
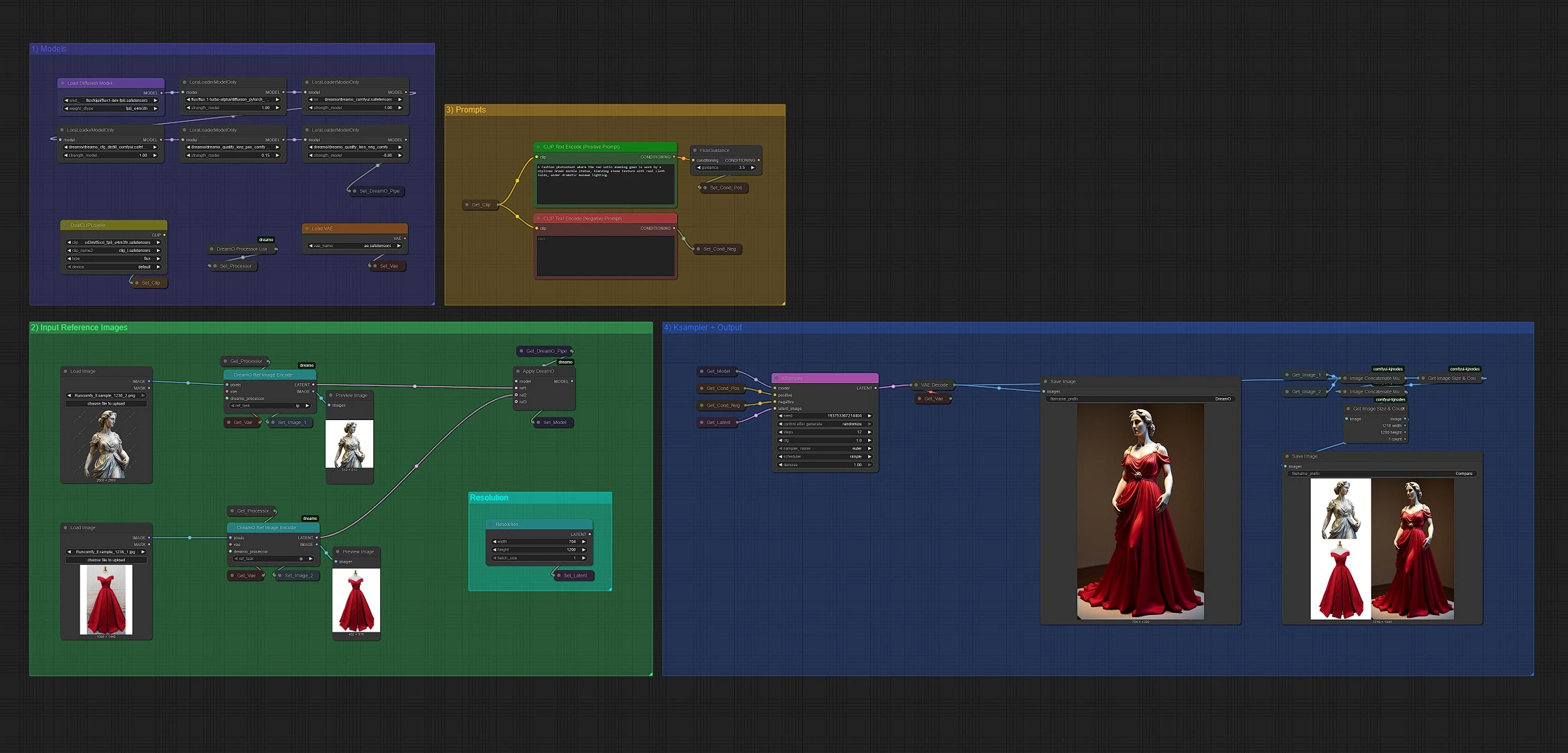









DreamO: Unified Multi-Task Image Customization Framework#
DreamO is a powerful reference-driven image generation workflow that supports a variety of visual customization tasks, including identity preservation, style transfer, virtual try-on, and multi-condition blending.
Built upon a unified architecture, DreamO enables flexible image synthesis from one to three input references, guided by natural language prompts. Whether you're working with characters, garments, objects, or facial identities, DreamO delivers high-fidelity outputs while preserving structure and stylistic consistency across tasks.
Why Use DreamO?#
The DreamO framework offers:
- Multi-Task Support: DreamO supports IP, ID, Try-On, Style, or Multi-Condition modes
- 1–3 Reference Images: DreamO uses one, two, or three input images to guide generation
- Task-Specific Control: DreamO applies targeted customization like facial identity, clothes, or appearance style
- Text + Image Fusion: DreamO combines visual references with prompt-driven creativity
- Perfect for Creators: DreamO is ideal for character design, virtual try-on demos, product prototyping, and more
DreamO empowers artists, developers, and designers with a comprehensive toolkit for controlled image synthesis—flexible, modular, and creatively scalable.
DreamO Models#
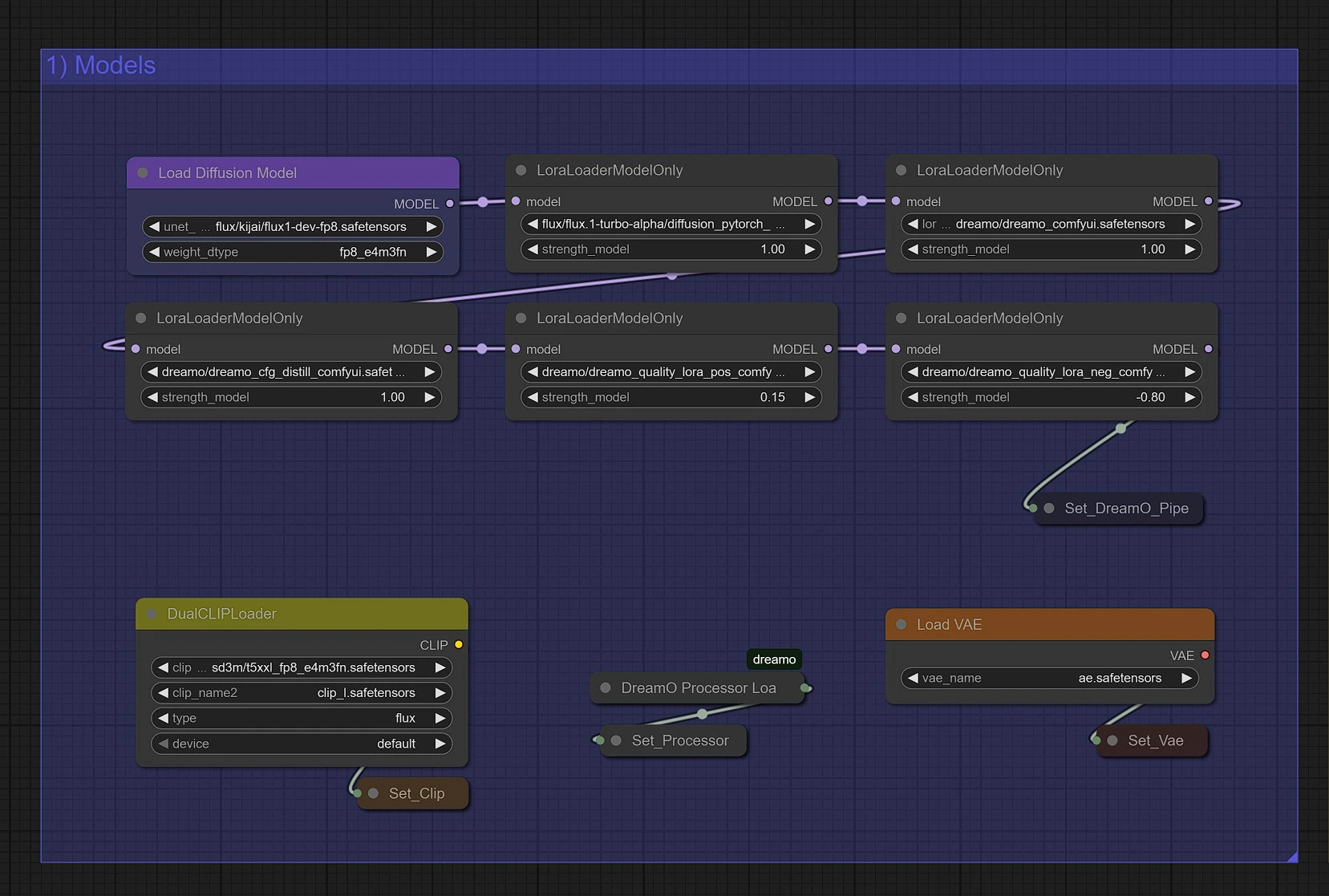
This group loads all the required DreamO models automatically when you first run the DreamO workflow. No manual setup is required. The DreamO models are hosted on the official repository: https://github.com/ToTheBeginning/ComfyUI-DreamO
DreamO Input Images#
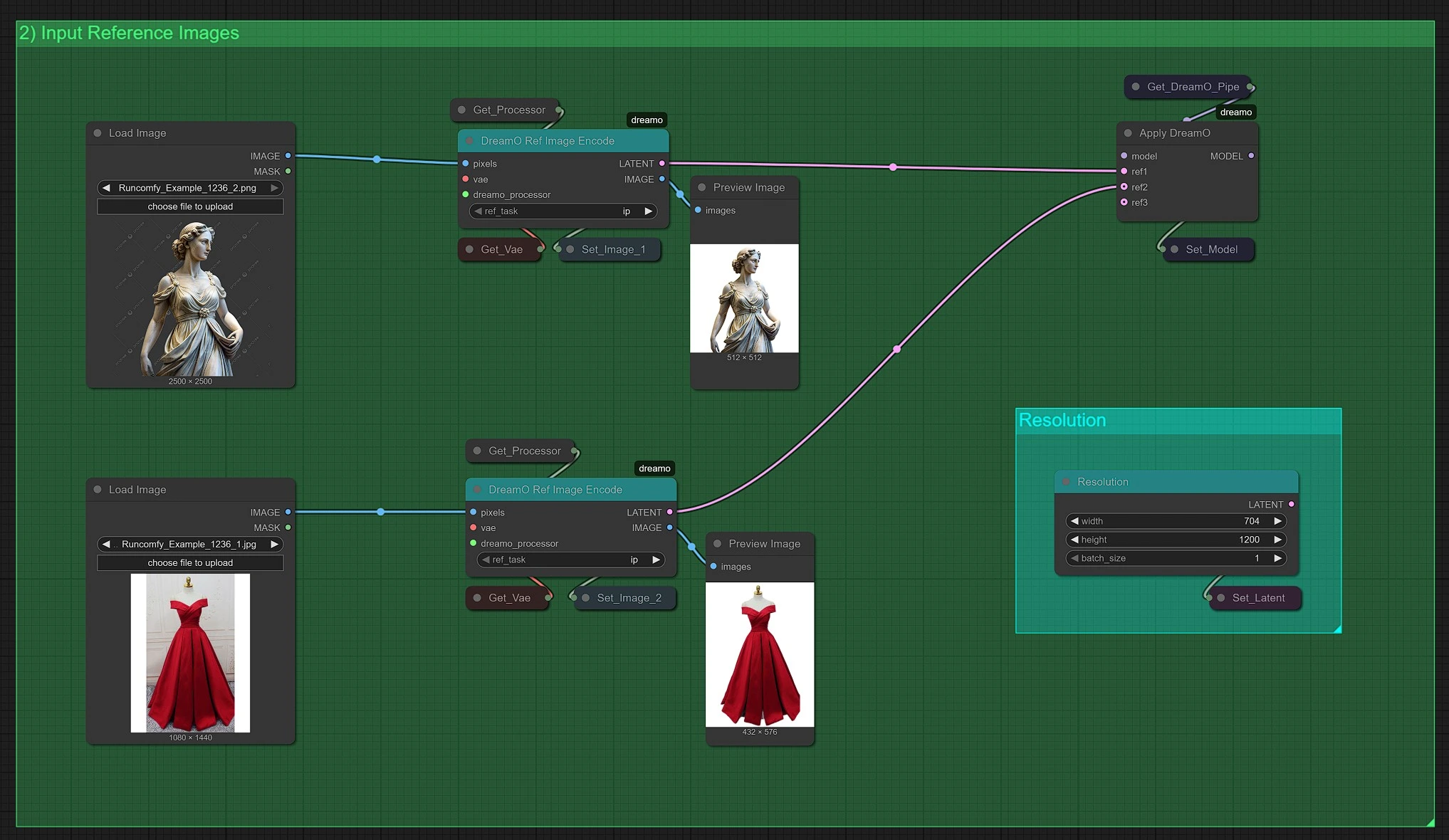
In this section, you upload 1 to 3 reference images and select the task you want DreamO to perform:
- IP (Identity + Pose)
- ID (Facial Identity only)
- Style
You can also set the render resolution to define the DreamO output image size. Adjust this based on your desired quality or use-case. Proper image resolution improves alignment and preserves fine details in DreamO output.
DreamO Prompts#
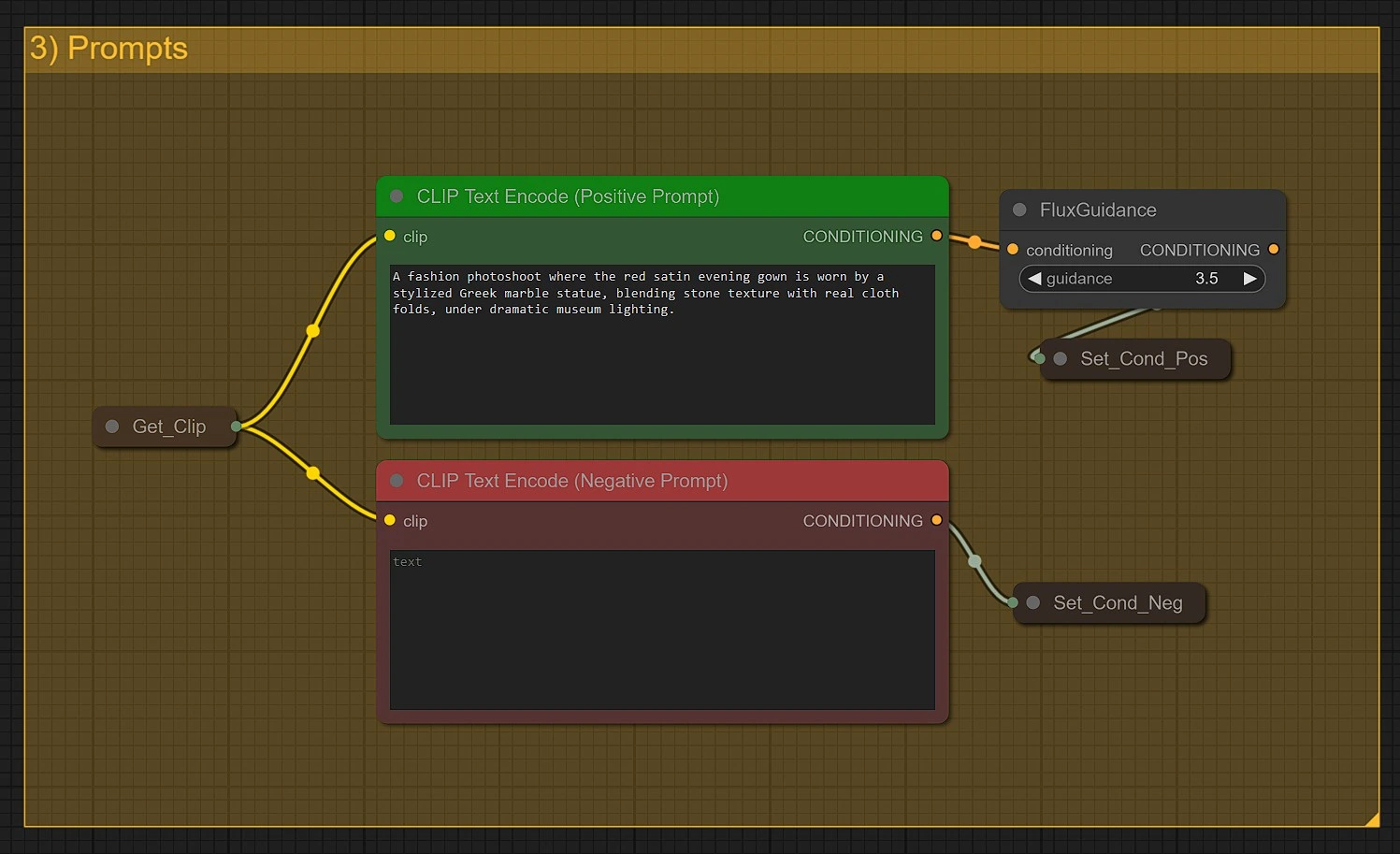
Enter your main text prompt here to control the appearance, context, or style of the DreamO output image:
- Write detailed, expressive prompts to guide the DreamO generation direction
- You can combine visual references and language to shape clothing, accessories, emotion, or setting in DreamO
- Use negative prompts to avoid unwanted features or artifacts in DreamO outputs
Prompt guidance is essential to achieving fine-grained results in all DreamO tasks.
DreamO KSampler + Output#
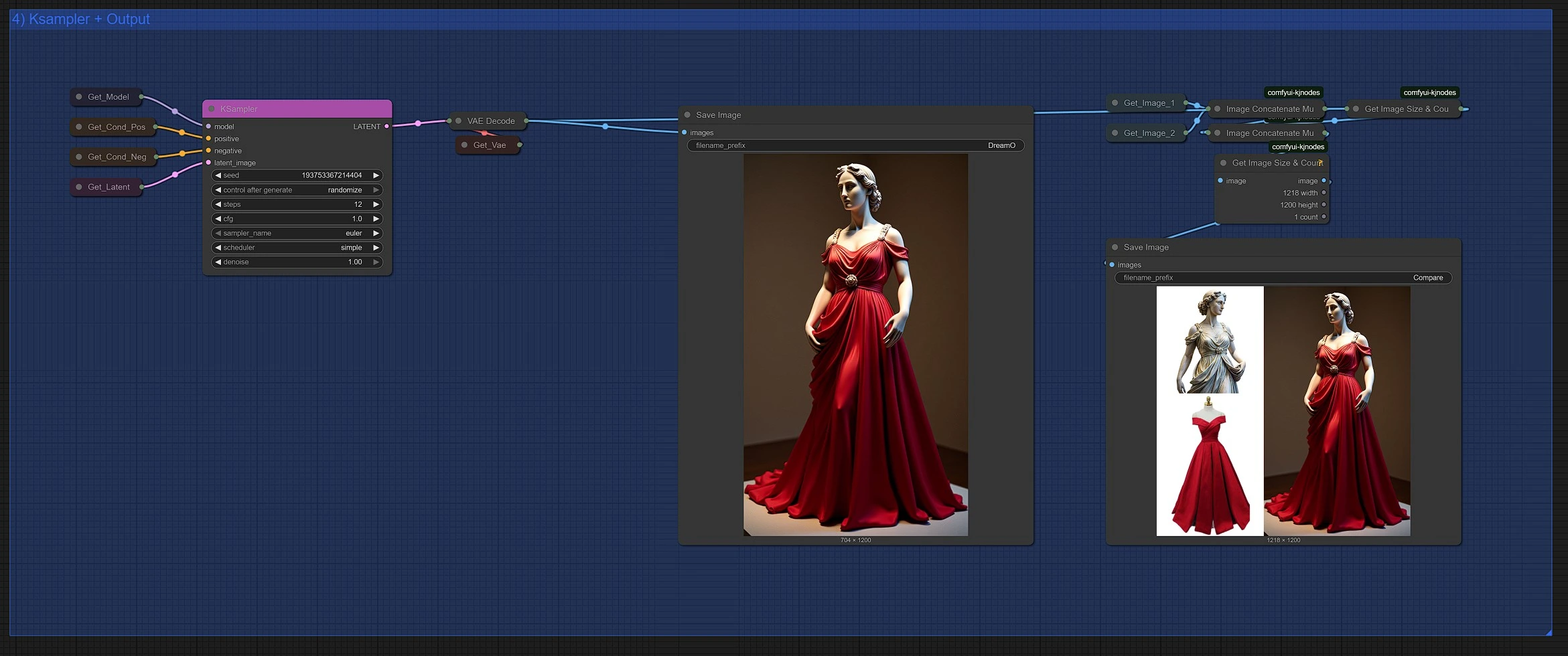
In this DreamO section, you can:
- Configure sampling parameters like steps, sampler type (Euler, DPM++), and guidance scale for DreamO
- Trigger the DreamO generation process
- View and compare the DreamO output results
All DreamO generated images are automatically saved in your ComfyUI > output folder.
DreamO renders a side-by-side comparison showing how the reference and prompts influence the final result—helping you iterate quickly and creatively with DreamO.
Acknowledgement#
This workflow uses the DreamO model developed by ToTheBeginning. All credits go to them for building this unified, multi-task image customization architecture and enabling seamless multi-input workflows in ComfyUI with DreamO. DreamO GitHub Repository: https://github.com/ToTheBeginning/ComfyUI-DreamO
DreamO brings together years of research into identity, structure, and style preservation across tasks like IP-Adapter, InstantID, InstantStyle, and Try-On generation. DreamO is a versatile and production-ready toolkit for creators looking to combine reference-driven control with deep model fidelity—all inside ComfyUI with DreamO.


