
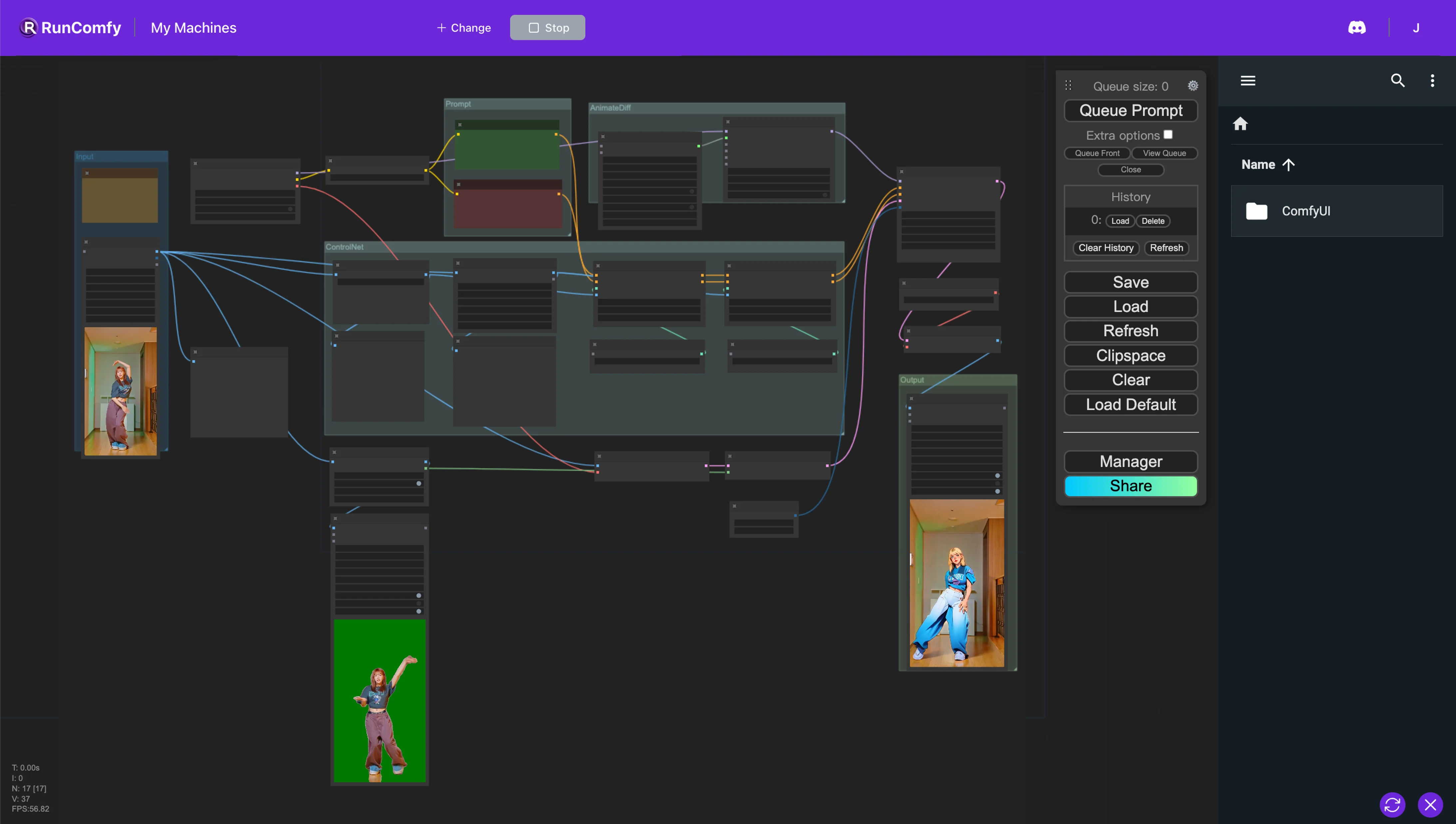
1. ComfyUI AnimateDiff, ControlNet and Auto Mask Workflow#
This ComfyUI workflow introduces a powerful approach to video restyling, specifically aimed at transforming characters into an anime style while preserving the original backgrounds. This transformation is supported by several key components, including AnimateDiff, ControlNet, and Auto Mask.
AnimateDiff is designed for differential animation techniques, enabling the maintenance of a consistent context within animations. This component focuses on smoothing transitions and enhancing the fluidity of motion in restyled video content.
ControlNet serves a critical role in precise human pose replication and manipulation. It leverages advanced pose estimation to accurately capture and control the nuances of human movement, facilitating the transformation of characters into anime forms while preserving their original poses.
Auto Mask is involved in automatic segmentation, adept at isolating characters from their backgrounds. This technology allows for selective restyling of video elements, ensuring that character transformations are executed without altering the surrounding environment, maintaining the integrity of the original backgrounds.
This ComfyUI workflow realizes the conversion of standard video content into stylized animations, focusing on efficiency and the quality of the anime-style character generation.
2. Overview of AnimateDiff#
2.1. Introduction to AnimateDiff#
AnimateDiff emerges as an AI tool designed to animate static images and text prompts into dynamic videos, leveraging Stable Diffusion models and a specialized motion module. This technology automates the animation process by predicting seamless transitions between frames, making it accessible to users without coding skills or computing resources through a free online platform.
2.2. Key Features of AnimateDiff#
2.2.1. Comprehensive Model Support: AnimateDiff is compatible with various versions, including AnimateDiff v1, v2, v3 for Stable Diffusion V1.5, and AnimateDiff sdxl for Stable Diffusion SDXL. It allows for the use of multiple motion models simultaneously, facilitating the creation of complex and layered animations.
2.2.2. Context Batch Size Determines Animation Length: AnimateDiff enables the creation of animations of infinite length through the adjustment of the context batch size. This feature allows users to customize the length and transition of animations to suit their specific requirements, providing a highly adaptable animation process.
2.2.3. Context Length for Smooth Transitions: The purpose of Uniform Context Length in AnimateDiff is to ensure seamless transitions between different segments of an animation. By adjusting the Uniform Context Length, users can control the transition dynamics between scenes—longer lengths for smoother, more seamless transitions, and shorter lengths for quicker, more pronounced changes.
2.2.4. Motion Dynamics: In AnimateDiff v2, specialized motion LoRAs are available for adding cinematic camera movements to animations. This feature introduces a dynamic layer to animations, significantly enhancing their visual appeal.
2.2.5. Advanced Support Features: AnimateDiff is designed to work with a variety of tools including ControlNet, SparseCtrl, and IPAdapter, offering significant advantages for users aiming to expand the creative possibilities of their projects.
3. Overview of ControlNet#
3.1. Introduction to ControlNet#
ControlNet introduces a framework for augmenting image diffusion models with conditional inputs, aiming to refine and guide the image synthesis process. It achieves this by duplicating the neural network blocks within a given diffusion model into two sets: one remains "locked" to preserve the original functionality, and the other becomes "trainable," adapting to the specific conditions provided. This dual structure allows developers to incorporate a variety of conditional inputs by using models such as OpenPose, Tile, IP-Adapter, Canny, Depth, LineArt, MLSD, Normal Map, Scribbles, Segmentation, Shuffle, and T2I Adapter, thereby directly influencing the generated output. Through this mechanism, ControlNet offers developers a powerful tool to control and manipulate the image generation process, enhancing the diffusion model's flexibility and its applicability to diverse creative tasks.
Preprocessors and Model Integration
3.1.1. Preprocessing Configuration: Initiating with ControlNet involves selecting a suitable preprocessor. Activating the preview option is advisable for a visual understanding of the preprocessing impact. Post-preprocessing, the workflow transitions to utilizing the preprocessed image for further processing steps.
3.1.2. Model Matching: Simplifying the model selection process, ControlNet ensures compatibility by aligning models with their corresponding preprocessors based on shared keywords, facilitating a seamless integration process.
3.2. Key Features of ControlNet#
In-depth Exploration of ControlNet Models
3.2.1. OpenPose Suite: Designed for precise human pose detection, the OpenPose suite encompasses models for detecting body poses, facial expressions, and hand movements with exceptional accuracy. Various OpenPose preprocessors are tailored to specific detection requirements, from basic pose analysis to detailed capture of facial and hand nuances.
3.2.2. Tile Resample Model: Enhancing image resolution and detail, the Tile Resample model is optimally used alongside an upscaling tool, aiming to enrich image quality without compromising visual integrity.
3.2.3. IP-Adapter Model: Facilitating the innovative use of images as prompts, the IP-Adapter integrates visual elements from reference images into the generated outputs, merging text-to-image diffusion capabilities for enriched visual content.
3.2.4. Canny Edge Detector: Revered for its edge detection capabilities, the Canny model emphasizes the structural essence of images, enabling creative visual reinterpretations while maintaining core compositions.
3.2.5. Depth Perception Models: Through a variety of depth preprocessors, ControlNet is adept at deriving and applying depth cues from images, offering a layered depth perspective in generated visuals.
3.2.6. LineArt Models: Convert images into artistic line drawings with LineArt preprocessors, catering to diverse artistic preferences from anime to realistic sketches, ControlNet accommodates a spectrum of stylistic desires.
3.2.7. Scribbles Processing: With preprocessors like Scribble HED, Pidinet, and xDoG, ControlNet transforms images into unique scribble art, offering varied styles for edge detection and artistic reinterpretation.
3.2.8. Segmentation Techniques: ControlNet's segmentation capabilities accurately classify image elements, enabling precise manipulation based on object categorization, ideal for complex scene constructions.
3.2.9. Shuffle Model: Introducing a method for color scheme innovation, the Shuffle model randomizes input images to generate new color patterns, creatively altering the original while retaining its essence.
3.2.10. T2I Adapter Innovations: The T2I Adapter models, including Color Grid and CLIP Vision Style, propel ControlNet into new creative domains, blending and adapting colors and styles to produce visually compelling outputs that respect the original's color scheme or stylistic attributes.
3.2.11. MLSD (Mobile Line Segment Detection): Specializing in the detection of straight lines, MLSD is invaluable for projects focused on architectural and interior designs, prioritizing structural clarity and precision.
3.2.12. Normal Map Processing: Utilizing surface orientation data, Normal Map preprocessors replicate the 3D structure of reference images, enhancing the generated content's realism through detailed surface analysis.
