
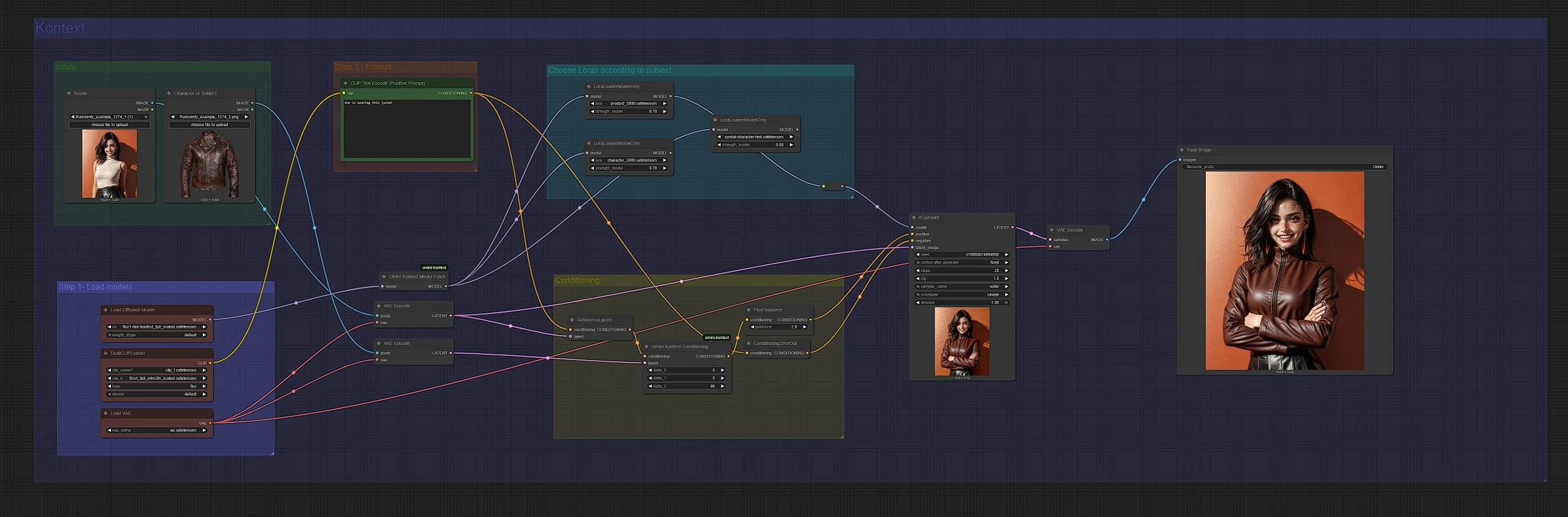





ComfyUI 用 Omni Kontext イメージ構成ワークフロー#
このワークフローは、Omni Kontext を使用して、強力なアイデンティティとコンテキストの保持を行いながら、新しいシーンに被写体を追加することができます。Flux Omni Kontext モデルパッチとリファレンスガイド付きコンディショニングを組み合わせることで、提供されたキャラクターや製品がプロンプトを尊重しながらターゲット背景に自然に溶け込むようにします。標準の Flux パスと、量子化されたウェイトでより高速かつメモリーフレンドリーなサンプリングを行う Nunchaku パスの 2 つの並行パスが含まれています。
一貫したブランド資産、製品の交換、またはキャラクターの配置を希望するクリエイターに特に役立ちます。クリーンな被写体画像、シーン画像、および短いプロンプトを提供すると、グラフがコンテキスト抽出、ガイダンス、LoRA スタイリング、およびデコードを処理し、一貫した合成物を生成します。
Comfyui Omni Kontext ワークフローの主要モデル#
- FLUX.1 Dev – 生成に使用されるディフュージョントランスフォーマーバックボーンです。コンテキスト認識の構成に適した強力なプロンプト準拠と現代的なサンプラーの動作を提供します。 Model card
- Flux テキストエンコーダー (CLIP-L と T5-XXL) – FLUX に適したコンディショニングにテキストをトークン化し、埋め込むペアリングエンコーダーです。ワークフローは、Flux に最適化された
clip_l.safetensorsおよびt5xxlのバリアントを読み込みます。 Encoders - Omni Kontext ノード – モデルとコンディショニングをパッチして、最終的なガイダンスストリームに被写体の潜在情報からコンテキストを注入するカスタムノードです。 Repository
- Nunchaku Flux DiT – スピードと低い VRAM を維持しながら品質を競争力のあるものに保つために、FP16/BF16 および INT4 量子化された FLUX ウェイトをサポートするオプションのローダーです。 Repository
- Lumina VAE – 被写体とシーン画像をエンコードし、最終出力をデコードするために使用される堅牢な VAE です。ワークフローは、Lumina Image 2.0 から再パッケージ化された
ae.safetensorsを参照します。 VAE
Comfyui Omni Kontext ワークフローの使用方法#
グラフには 2 つのミラーリングされたレーンがあります: 上のレーンは標準の Flux Omni Kontext パスで、下のレーンは Nunchaku パスです。どちらも被写体画像とシーン画像を受け入れ、コンテキスト認識のコンディショニングを構築し、Flux でサンプルを作成して合成物を生成します。
入力#
クリーンな被写体ショットとターゲットシーンの 2 つの画像を提供します。被写体は、アイデンティティ転送を最大化するために、よく照らされ、中心に位置し、障害物のない状態にする必要があります。シーンは、意図したカメラアングルと照明に大まかに一致している必要があります。「Character or Subject」と「Scene」とラベル付けされたノードにロードし、プロンプトを繰り返す間に一貫性を保ちます。
モデルの読み込み#
標準レーンは、UNETLoader (#37) を使用して Flux を読み込み、OminiKontextModelPatch (#194) で Omni Kontext モデルパッチを適用します。Nunchaku レーンは、NunchakuFluxDiTLoader (#217) を使用して量子化された Flux モデルを読み込み、NunchakuOminiKontextPatch (#216) を適用します。両方のレーンは、DualCLIPLoader (#38) を介して同じテキストエンコーダーを共有し、VAELoader (#39 または #204) を介して同じ VAE を共有します。LoRA スタイルやアイデンティティを使用する予定がある場合は、サンプリング前にこのセクションで接続を維持してください。
プロンプト#
システムに被写体に対して何をするかを指示する簡潔なプロンプトを書きます。上のレーンでは、CLIP Text Encode (Positive Prompt) (#6) が挿入またはスタイリングを駆動し、下のレーンでは CLIP Text Encode (Positive Prompt) (#210) が同じ役割を果たします。「キャラクターを画像に追加する」または「彼女がこのジャケットを着ている」などのプロンプトが効果的です。過度に長い説明は避け、変更または維持したい重要な要素に集中してください。
コンディショニング#
各レーンは、VAEEncode を使用して被写体とシーンを潜在情報にエンコードし、ReferenceLatent と OminiKontextConditioning (#193 上のレーン、#215 下のレーン) を介してテキストと融合します。これは、リファレンスからの意味のあるアイデンティティと空間的な手がかりをコンディショニングストリームに注入する Omni Kontext ステップです。その後、FluxGuidance (#35 上、#207 下) がモデルが合成コンディショニングにどの程度従うかを設定します。ネガティブプロンプトは ConditioningZeroOut (#135, #202) で簡略化されるため、避けるべきものよりも望むものに焦点を当てることができます。
被写体に応じた Loras を選択#
被写体が LoRA から利益を得る場合は、サンプリング前に接続します。標準レーンは LoraLoaderModelOnly (#201 およびコンパニオン) を使用し、Nunchaku レーンは NunchakuFluxLoraLoader (#219, #220, #221) を使用します。被写体のアイデンティティや衣装の一貫性に LoRA を使用し、アートディレクションにスタイル LoRA を使用します。シーンのリアリズムを保持しながら被写体の特性を強制するために、強度を適度に保ちます。
Nunchaku#
より速い反復を行いたい場合や VRAM が限られている場合は、Nunchaku グループに切り替えます。NunchakuFluxDiTLoader (#217) は、メモリを大幅に削減する INT4 設定をサポートし、NunchakuOminiKontextPatch (#216) を介して「Flux Omni Kontext」動作を維持します。同じプロンプト、入力、LoRA を使用し、KSampler (#213) でサンプルを作成し、VAEDecode (#208) でデコードして結果を保存します。
Comfyui Omni Kontext ワークフローの主要ノード#
OminiKontextModelPatch (#194)#
リファレンスコンテキストがサンプリング時に尊重されるように Flux バックボーンに Omni Kontext モデルの変更を適用します。被写体のアイデンティティと空間的な手がかりを生成に持ち込む場合は、常に有効にしておきます。キャラクターまたは製品の LoRA を使用する場合は、パッチと LoRA が競合しないように、適度な LoRA 強度とペアリングします。
OminiKontextConditioning (#193, #215)#
被写体とシーンからのリファレンス潜在情報とテキストコンディショニングを統合します。アイデンティティがずれる場合は、被写体のリファレンスへの重点を増やし、シーンが上書きされる場合は少し減らします。このノードは Omni Kontext 構成の中心であり、入力がクリーンであれば通常は小さな微調整だけで済みます。
FluxGuidance (#35, #207)#
モデルが合成コンディショニングにどの程度厳密に従うかを制御します。値が高いほど、プロンプトとリファレンスに近づきますが、スパントネイティが犠牲になります。シーンと調和しない焼き過ぎたテクスチャや損失が見られる場合は、ここで少し減らしてみてください。
NunchakuFluxDiTLoader (#217)#
スピードと低メモリのために量子化された Flux DiT バリアントを読み込みます。INT4 を選択して速く見て、FP16 または BF16 を最終品質に使用します。Nunchaku レーンで LoRA サポートが必要な場合は NunchakuFluxLoraLoader と組み合わせてください。
オプションの追加機能#
- VAE エンコード中にアイデンティティキャプチャを改善するために、クリーンな背景を持つタイトな被写体クロップを使用します。
- プロンプトを短く具体的に保ちます。「製品をテーブルに追加する」を長いスタイルリストよりも好みます。
- 被写体が貼り付けられたように見える場合は、LoRA の強度を少し下げ、ガイダンスを少し減らして、シーンが照明と視点を再主張できるようにします。
- スピードラウンドには、Nunchaku レーンで反復し、その後、最終レンダリングのために標準の Flux Omni Kontext レーンに戻ります。
- うまくいった中間シードをいくつか保存し、LoRA の強度とガイダンスを微調整する間に再利用できるようにします。
謝辞#
- Saquib764 による Omni Kontext。このワークフローは、ComfyUI における Flux Omni Kontext 構成を可能にするために、プロジェクトからのコンセプトとコンポーネントを適応しています。 Repository


