
LTX 2.3 Sulphur 2 текст в видеопроцесс для кинематографической анимации персонажей#
Этот процесс ComfyUI преобразует подсказки на естественном языке в короткие, кинематографические видео, сосредоточенные на персонажах, с опциональным аудио, построенные вокруг компонентов Lightricks LTX‑2.3 и Sulphur 2. Он выполняет генерацию в низком разрешении для планирования движения, увеличивает латентную последовательность, затем уточняет в высоком разрешении перед декодированием в кадры и мультиплексированием синхронизированного аудиотрека.
Процесс LTX 2.3 Sulphur 2 текст в видео идеально подходит для быстрого тестирования анимации персонажей, концепций движения в стиле D‑Human и отточенных экспериментов текст‑в‑видео. Он не зависит от входных данных изображение‑в‑видео или ретрансляции подсказок; все начинается с текста, с кондиционированием LTXV, направляющим как видео, так и аудио латенты от начала до конца.
Ключевые модели в Comfyui LTX 2.3 Sulphur 2 текст в видеопроцесс#
- Lightricks LTX‑2.3. Основной генератор текст‑в‑видео, используемый для пространственно-временного синтеза и мультимодальных AV латентов. См. официальный репозиторий модели для весов и заметок о возможностях и ограничениях. Hugging Face: Lightricks/LTX-2.3
- Lightricks LTX‑2.3 FP8 контрольная точка. Память-эффективный вариант LTX‑2.3, который ускоряет вывод и позволяет создавать более длинные клипы или более высокие разрешения на ограниченных GPU. Hugging Face: Lightricks/LTX-2.3-fp8
- Базовая модель Sulphur 2. Обеспечивает стилевые приоритеты и детализацию персонажей через LoRA в этом процессе, помогая достичь четких лиц и кинематографического тона. Hugging Face: SulphurAI/Sulphur-2-base
- LTX‑2.3 Spatial Upscaler x2 1.1. Увеличитель пространственных деталей в латентном пространстве перед проходом высокоразрешенного уточнения. Hugging Face: Lightricks/LTX-2.3 file ltx-2.3-spatial-upscaler-x2-1.1.safetensors
- Кодировщик текста LTX (Gemma 3 12B IT упакован для LTX). Обеспечивает пространство встраивания текста, соответствующее кондиционированию LTX‑2.3 для точного следования подсказке. Hugging Face: Comfy-Org/ltx-2
- LTX Audio VAE. Декодирует аудио латент, сгенерированный вместе с видео, чтобы финальный рендер мог включать синхронизированный саундтрек. Hugging Face: Lightricks/LTX-2.3
Как использовать Comfyui LTX 2.3 Sulphur 2 текст в видеопроцесс#
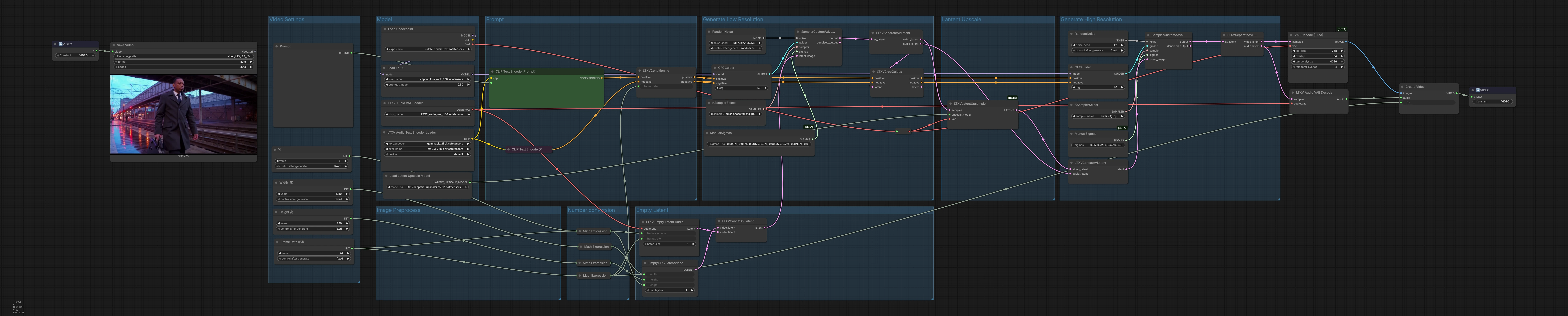
Общая логика Процесс работает в три акта: генерация в низком разрешении для установления движения и композиции, латентное увеличение для увеличения пространственных деталей и проход высокоразрешенного уточнения, который также дает финальное аудио. Латенты декодируются в кадры и звуковую волну, затем мультиплексируются в контейнер MP4, готовый к доставке.
Настройки видео Используйте группу "Настройки видео" для определения ширины, высоты, частоты кадров и продолжительности. Количество кадров вычисляется автоматически из вашей продолжительности и fps, чтобы время и ритм оставались согласованными. Эти значения управляют распределением латентов и декодированием, поэтому сначала установите их, чтобы соответствовать вашей целевой пропорции и времени выполнения. Регулировка fps здесь также информирует кондиционирование, чтобы плавность движения и согласование аудио использовали одни и те же часы.
Подсказка В "Подсказке" загрузите кодировщик текста LTX с помощью LTXAVTextEncoderLoader (#316), затем напишите ваше положительное описание в CLIPTextEncode (#303) и любые нежелательные черты в CLIPTextEncode (#312). Узел LTXVConditioning (#304) объединяет положительное и отрицательное кондиционирование и добавляет выбранную частоту кадров, чтобы временное руководство соответствовало вашему fps. Относитесь к положительной подсказке как к краткому описанию кадра: субъект, камера, освещение, настроение и стилистические подсказки. Держите отрицательный список сосредоточенным на артефактах, которые вы регулярно видите и хотите удалить.
Модель Группа "Модель" загружает основную контрольную точку через CheckpointLoaderSimple (#315) и применяет Sulphur 2 LoRA с помощью LoraLoaderModelOnly (#285) для внедрения кинематографической текстуры и верности персонажей. Здесь вы можете менять контрольные точки или LoRA для изменения общего вида и приоритетов движения. Выход модели направляется как к начальным, так и к уточняющим направляющим, чтобы стиль и идентичность были согласованными во всех проходах. Сочетание LTX‑2.3 с Sulphur 2 дает яркий контраст и детализированные лица, которые хорошо читаются в движении.
Преобразование чисел Утилиты выражения конвертируют ваш fps и секунды в целое количество кадров, используемое в дальнейшем. Это поддерживает синхронизацию аудио и видео без ручных расчетов. Если вы измените fps или продолжительность позже, график автоматически обновляет зависимые узлы.
Пустой Латент "Пустой Латент" создает согласованные контейнеры для генерации: EmptyLTXVLatentVideo (#295) определяет пространственный размер и длину латентного видео, LTXVEmptyLatentAudio (#305) выделяет аудио латент с той же частотой кадров, и LTXVConcatAVLatent (#321) объединяет их в единый AV латент. Начало с пустых латентов гарантирует, что диффузионный проход полностью отражает вашу подсказку и кондиционирование, а не любой существующий контент.
Генерация в низком разрешении Первый этап выборки устанавливает движение и композицию с меньшими затратами. CFGGuider (#313), KSamplerSelect (#291) и ManualSigmas (#306) управляют тем, насколько сильно подсказка направляет генерацию и общий график шума. SamplerCustomAdvanced (#283) затем удаляет шум из AV латента, создавая связный клип. Результат разделяется LTXVSeparateAVLatent (#307), и LTXVCropGuides (#284) уточняет пространственное внимание, чтобы сохранить желаемое кадрирование субъекта во время последующего увеличения.
Латентное увеличение LTXVLatentUpsampler (#287) использует увеличитель LTX‑2.3 x2 для повышения пространственных деталей, оставаясь в латентном пространстве для скорости и стабильности. Подавать увеличенное латентное видео вперед улучшает текстуру и читаемость перед высокоразрешенным уточнением. Это сохраняет движение, которое вам понравилось с первого прохода, открывая пространство для более четких краев и богатых материалов.
Генерация в высоком разрешении Увеличенное латентное видео снова соединяется с аудио латентом в LTXVConcatAVLatent (#278) и снова направляется для финального качества. CFGGuider (#282), KSamplerSelect (#280) и ManualSigmas (#281) дают последнее слово о силе подсказки, деталях и временной согласованности, с SamplerCustomAdvanced (#308) создающим уточненный AV латент. LTXVSeparateAVLatent (#309) передает видео VAEDecodeTiled (#314) для декодирования кадров, удобного для памяти, и аудио LTXVAudioVAEDecode (#297) для реконструкции звуковой волны. CreateVideo (#310) мультиплексирует кадры и аудио на вашу целевую частоту кадров, а SaveVideo (#75) записывает файл MP4/H.264.
Предварительная обработка изображений Эта область направляет базовые модели VAE и увеличители, чтобы мозаика и латентное увеличение работали в рамках вашего бюджета VRAM. Если вы испытываете давление на память, отдайте предпочтение весам FP8 LTX‑2.3 и держите включенным мозаичное декодирование для поддержания пропускной способности и качества.
Ключевые узлы в Comfyui LTX 2.3 Sulphur 2 текст в видеопроцесс#
LTXVConditioning (#304) Объединяет положительное и отрицательное текстовое кондиционирование и прикрепляет рабочую частоту кадров, чтобы временное руководство соответствовало вашему рендеру. Сильный, конкретный язык сцены улучшает структуру кадра; лаконичные негативы уменьшают артефакты. См. карточку модели LTX‑2.3 для заметок о кондиционировании. Hugging Face: Lightricks/LTX-2.3
LTXVCropGuides (#284) Мягко управляет композицией, чтобы сохранить основного субъекта в кадре, как задумано. Используйте его, чтобы защитить размер лица, размещение горизонта или центрированного субъекта перед увеличением и уточнением. Это особенно полезно для кадров в стиле диалога и средних крупных планов.
CFGGuider (#313, #282) Контролирует, насколько агрессивно подсказка влияет на траекторию диффузии в обоих проходах. Используйте первый направляющий, чтобы зафиксировать движение и постановку, затем второй, чтобы добавить четкости, не отклоняясь от установленного кадра.
ManualSigmas (#306, #281) Определяет график шума. Предварительное добавление большего количества шума поощряет более широкое исследование движения; более мягкий график подчеркивает временную согласованность. Держите графики низкого и высокого разрешения дополнительно, а не идентичными.
LTXVLatentUpsampler (#287) Выполняет x2 латентное увеличение с использованием официального увеличителя LTX, чтобы получить детали перед уточняющим выборщиком. Замена на другой вариант увеличителя LTX‑2.3 может немного изменить резкость и зернистость. Hugging Face: Lightricks/LTX-2.3
VAEDecodeTiled (#314) Декодирует длинные или большие клипы в управляемых тайлах, чтобы избежать пиков VRAM. Если вы изменяете пространственный размер или длину клипа, отрегулируйте мозаичность для балансировки памяти и скорости декодирования.
LoraLoaderModelOnly (#285) Применяет Sulphur 2 LoRA к базовому пути модели, чтобы верность персонажей и стилистические подсказки передавались в оба этапа выборки. Используйте это, чтобы быстро менять образы, сохраняя ту же основу LTX‑2.3. Hugging Face: SulphurAI/Sulphur-2-base
Дополнительные возможности#
- Управление семенами: установите фиксированные значения в обоих узлах
RandomNoise, чтобы дублировать результаты; измените одно семя, чтобы исследовать альтернативы. - Подсказки: пишите подсказки как указания для кадра (субъект, камера, освещение, настроение). Держите отрицательный список сосредоточенным и коротким.
- Производительность: если VRAM ограничена, отдайте предпочтение весам FP8 LTX‑2.3 и держите включенным мозаичное декодирование.
- Вывод: график записывает MP4/H.264; измените контейнер или кодек в
SaveVideo, если вам нужны прокси-рабочие процессы ProRes.
Этот процесс LTX 2.3 Sulphur 2 текст в видео предлагает чистый, конечный путь от подсказки до отточенного видео с синхронизированным аудио, построенный для быстрой итерации на кинематографической анимации персонажей.
Благодарности#
Этот процесс реализует и основывается на следующих работах и ресурсах. Мы благодарны RunningHub за базовый процесс Sulphur2 для видеопроизводства, SulphurAI за базовую модель Sulphur-2, Lightricks за модели LTX-2.3 и LTX-2.3-fp8 и Comfy-Org за текстовый кодировщик LTX-2 за их вклад и поддержку. Для получения авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, указанным ниже.
Ресурсы#
- RunningHub/Sulphur2 Basic Workflow for Video Production
- Документы / Заметки о выпуске: Sulphur2 Basic Workflow for Video Production
- SulphurAI/Sulphur-2-base
- Hugging Face: SulphurAI/Sulphur-2-base
- Lightricks/LTX-2.3
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3
- arXiv: LTX-2: Efficient Joint Audio-Visual Foundation Model (2601.03233)
- Lightricks/LTX-2.3-fp8
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3-fp8
- arXiv: LTX-2: Efficient Joint Audio-Visual Foundation Model (2601.03233)
- Comfy-Org/ltx-2
- Hugging Face: Comfy-Org/ltx-2
Примечание: использование указанных моделей, наборов данных и кода подлежит соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими лицами.