
Flujo de trabajo IndexTTS2 ComfyUI: Clonación de voz emocional con audio de referencia#
Este flujo de trabajo IndexTTS2 ComfyUI convierte un clip de referencia corto en un discurso natural y expresivo que coincide con el timbre y estilo del hablante. Proporcionas audio de referencia limpio, indicaciones emocionales opcionales y tu guion; el grafo genera clones de voz de alta calidad y los exporta como FLAC para uso archivístico o MP3 para compartir rápidamente.
Construido alrededor del modelo IndexTTS-2 y los nodos IndexTTS de ComfyUI, el flujo de trabajo es ideal para creadores, diseñadores de personajes, educadores y usuarios de RunComfy que desean TTS emocional rápido y reproducible. Todo sucede dentro de ComfyUI, por lo que puedes inspeccionar entradas, ajustar configuraciones e iterar rápidamente en ejemplos de narración, diálogo y doblaje.
Modelos clave en el flujo de trabajo Comfyui IndexTTS2 ComfyUI#
- IndexTTS-2 por IndexTeam. Un sistema moderno de texto a voz que realiza clonación de voz condicionada por referencia y control de prosodia expresiva. Se condiciona con un ejemplo corto del hablante y opcionalmente con indicaciones emocionales para renderizar discurso natural a partir de texto. Consulta la tarjeta del modelo en Hugging Face y el artículo acompañante para detalles arquitectónicos y de entrenamiento: IndexTTS-2, proyecto IndexTTS, artículo IndexTTS-2.
Cómo usar el flujo de trabajo Comfyui IndexTTS2 ComfyUI#
A un nivel alto, el grafo toma tres entradas — audio de timbre de referencia, texto y audio emocional opcional — luego ejecuta la generación y exporta el resultado. Los grupos a continuación muestran dónde agregar entradas y cómo se conectan al discurso final.
Cargar audio de referencia de voz#
Este grupo prepara la identidad del hablante. Carga una muestra limpia de la voz objetivo en LoadAudio (#13), idealmente un solo hablante hablando claramente sin música ni efectos. Usa AudioCrop (#37) para aislar un segmento estable para que el sistema aprenda un timbre consistente. Los segmentos cortos con tono estable y entrega neutral típicamente producen la clonación más confiable. La referencia recortada se envía hacia adelante para condicionar el generador.
Cargar texto#
Ingresa tu guion en PrimitiveStringMultiline (#14). La puntuación clara ayuda al modelo a inferir pausas y énfasis, así que escribe el texto de la manera que deseas que se hable. Si planeas lecturas de varias oraciones, mantén cada oración bien formada y evita emojis o símbolos poco comunes. El texto fluye directamente al nodo de síntesis para el renderizado.
Cargar audio de referencia emocional#
Proporciona un clip opcional que capture la emoción o entrega que deseas — por ejemplo, emocionado, calmado o sombrío — a través de LoadAudio (#15). Recórtalo con AudioCrop (#38) para mantener solo la porción expresiva que deseas imitar. Esto es separado de la referencia de timbre y se enfoca en ritmo, energía y tono. Si omites este paso, el flujo de trabajo IndexTTS2 ComfyUI se basará solo en el texto para la prosodia.
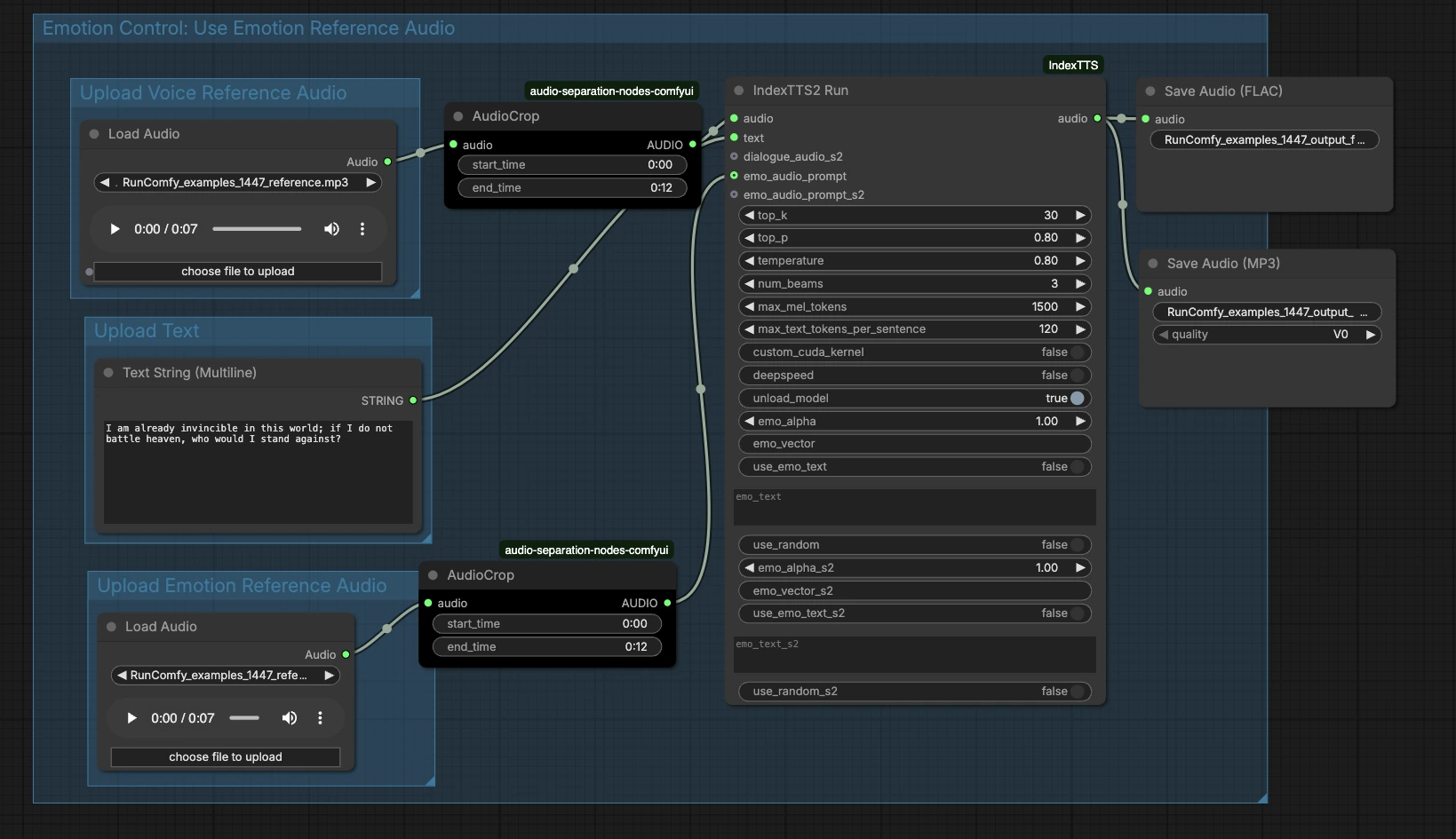
Control emocional: Usar audio de referencia emocional#
Esta área conecta tu indicación emocional al generador. El clip emocional recortado alimenta la entrada emo_audio_prompt en IndexTTS2Run (#12), guiando cadencia e intensidad mientras preserva la voz objetivo. También puedes usar los controles de texto emocional del nodo para dar un toque de estilo si no tienes un ejemplo de audio emocional. En la práctica, el audio emocional tiende a dar una expresividad más fuerte y consistente, mientras que el texto emocional proporciona una dirección más ligera. Combínalos cuando desees tanto un ejemplo concreto como una sugerencia textual.
Generar y exportar#
IndexTTS2Run (#12) sintetiza el discurso usando tu texto, referencia de timbre y cualquier guía emocional. La salida se dirige a SaveAudio (#17) para un FLAC sin pérdida y a SaveAudioMP3 (#39) para una vista previa pequeña y amigable para la web. Usa los campos de nombre de archivo en los nodos de guardado para mantener organizadas las tomas a lo largo de las iteraciones. Este diseño facilita comparar diferentes textos o emociones mientras se mantiene la misma identidad del hablante.
Nodos clave en el flujo de trabajo Comfyui IndexTTS2 ComfyUI#
IndexTTS2Run (#12)#
Este es el generador central que envuelve IndexTTS-2 y expone controles para muestreo, búsqueda de haz, y condicionamiento emocional. Ajusta top_p, top_k y temperature para equilibrar estabilidad y variedad — valores más bajos brindan lecturas más consistentes, valores más altos aumentan la espontaneidad. Usa num_beams cuando deseas que el nodo busque más lecturas candidatas, intercambiando velocidad por calidad. Para guiones largos, max_mel_tokens y max_text_tokens_per_sentence ayudan a prevenir desbordamientos limitando los tamaños de los fragmentos de audio y texto. La emoción puede dirigirse con emo_audio_prompt, emo_alpha para la fuerza de mezcla, o con use_emo_text y emo_text cuando prefieres una pista textual. Los ayudantes de rendimiento como deepspeed, custom_cuda_kernel, y unload_model están disponibles dependiendo de tu hardware. La implementación del nodo es proporcionada por los nodos personalizados de ComfyUI IndexTTS: ComfyUI_IndexTTS, y el modelo subyacente está documentado aquí: IndexTTS-2, proyecto IndexTTS.
AudioCrop (#37) — timbre de referencia#
Usa este nodo para aislar un extracto limpio y estable de tu muestra de hablante. Evita el ruido de fondo, risas o emociones extremas porque esos detalles pueden filtrarse en la voz clonada. Recortar a un tono consistente mejora el bloqueo de identidad y reduce artefactos no deseados.
AudioCrop (#38) — indicación emocional#
Este recorte selecciona la señal expresiva que controla la entrega. Elige una porción con el ritmo o intensidad exactos que deseas, y mantenla concisa para evitar diluir la señal. Para mejor coherencia, usa indicaciones emocionales del mismo hablante que la referencia de timbre cuando sea posible.
Extras opcionales#
- Mantén el audio de referencia seco y monofónico; elimina reverberación, música de fondo y compresión fuerte para una clonación más limpia.
- Puntúa intencionalmente. Comas, puntos y signos de interrogación ayudan al modelo a colocar pausas e inflexiones que coinciden con tu intención.
- Para tomas reproducibles, desactiva la aleatoriedad en el nodo o mantén notas sobre selecciones de texto y audio para que puedas regenerar la misma salida más tarde.
- Si la VRAM es ajustada, habilita la descarga del modelo entre ejecuciones; puede agregar un pequeño costo de tiempo pero libera memoria para otros grafos.
- Respeta los derechos de voz. Solo usa grabaciones de referencia que estés autorizado a clonar y divulga el discurso sintético donde sea necesario.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos a RunningHub por la referencia del flujo de trabajo, RunComfy por el flujo de trabajo de guardado en la nube, Index Team por IndexTTS e IndexTTS-2, los autores del artículo IndexTTS2, y a billwuhao por los nodos personalizados de ComfyUI IndexTTS por sus contribuciones y mantenimiento. Para detalles autorizados, por favor consulta la documentación original y los repositorios enlazados a continuación.
Recursos#
- RunningHub/Referencia de flujo de trabajo
- Documentos / Notas de lanzamiento: Publicación de RunningHub
- RunComfy/Flujo de trabajo de guardado en la nube
- Documentos / Notas de lanzamiento: Flujo de trabajo de RunComfy
- index-tts/index-tts
- GitHub: index-tts/index-tts
- IndexTeam/IndexTTS-2
- Hugging Face: IndexTeam/IndexTTS-2
- IndexTTS2/Artículo
- arXiv: 2506.21619
- billwuhao/ComfyUI_IndexTTS
- GitHub: billwuhao/ComfyUI_IndexTTS
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las licencias y términos respectivos proporcionados por sus autores y mantenedores.
