
ComfyUI MOSS TTS: テキストから音声へ、ボイスクローン、SFX、ダイアログを一つのワークフローで#
このComfyUI MOSS TTSワークフローは、OpenMOSS MOSS-TTSファミリーを使用してテキストを鮮やかな24kHz音声に変換します。高速な単一スピーカー合成、短い参照クリップからのゼロショットボイスクローン、記述的な声のデザイン、手続き型サウンドエフェクト、オプションのスピーカーごとの参照を利用したマルチスピーカーダイアログをカバーします。
公式のMOSS-TTSノードスタックとモデルファミリーに基づいて構築され、速度と品質のバランスを取っています。Local 1.7Bパスは単一GPUでの実用的な高速レーンであり、より大きなDelay 8Bモデルは速度を犠牲にしても広範な能力と表現力を提供します。再利用可能なプロンプト、クローンされた声、またはComfyUI内でのダイアログが必要な場合、このComfyUI MOSS TTSワークフローはあなたのために設計されています。
Comfyui ComfyUI MOSS TTSワークフローの主なモデル#
- OpenMOSS MOSS-TTS Local 1.7B。単一GPUに優しいテキストから音声へのトランスフォーマーで、日常の制作作業において高速で自然な24kHz音声を提供します。モデルカード: MOSS-TTS-Local-Transformer。
- OpenMOSS MOSS-TTS Delay 8B。品質、スピーカーの類似性、プロソディを重視したより大きなモデルラインで、速度とメモリを犠牲にしています。モデルカード: MOSS-TTS。
- MOSS Audio Tokenizer。MOSS-TTSモデルのために波形と離散トークンを橋渡しする学習済みコーデックで、高忠実度のデコードを可能にします。モデルカード: MOSS-Audio-Tokenizer。
実装の詳細と更新については、公式リポジトリをご覧ください: OpenMOSS/MOSS-TTS およびこのワークフローを支えるノードスタック richservo/comfyui-moss-tts。
Comfyui ComfyUI MOSS TTSワークフローの使い方#
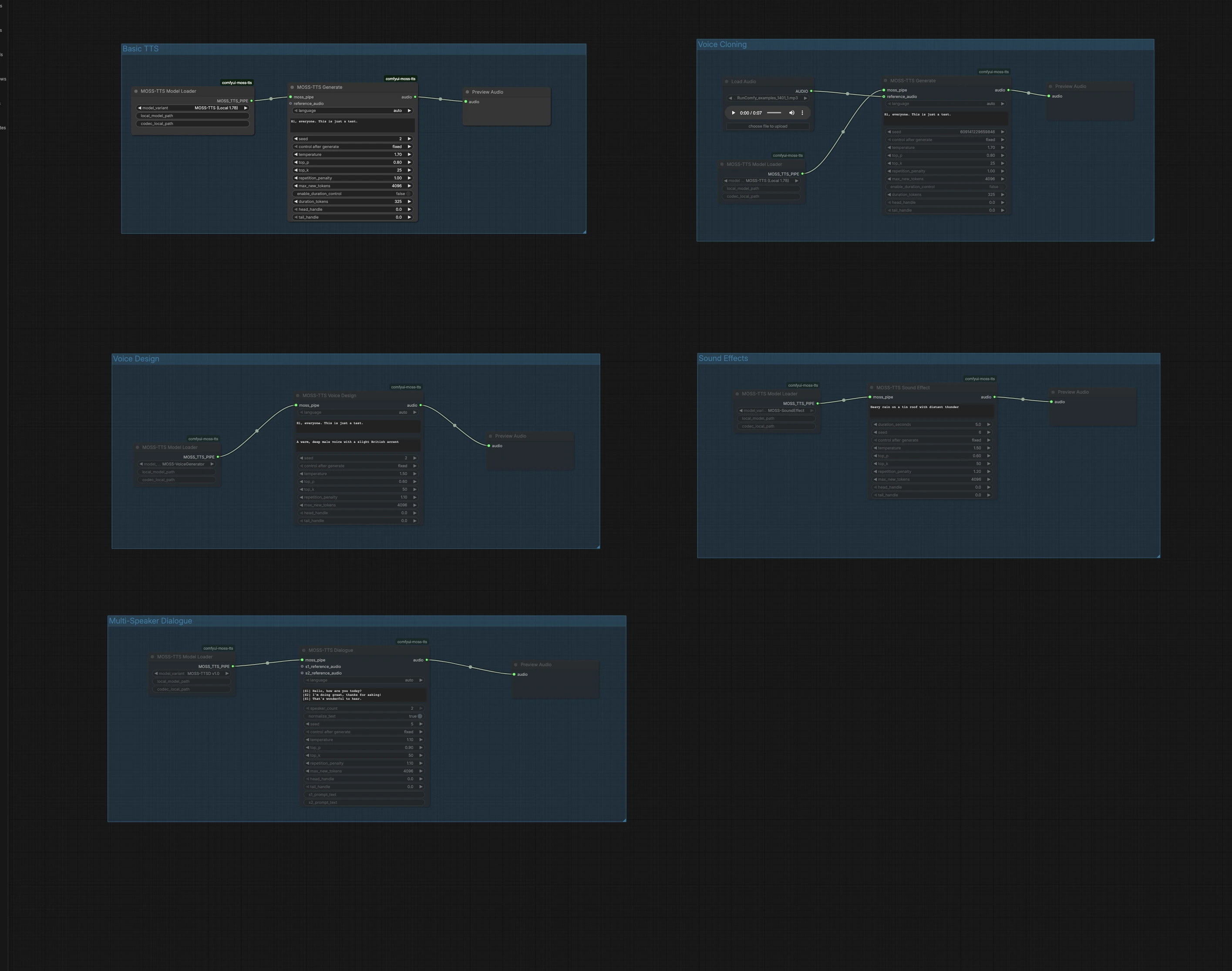
このグラフは5つの独立したグループに編成されています。目標に合ったグループを選択し、実行して、キャンバス内でオーディオをプレビューします。異なるアプローチを試すために複数のグループを並行して実行することができます。
Basic TTS#
Basic TTSグループは、Local 1.7Bの高速パスを使用してプレーンテキストを音声に変換します。MossTTSModelLoader (#1)でモデルをロードし、MossTTSGenerate (#2)にテキストを入力し、PreviewAudio (#3)で聴きます。ジェネレーターはあなたのプロンプトに基づいて発音とプロソディを形作るので、ペースを取るために自然に句読点を用いて書いてください。繰り返し可能なテイクが必要な場合はシードを固定し、デリバリーのバリエーションを探るときはランダム化します。
Voice Cloning#
Voice Cloningグループは、短い参照音声クリップからのゼロショットボイスクローンを実行します。LoadAudio (#4)を使用してクリーンな音声サンプルをインポートし、MossTTSModelLoader (#5)に駆動されるMossTTSGenerate (#6)に接続し、ターゲットテキストを提供します。モデルは参照からスピーカーの音色とスタイルを抽出し、その声で新しいスクリプトをレンダリングします。類似性を高めるために、参照では中立的なコンテンツと最小限のバックグラウンドノイズを使用し、最速のターンアラウンドのために持続時間を適度に保ちます。
Voice Design#
Voice Designでは、例のクリップではなく自然言語の説明から新しい声を作成します。MossTTSVoiceDesign (#9)は、「暖かく、深みのある男性の声で、わずかに英国のアクセントがある」といったテキスト説明とスクリプトを組み合わせて24kHz音声を合成します。このノードはMossTTSModelLoader (#8)を通じてロードされた専用のボイスジェネレーターパスで動作します。実際の録音をソースすることなく一貫した再現可能なペルソナが必要な場合に理想的です。音色、年齢、アクセント、エネルギーなどの特性を使ってサウンドを調整する説明を洗練します。
Sound Effects#
Sound Effectsは、ベッドトラック、トランジション、またはアンビエントレイヤーに役立つ非音声オーディオをテキストプロンプトから生成します。MossTTSSoundEffect (#12)とそのモデルパイプをMossTTSModelLoader (#11)から使って「遠くで雷が鳴るトタン屋根の上の激しい雨」のようなプロンプトで豊かでループ可能なテクスチャを生成します。シーンを定義するために簡潔な名詞と動作を使用し、強度や距離を釘付けにするために少し形容詞を追加します。PreviewAudio (#13)でプレビューし、ミックスに合うように素早く繰り返し調整します。
Multi-Speaker Dialogue#
Multi-Speaker Dialogueグループは、オプションのスピーカーごとの参照クリップを使用してスクリプト化された会話をレンダリングします。MossTTSDialogue (#15)の下でモデルパイプからMossTTSModelLoader (#14)にスクリプトを渡し、例として[S1] こんにちは。や[S2] やあ!のようにブラケット付きのスピーカータグを使用して書きます。それぞれの役割に対して特定の声をクローンするために参照オーディオ入力をアタッチするか、テキストコンテキストからモデルが異なるスピーカーを選ぶように空のままにします。このパスは、コールアンドレスポンス、キャラクターライン付きのナレーション、または音声UIモックアップに適しています。
Comfyui ComfyUI MOSS TTSワークフローの主なノード#
MossTTSModelLoader (#1)#
選択したOpenMOSSモデルファミリーをロードし、内部TTSパイプラインを組み立てます。単一GPUでの高速な反復のためにLocal 1.7Bバリアントを選択するか、表現力と類似性を優先する場合はより大きなDelay 8Bモデルに切り替えます。各タスクファミリーごとに1つのローダーを保持し、各ダウンストリームブランチが自己完結するようにします。
MossTTSGenerate (#2)#
テキストプロンプトとオプションの参照オーディオを消費して24kHz音声を生成するメインの単一スピーカーシンセサイザーです。より明確なペーシングのためにクリーンで句読点のあるテキストを提供し、ゼロショットクローンが必要な場合は短い音声クリップを接続します。再現性と探求のバランスを取るためにシードを固定とランダムの間で切り替えます。
MossTTSVoiceDesign (#9)#
話すテキストとともに記述的なプロンプトから新しい声を生成します。音色、年齢、アクセント、エネルギーに焦点を当ててアイデンティティを導く一方、簡潔に保ちます。実際の声をライセンスまたはソースすることが実用的でないときに強力な選択です。
MossTTSSoundEffect (#12)#
短いテキストの説明から非言語音声を合成します。ソース、アクション、スペースを固定するコンパクトなプロンプトを書き、シーンに合うように繰り返し調整します。アンビエンスやワンショットに最適で、同じComfyUI MOSS TTSグラフ内でダイアログに使用します。
MossTTSDialogue (#15)#
ブラケット付きのスピーカータグを解析し、マルチターンの会話を単一の音声出力としてレンダリングします。各行をマークするために[S1]、[S2]などを使用し、各ターン間でアイデンティティを保持するためにスピーカーごとの参照クリップをオプションで接続します。スピーカー間の最も信頼性のあるハンドオフのために行を簡潔に保ちます。
オプションの追加#
- Local 1.7Bモデルでクイックドラフトを開始し、より強い類似性や豊かなプロソディが必要な場合はDelay 8Bチェックポイントに切り替えます。
- ゼロショットクローンには、音色転送を改善するために最小限のリバーブとノイズでクリーンな5–15秒の声クリップを使用します。
- ダイアログでは、解析エラーを避けるために
[S1]のようにスピーカータグを一貫性を持たせ、句読点を避けます。 - 予測可能な結果のために、音色、年齢、アクセント、スタイル、エネルギーなどの3〜6の特性を持つボイスデザインプロンプトを作成します。
- ComfyUI MOSS TTSの出力でポーズとペーシングを制御するためにテキストに句読点と改行を追加します。
- バッチレンダリングの自動ファイルエクスポートが必要な場合は、プレビュー後に
SaveAudioノードを追加します。
参考文献: OpenMOSS/MOSS-TTS • MOSS-TTS-Local-Transformer • MOSS-TTS • MOSS-Audio-Tokenizer • comfyui-moss-tts
謝辞#
このワークフローは、以下の作品とリソースを実装および構築しています。私たちは、ComfyUI MOSS-TTSのカスタムノードを提供したrichservo、MOSS-TTSリポジトリを提供したOpenMOSS、MOSS-TTSモデル(Delay 8BおよびLocal 1.7B)およびMOSS Audio Tokenizerを提供したOpenMOSS-Teamの貢献とメンテナンスに感謝します。権威ある詳細については、以下にリンクされたオリジナルのドキュメントとリポジトリを参照してください。
リソース#
- richservo/comfyui-moss-tts
- GitHub: richservo/comfyui-moss-tts
- OpenMOSS/MOSS-TTS
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-TTS (Delay 8B)
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-TTS-Local-Transformer (Local 1.7B)
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS-Local-Transformer
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-Audio-Tokenizer
- Hugging Face: OpenMOSS-Team/MOSS-Audio-Tokenizer
- arXiv: 2602.10934
注意: 参照されているモデル、データセット、およびコードの使用は、それぞれの著者および管理者によって提供されるライセンスと条件に従います。
