングルパーソンレンダリング。このノードはローダーパイプラインを最初の参照画像と音声と組み合わせ、アイデンティティを保持するトーキングヘッドを合成します。プロンプトフィールドはシーンと態度を定義する場所です。シードは再現性を制御し、解像度はフレーミングと顔の詳細を決定し、ステップは速度と忠実度をトレードオフします。テイク全体で一貫した結果を得るために、同じシードを再利用し、プロンプトの変更を最小限に抑えてください。
ComfyUI DreamID-Omni Sampler (#22)#
2人のレンダリング。このインスタンスは2つの写真と2つの音声を受け入れ、それぞれの声をその対象にペアリングして同期されたリップムーブメントを生成します。プロンプトは会話とカメラレイアウトを設定できます。シングルパーソンモードと同様にシードと解像度を調整し、レンダリング前に両方の音声が希望するタイミングにトリミングされていることを確認してください。
💾 Save Video (Single Person) (#4)#
シングルスピーカー出力をディスクに書き込みます。フォルダまたはベース名を設定してバージョンを整理します。利用可能な場合は、コーデックとフレームレートのオプションを自動にしておいてください。
💾 Save Video (Two Persons) (#5)#
対話出力をディスクに書き込みます。シングルおよびデュアルパーソンクリップを区別しやすくするために、異なるベース名を使用します。特定の配信要件がない限り、信頼性のために自動エクスポート設定を維持してください。
オプションの追加#
- 参照画像内の顔がフレームの意味のある部分を占めるように大きく保ち、アイデンティティのロックを強化します。
- クリーンで整った音声を使用します。初めの静寂をトリミングして、最初の凍った唇を避けます。
- プロンプトや衣装を繰り返す際には、同じシードを再利用してより安定した外観を維持します。
- 2人の間隔が狭いと感じる場合は、プロンプトを言い換えてカメラを広げたり、肩のスペースを増やしたりすることで、顔をトリミングする代わりに対応します。
- アセットとアップデートについては、公式モデルとノードを参照してください: DreamID-Omni、ComfyUI_RH_Dreamid-Omni、および DreamID-Omni weights。
謝辞#
このワークフローは以下の作品やリソースを実装および構築しています。DreamID-Omniモデル/ワークフローのGuoxu1233、DreamID-Omni ComfyUIノードのHM-RunningHub、およびDreamID-OmniモデルウェイトのXuGuo699の貢献とメンテナンスに感謝します。権威ある詳細については、以下のリンクされたオリジナルのドキュメントとリポジトリを参照してください。
リソース#
- DreamID-Omni公式リポジトリ - https://github.com/Guoxu1233/DreamID-Omni
- GitHub: Guoxu1233/DreamID-Omni
- DreamID-Omni ComfyUIノード (RunningHub) - https://github.com/HM-RunningHub/ComfyUI_RH_Dreamid-Omni
- DreamID-Omniモデルウェイト (Hugging Face) - https://huggingface.co/XuGuo699/DreamID-Omni
- Hugging Face: XuGuo699/DreamID-Omni
注意: 参照されたモデル、データセット、コードの使用は、それぞれの著者および管理者によって提供されたライセンスおよび条件に従います。