
Wan2.2 S2V: Sound-to-Video from a Single Image in ComfyUI#
Wan2.2 S2V is a sound-to-video workflow that turns one reference image plus an audio clip into a synchronized video. It is built around the Wan 2.2 model family and designed for creators who want expressive motion, lip sync, and scene dynamics that follow sound or speech. Use Wan2.2 S2V for talking avatars, music-driven loops, and quick story beats without hand-animating.
This ComfyUI graph couples audio features with text prompts and a still image to generate a short clip, then muxes the frames with the original audio. The result is a compact, reliable pipeline that keeps the look of your reference image while letting the audio drive timing and expression.
Key models in Comfyui Wan2.2 S2V workflow#
- Wan 2.2 S2V UNet (14B, bf16). The core generator that fuses audio features, text conditioning, and a reference image to produce video latents.
- Wan VAE (wan_2.1_vae). Encodes/decodes between latent and pixel space to preserve detail and color fidelity in Wan2.2 S2V renders.
- UMT5-XXL text encoder. Provides prompt conditioning for style and content; see the base model card for reference: google/umt5-xxl.
- Wav2Vec2 Large audio encoder. Extracts robust speech and rhythm features for sound-conditioned generation; see an archetypal card such as facebook/wav2vec2-large-960h.
How to use Comfyui Wan2.2 S2V workflow#
The workflow is organized into three groups. You can run them end-to-end or adjust each stage as needed.
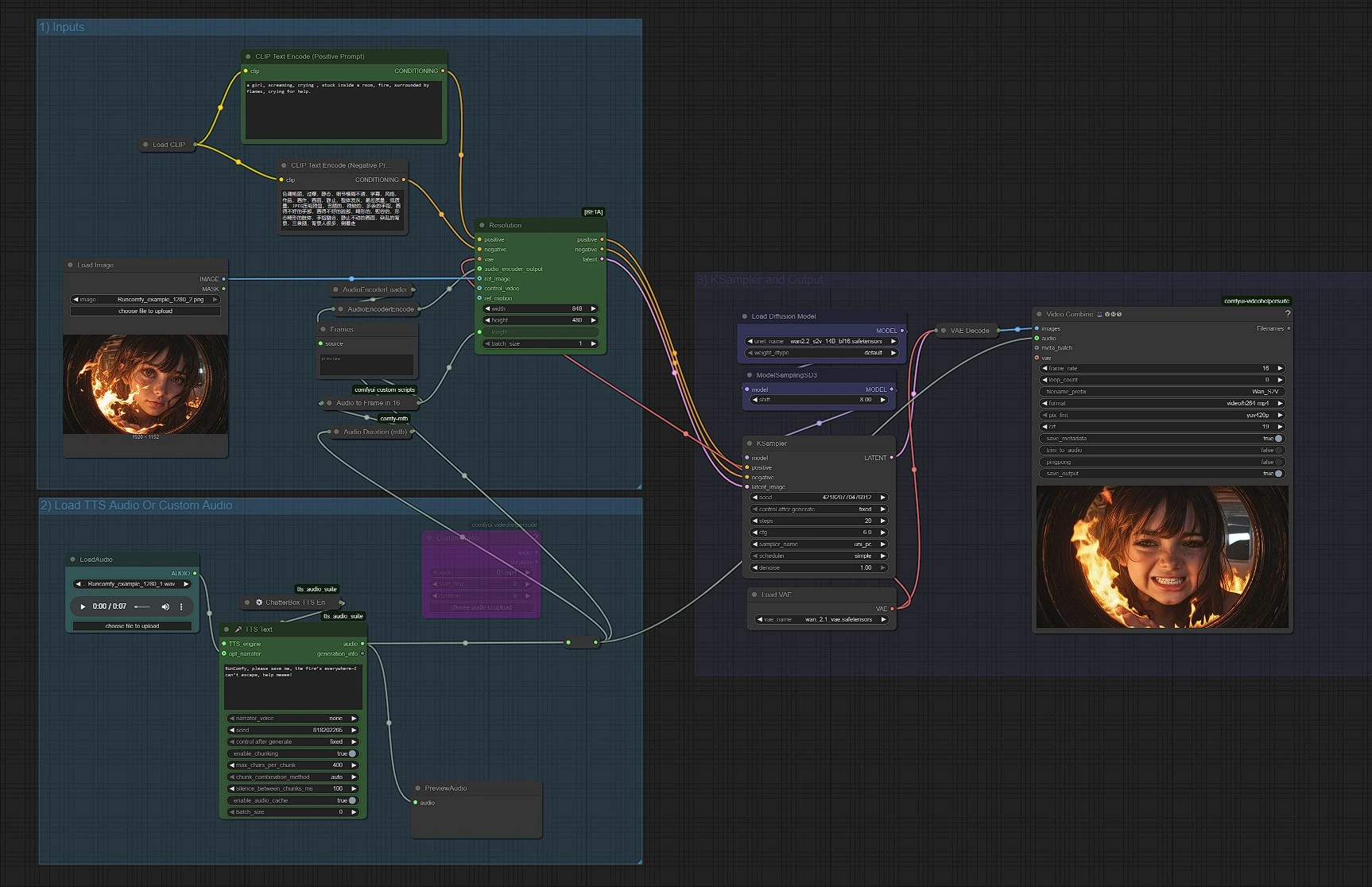
1) Inputs#
This group loads Wan’s text, image, and VAE components, and prepares your prompts. Use CLIPLoader (#38) with CLIPTextEncode (#6) for the positive prompt and CLIPTextEncode (#7) for the negative prompt to steer style and quality. Load your reference image with LoadImage (#52); this anchors identity, framing, and palette for Wan2.2 S2V. Keep positive prompts descriptive but brief so the audio retains control over motion. The VAE (VAELoader (#39)) and model loader (UNETLoader (#37)) are prewired and usually left as is.
2) Load TTS Audio Or Custom Audio#
Choose how you provide audio. For quick tests, generate speech with UnifiedTTSTextNode (#71) and preview with PreviewAudio (#65). To use your own music or dialogue, either LoadAudio (#78) for local files or VHS_LoadAudioUpload (#87) for uploads; both feed a Reroute (#88) so downstream nodes see a single audio source. The duration is measured by Audio Duration (mtb) (#68), then converted to a frame count by MathExpression|pysssss (#67) labeled “Audio to Frame in 16 FPS.” The audio features are produced by AudioEncoderLoader (#57) and AudioEncoderEncode (#56), which together supply the Wan2.2 S2V node with an AUDIO_ENCODER_OUTPUT.
3) KSampler and Output#
WanSoundImageToVideo (#55) is the heart of Wan2.2 S2V. It consumes your prompts, VAE, audio features, reference image, and a length integer (frames) to emit a conditioned latent sequence. That latent goes to KSampler (#3), whose sampler settings govern overall coherence and detail while respecting the audio-driven timing. The sampled latent is decoded by VAEDecode (#8) into frames, then VHS_VideoCombine (#66) assembles the video and muxes your original audio to produce an MP4. ModelSamplingSD3 (#54) is used to set the correct sampler family for the Wan backbone.
Key nodes in Comfyui Wan2.2 S2V workflow#
WanSoundImageToVideo (#55)#
Drives audio-synchronized motion from a single image. Set ref_image to the portrait or scene you want animated, connect audio_encoder_output from the encoder, and provide a length in frames. Increase length for longer clips or reduce for snappier previews. If you change FPS elsewhere, update the frames value accordingly so timing stays in sync.
AudioEncoderLoader (#57) and AudioEncoderEncode (#56)#
Load and run the Wav2Vec2-based encoder that turns speech or music into features Wan can follow. Use clean speech for lip sync, or percussive/beat-heavy audio for rhythmic motion. If your input language or domain differs, swap in a compatible Wav2Vec2 checkpoint to improve alignment.
CLIPTextEncode (#6) and CLIPTextEncode (#7)#
Positive and negative prompt encoders for UMT5/CLIP conditioning. Keep positive prompts concise, focusing on subject, style, and shot terms; use negative prompts to avoid unwanted artifacts. Overly forceful prompts can fight the audio, so prefer light guidance and let Wan2.2 S2V handle motion.
KSampler (#3)#
Samples the latent sequence produced by the Wan2.2 S2V node. Adjust sampler type and steps to trade speed for fidelity; keep a fixed seed when you want reproducible timing with the same audio. If motion feels too rigid or noisy, small changes here can noticeably improve temporal stability.
VHS_VideoCombine (#66)#
Creates the final video and attaches the audio. Set frame_rate to match your intended FPS and confirm the clip length matches your length frames. The container, pixel format, and quality controls are exposed for quick exports; use higher quality when you plan to post-process in an editor.
Optional extras#
- Start with a well-lit, front-facing reference image at your target aspect ratio to minimize identity drift and cropping.
- For lip sync, keep the mouth unobstructed and use clean narration; music with strong transients works well for beat-driven motion.
- The default FPS conversion assumes 16 fps; if you change FPS, update the math in “Audio to Frame in 16 FPS” so frames align with audio duration.
- Use the audio preview and VHS live preview to iterate quickly, then raise quality once you like the timing.
- Longer clips scale compute and VRAM; trim silence or split long scripts into short scenes when producing multi-shot videos with Wan2.2 S2V.
Acknowledgements#
This workflow implements and builds upon the following works and resources. We gratefully acknowledge Wan-Video for Wan2.2 (including S2V inference code), Wan-AI for Wan2.2-S2V-14B, and Gao et al. (2025) for Wan-S2V: Audio-Driven Cinematic Video Generation for their contributions and maintenance. For authoritative details, please refer to the original documentation and repositories linked below.
Resources#
- Wan-Video/Wan2.2 S2V Demo
- GitHub: Wan-Video/Wan2.2
- Hugging Face: Wan-AI/Wan2.2-S2V-14B
- arXiv: Wan-S2V: Audio-Driven Cinematic Video Generation
- Docs / Release Notes: Wan2.2 S2V Demo
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.

