
Character AI Ovi: image to video with synchronized speech in ComfyUI#
Character AI Ovi is an audiovisual generation workflow that turns a single image into a talking, moving character with coordinated sound. Built on the Wan model family and integrated through the WanVideoWrapper, it generates video and audio in one pass, delivering expressive animation, intelligible lip sync, and context-aware ambience. If you make short stories, virtual hosts, or cinematic social clips, Character AI Ovi lets you go from still art to a complete performance in minutes.
This ComfyUI workflow accepts one image plus a text prompt containing lightweight markup for speech and sound design. It composes frames and waveform together so the mouth, cadence, and scene audio feel naturally aligned. Character AI Ovi is designed for creators who want polished results without stitching separate TTS and video tools.
Key models in Comfyui Character AI Ovi workflow#
- Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation. The core model that jointly produces video and audio from text or text+image prompts. character-ai/Ovi
- Wan 2.2 video backbone and VAE. The workflow uses Wan’s high-compression video VAE for efficient 720p, 24 fps generation while preserving detail and temporal coherence. Wan-AI/Wan2.2-TI2V-5B-Diffusers • Wan-Video/Wan2.2
- Google UMT5-XXL text encoder. Encodes the prompt, including speech tags, into rich multilingual embeddings that drive both branches. google/umt5-xxl
- MMAudio VAE with BigVGAN vocoder. Decodes the model’s audio latents to high-quality speech and effects with natural timbre. hkchengrex/MMAudio • nvidia/bigvgan_v2_44khz_128band_512x
- ComfyUI-ready Ovi weights by Kijai. Curated checkpoints for the video branch, audio branch, and VAE in bf16 and fp8 scaled variants. Kijai/WanVideo_comfy/Ovi • Kijai/WanVideo_comfy_fp8_scaled/TI2V/Ovi
- WanVideoWrapper nodes for ComfyUI. Wrapper that exposes Wan and Ovi features as composable nodes. kijai/ComfyUI-WanVideoWrapper
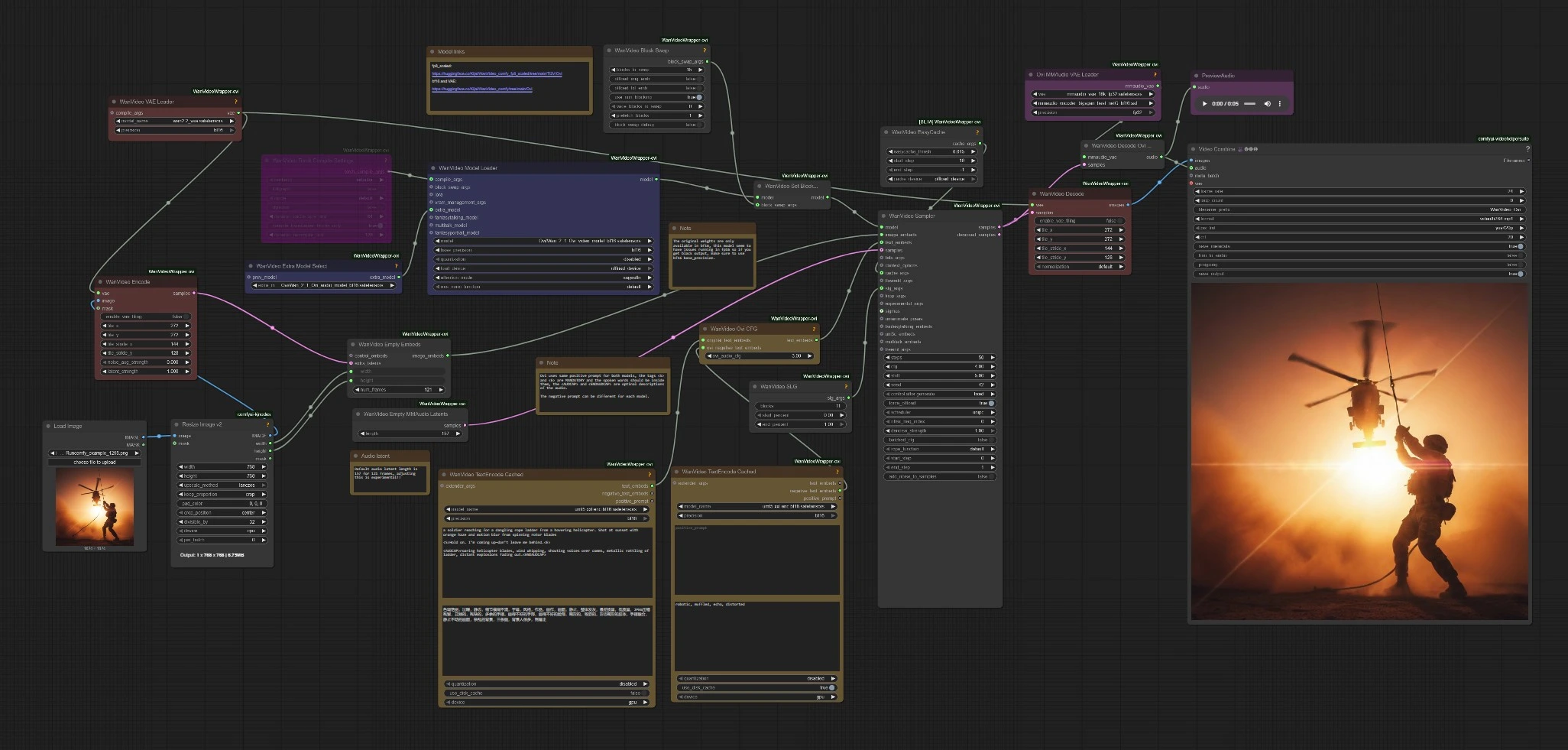
How to use Comfyui Character AI Ovi workflow#
This workflow follows a simple path: encode your prompt and image, load the Ovi checkpoints, sample joint audio+video latents, then decode and mux to MP4. The subsections below map to the visible node clusters so you know where to interact and what changes affect outcomes.
Prompt authoring for speech and sound#
Write one positive prompt for the scene and the spoken line. Use the Ovi tags exactly as shown: wrap words to be spoken with <S> and <E>, and optionally describe non-speech audio with <AUDCAP> and <ENDAUDCAP>. The same positive prompt conditions both the video and audio branches so lip motion and timing align. You can use different negative prompts for video and audio to suppress artifacts independently. Character AI Ovi responds well to concise stage directions plus a single, clear line of dialogue.
Image ingest and conditioning#
Load a single portrait or character image, then the workflow resizes and encodes it to latents. This establishes identity, pose, and initial framing for the sampler. Width and height from the resize stage set the video aspect; choose square for avatars or vertical for shorts. The encoded latents and image-derived embeds guide the sampler so motion feels anchored to the original face.
Model loading and performance helpers#
Character AI Ovi loads three essentials: the Ovi video model, the Wan 2.2 VAE for frames, and the MMAudio VAE plus BigVGAN for audio. Torch compile and a lightweight cache are included to speed warm starts. A block-swap helper is wired in to lower VRAM usage by offloading transformer blocks when needed. If you are VRAM constrained, increase block offload in the block-swap node and keep cache enabled for repeat runs.
Joint sampling with guidance#
The sampler runs Ovi’s twin backbones together so the soundtrack and frames co-evolve. A skip-layer guidance helper improves stability and detail without sacrificing motion. The workflow also routes your original text embeddings through an Ovi-specific CFG mixer so you can tilt the balance between strict prompt adherence and freer animation. Character AI Ovi tends to produce the best lip motion when the spoken line is short, literal, and enclosed only by the <S> and <E> tags.
Decode, preview, and export#
After sampling, video latents decode through the Wan VAE while audio latents decode through MMAudio with BigVGAN. A video combiner muxes frames and audio into an MP4 at 24 fps, ready for sharing. You can also preview audio directly to verify speech intelligibility before saving. Character AI Ovi’s default path targets 5 seconds; extend cautiously to keep lips and cadence in sync.
Key nodes in Comfyui Character AI Ovi workflow#
WanVideoTextEncodeCached(#85)
Encodes the main positive prompt and video negative prompt into embeddings used by both branches. Keep dialogue inside <S>…<E> and place sound design inside <AUDCAP>…<ENDAUDCAP>. For best alignment, avoid multiple sentences in one speech tag and keep the line concise.
WanVideoTextEncodeCached(#96)
Provides a dedicated negative text embedding for audio. Use it to suppress artifacts like robotic tone or heavy reverberation without affecting visuals. Start with short descriptors and expand only if you still hear the issue.
WanVideoOviCFG(#94)
Blends the original text embeddings with the audio-specific negatives through an Ovi-aware classifier-free guidance. Raise it when speech content drifts from the written line or lip motions feel off. Lower it slightly if motion becomes stiff or over-constrained.
WanVideoSampler(#80)
The heart of Character AI Ovi. It consumes image embeds, joint text embeds, and optional guidance to sample a single latent that contains both video and audio. More steps increase fidelity but also runtime. If you see memory pressure or stalls, pair higher block-swap with cache on, and consider disabling torch compile for quick troubleshooting.
WanVideoEmptyMMAudioLatents(#125)
Initializes the audio latent timeline. The default length is tuned for a 121-frame, 24 fps clip. Adjusting this to change duration is experimental; change it only if you understand how it must track frame count.
VHS_VideoCombine(#88)
Muxes decoded frames and audio to MP4. Set frame rate to match your sampling target and toggle trim-to-audio if you want the final cut to follow the generated waveform. Use the CRF control to balance file size and quality.
Optional extras#
- Use bf16 for Ovi video and Wan 2.2 VAE. If you encounter black frames, switch base precision to
bf16for the model loaders and text encoder. - Keep speeches short. Character AI Ovi lip-syncs most reliably with short, single-sentence dialogue inside
<S>and<E>. - Separate negatives. Put visual artifacts in the video negative prompt and tonal artifacts in the audio negative prompt to avoid unintended tradeoffs.
- Preview first. Use the audio preview to confirm clarity and pacing before exporting the final MP4.
- Get the exact weights used. The workflow expects Ovi video and audio checkpoints plus the Wan 2.2 VAE from Kijai’s model mirrors. WanVideo_comfy/Ovi • WanVideo_comfy_fp8_scaled/TI2V/Ovi
With these pieces in place, Character AI Ovi becomes a compact, creator-friendly pipeline for expressive talking avatars and narrative scenes that sound as good as they look.
Acknowledgements#
This workflow implements and builds upon the following works and resources. We gratefully acknowledge kijai and Character AI for Ovi for their contributions and maintenance. For authoritative details, please refer to the original documentation and repositories linked below.
Resources#
- Character AI Ovi Source
- Workflow: wanvideo_2_2_5B_ovi_testing @kijai
- Github: character-ai/Ovi
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.