
⚠️ Important Note: This ComfyUI MultiTalk implementation currently supports SINGLE-PERSON generation only. Multi-person conversational features will be coming soon.
1. What is MultiTalk?#
MultiTalk is a revolutionary framework for audio-driven multi-person conversational video generation developed by MeiGen-AI. Unlike traditional talking head generation methods that only animate facial movements, MultiTalk technology can generate realistic videos of people speaking, singing, and interacting while maintaining perfect lip synchronization with audio input. MultiTalk transforms static photos into dynamic speaking videos by making the person speak or sing exactly what you want them to say.
2. How MultiTalk Works#
MultiTalk leverages advanced AI technology to understand both audio signals and visual information. The ComfyUI MultiTalk implementation combines MultiTalk + Wan2.1 + Uni3C for optimal results:
Audio Analysis: MultiTalk uses a powerful audio encoder (Wav2Vec) to understand the nuances of speech, including rhythm, tone, and pronunciation patterns.
Visual Understanding: Built on the robust Wan2.1 video diffusion model (you can visit our Wan2.1 workflow for t2v/i2v eneration), MultiTalk understands human anatomy, facial expressions, and body movements.
Camera Control: MultiTalk with Uni3C controlnet enables subtle camera movements and scene control, making the video more dynamic and professional-looking. Check out our Uni3C workflow for creating beautiful camera motion transfer.
Perfect Synchronization: Through sophisticated attention mechanisms, MultiTalk learns to perfectly align lip movements with audio while maintaining natural facial expressions and body language.
Instruction Following: Unlike simpler methods, MultiTalk can follow text prompts to control the scene, pose, and overall behavior while maintaining audio synchronization.
3. Benefits of ComfyUI MultiTalk#
- High-Quality Lip Sync: MultiTalk achieves millisecond-level precision in lip synchronization, especially impressive for singing scenarios
- Versatile Content Creation: MultiTalk supports both speaking and singing generation with various character types including cartoon characters
- Flexible Resolution: MultiTalk generates videos in 480P or 720P at arbitrary aspect ratios
- Long Video Support: MultiTalk creates videos up to 15 seconds in length
- Instruction Following: MultiTalk controls character actions and scene settings through text prompts
4. How to Use the ComfyUI MultiTalk Workflow#
Step-by-Step MultiTalk Usage Guide#
Step 1: Prepare Your MultiTalk Inputs
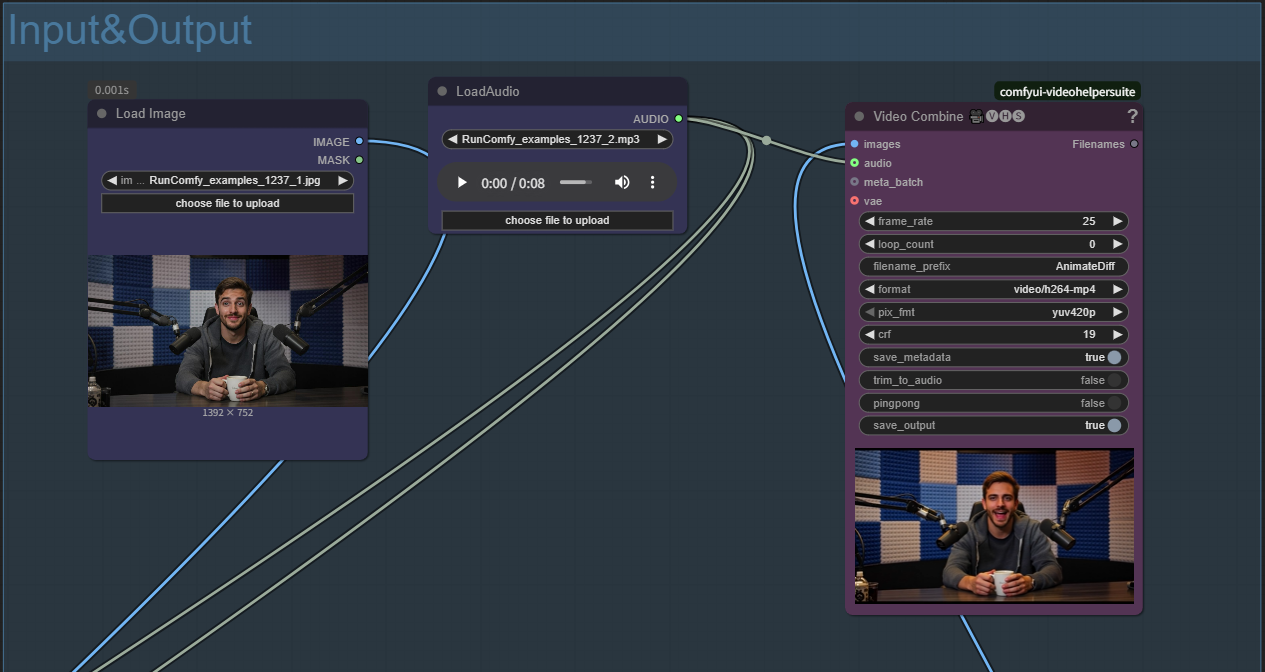
- Upload Reference Image: Click "choose file to upload" in Load Image node
- Use clear, front-facing photos for best MultiTalk results
- Image will be automatically resized to optimal dimensions (832px recommended)
- Upload Audio File: Click "choose file to upload" in LoadAudio node
- MultiTalk supports various audio formats (WAV, MP3, etc.)
- Clear speech/singing works best with MultiTalk
- For creating custom songs, consider using our Ace-Step music generation workflow, which produces high-quality music with synchronized lyrics.
- Write Text Prompt: Describe your desired scene in the text encode nodes for MultiTalk generation
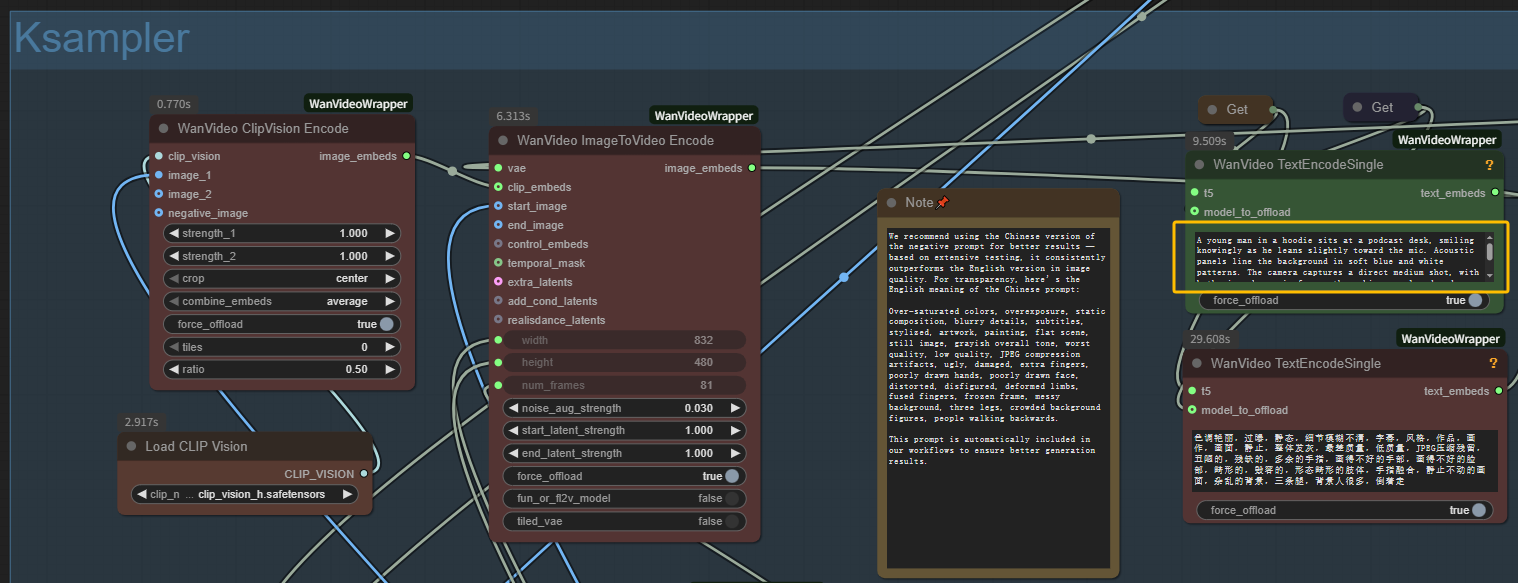
Step 2: Configure MultiTalk Generation Settings
- Sampling Steps: 20-40 steps (higher = better MultiTalk quality, slower generation)
- Audio Scale: Keep at 1.0 for optimal MultiTalk lip sync
- Embed Cond Scale: 2.0 for balanced MultiTalk audio conditioning
- Camera Control: Enable Uni3C for subtle movements, or disable for static MultiTalk shots
Step 3: Optional MultiTalk Enhancements
- LoRA Acceleration: Enable for faster MultiTalk generation with minimal quality loss
- Video Enhancement: Use enhance nodes for MultiTalk post-processing improvements
- Negative Prompts: Add unwanted elements to avoid in MultiTalk output (blurry, distorted, etc.)
Step 4: Generate with MultiTalk
- Queue the prompt and wait for MultiTalk generation
- Monitor VRAM usage (48GB recommended for MultiTalk)
- MultiTalk generation time: 7-15 minutes depending on settings and hardware
5. Acknowledgements#
Original Research: MultiTalk is developed by MeiGen-AI with collaboration from leading researchers in the field. The original paper "Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation" presents the groundbreaking research behind this technology.
ComfyUI Integration: The ComfyUI implementation is provided by Kijai through the ComfyUI-WanVideoWrapper repository, making this advanced technology accessible to the broader creative community.
Base Technology: Built upon the Wan2.1 video diffusion model and incorporates audio processing techniques from Wav2Vec, representing a synthesis of cutting-edge AI research.
6. Links and Resources#
- Original Research: MeiGen-AI MultiTalk Repository
- Project Page: https://meigen-ai.github.io/multi-talk/
- ComfyUI Integration: ComfyUI-WanVideoWrapper