
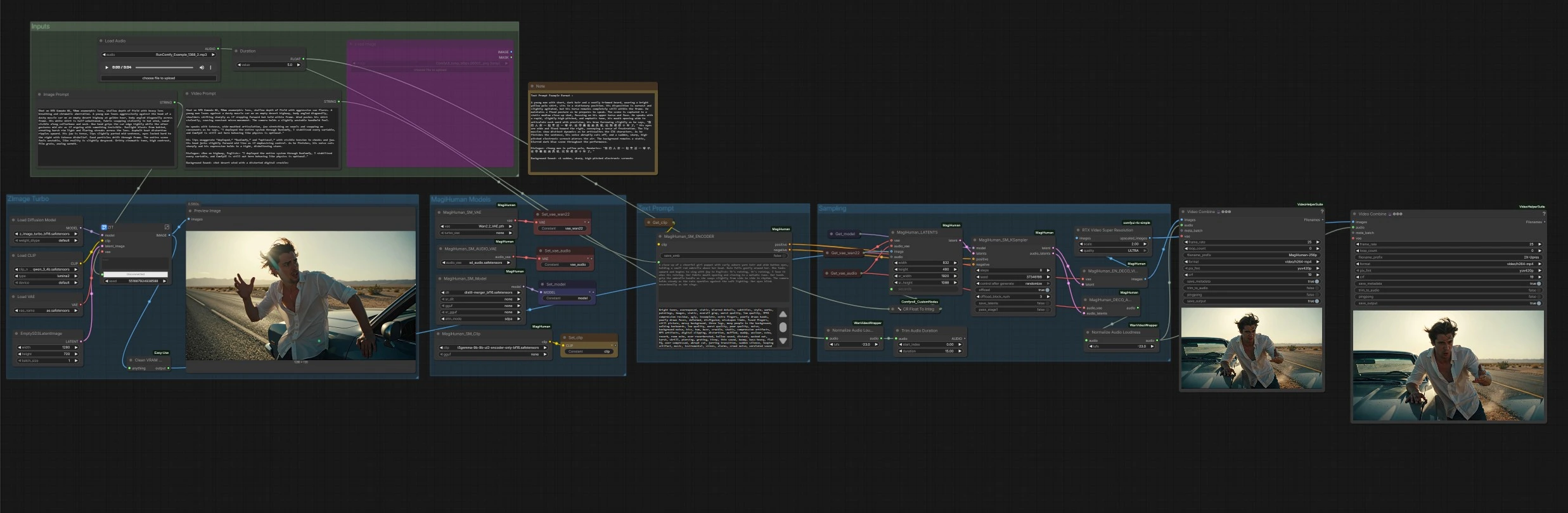
daVinci-MagiHuman рабочий процесс цифрового человека для ComfyUI#
Этот рабочий процесс ComfyUI строит полную текст-видео цепочку вокруг daVinci-MagiHuman для генерации реалистичных говорящих цифровых людей с синхронизированной речью, движением губ, выражением и микродвижениями тела. Он предназначен для создателей, которые хотят быстро и просто перейти от описательной подсказки к MP4 с чистым звуком. Граф может анимировать только что сгенерированный портрет или любое предоставленное изображение, затем рендерить видео и речь вместе, завершая с опциональным увеличением разрешения и автоматической нормализацией громкости аудио.
Ядро daVinci-MagiHuman использует одно-поточный Transformer для совместного создания видео и аудио из одной подсказки, что помогает сохранить временную синхронизацию и точность синхронизации губ даже на коротких клипах. Эта реализация ComfyUI упрощает управление: напишите Image Prompt для определения внешнего вида, Video Prompt для определения производительности и диалога, установите продолжительность клипа и запустите.
Ключевые модели в рабочем процессе ComfyUI daVinci-MagiHuman#
- daVinci-MagiHuman (15B одно-поточный генератор аудио-видео). Роль: совместно производит видеокадры и речь из текста, поддерживая временную согласованность и синхронизацию губ. Ссылки: GitHub, arXiv, Hugging Face.
- T5Gemma 9B энкодер (UL2-адаптированный). Роль: кодирует Video Prompt в богатую кондиционирование, которое управляет движением, подачей и стилем для daVinci-MagiHuman. Ссылка: Hugging Face.
- Z-Image Turbo диффузионная модель. Роль: быстро создает высококачественный неподвижный портрет из Image Prompt для использования в качестве идентичности/ссылки для анимации. Ссылки: Hugging Face (z_image_turbo), Hugging Face (z_image).
- Qwen 3 4B текстовый энкодер для Z-Image Turbo. Роль: разбирает Image Prompt для управления генерацией портрета. Ссылка: Hugging Face file.
- Wan 2.2 VAE. Роль: декодирует видео латенты MagiHuman в RGB кадры с сильной временной согласованностью. Ссылки: GitHub, Hugging Face пример модели.
- Audio VAE (sd_audio). Роль: декодирует аудио латенты MagiHuman в звуковую волну для совмещения с финальным видео. Ссылка: custom node bundle for MagiHuman GitHub.
- RTX Video Super Resolution (опционально). Роль: пост-увеличивает декодированные кадры для увеличения воспринимаемой резкости и уменьшения артефактов сжатия перед финальным кодированием. Ссылка: ComfyUI wrapper GitHub.
Как использовать рабочий процесс ComfyUI daVinci-MagiHuman#
Общий поток: группа Z-Image Turbo создает портрет идентичности из вашего Image Prompt. Группа моделей MagiHuman загружает контрольную точку daVinci-MagiHuman, видео VAE и аудио VAE и подготавливает текстовый энкодер. Группа Text Prompt превращает ваш Video Prompt в кондиционирование. Группа Sampling объединяет ссылочное изображение и подсказку в совместные видео и аудио латенты, затем декодирует оба. Наконец, стадия Outputs объединяет кадры с аудио в MP4, с опциональной увеличенной версией.
Входные данные#
Используйте текстовые поля Image Prompt и Video Prompt для описания внешнего вида и производительности. Контроль продолжительности устанавливает длину клипа в секундах. Для удобства предоставлен загрузчик аудио, если вы планируете экспериментировать с аудио-управляемыми вариантами, но этот шаблон по умолчанию работает в текст-управляемом режиме.
ZImage Turbo#
На этом этапе создается единичный ссылочный портрет из Image Prompt с использованием Z-Image Turbo UNet с текстовым энкодером Qwen 3 4B и его встроенным VAE. Он оптимизирован для быстрой, чистой генерации идентичности с кинематографическим внешним видом. Результат предварительно просматривается, затем передается как ссылочное изображение для анимации. Если у вас уже есть портрет, вы можете обойти этот этап, подключив ваше изображение напрямую к стадии анимации.
Модели MagiHuman#
Здесь граф загружает базовую или дистиллированную контрольную точку daVinci-MagiHuman вместе с Wan 2.2 видео VAE, аудио VAE и энкодером T5Gemma. Это сохраняет согласованность текстового кодирования, видео латентов и аудио латентов для одно-поточного семплирования. Вы можете заменить веса, если у вас есть альтернативы в вашей среде.
Текстовая подсказка#
Ваш Video Prompt кодируется в положительное и отрицательное кондиционирование. Положительный текст должен описывать расстояние до камеры, позу, язык, стиль подачи и точный диалог. Отрицательный текст может перечислять визуальные или аудио дефекты, которых следует избегать. Энкодер передает оба набора кондиционирования в семплер для формирования движения, динамики губ и тембра.
Семплирование#
Семплер строит начальную последовательность латентов из ссылочного изображения и запрашиваемой продолжительности, затем выполняет денойзинг с помощью daVinci-MagiHuman для создания синхронизированных видео и аудио латентов. Утилита конвертирует продолжительность в полные секунды для стабильного планирования. Когда семплирование завершено, видео латенты отправляются в видео декодер, а аудио латенты в аудио декодер.
Декодирование, громкость и экспорт#
Видео латенты декодируются с помощью Wan 2.2 VAE в кадры изображения. Аудио латенты декодируются в речь, затем нормализуются до уровня громкости, удобного для вещания, чтобы финальный MP4 воспроизводился стабильно на различных устройствах. Создаются два экспорта: базовый рендер и опциональный увеличенный рендер с использованием RTX Video Super Resolution. Оба объединяются в MP4 с аудио и сохраняются с понятными префиксами файлов.
Ключевые узлы в рабочем процессе ComfyUI daVinci-MagiHuman#
MagiHuman_LATENTS(#13)
Создает совместный латентный холст для видео и опционального аудио, принимая ссылочное изображение и длину клипа. Настройте seconds для установки продолжительности и убедитесь, что ваше ссылочное изображение хорошо кадрировано для описанного вами движения. Более высокое базовое разрешение помогает улучшить точность лица, но также увеличивает VRAM и время декодирования.
MagiHuman_SM_ENCODER(#95)
Кодирует Video Prompt в положительное и отрицательное кондиционирование для семплера. Поместите точную произнесенную фразу в кавычки и укажите язык для улучшения закрытия губ и синхронизации. Используйте отрицательное поле для подавления артефактов, таких как "субтитры," "статичность," или "эхо комнаты."
MagiHuman_SM_KSampler(#9)
Запускает денойзинг daVinci-MagiHuman для совместного создания видео и аудио латентов. seed управляет воспроизводимостью, а steps и внутренний график обменивают скорость на детализацию и стабильность движения. Для вариации без потери идентичности измените seed или слегка перефразируйте часть вашей подсказки, касающуюся производительности.
MagiHuman_EN_DECO_VIDEO(#5)
Декодирует видео латенты с помощью Wan 2.2 VAE в RGB кадры для экспорта или увеличения разрешения. Используйте этот путь для самого быстрого рендера; длинные клипы или более высокие разрешения линейно увеличат время декодирования.
MagiHuman_DECO_AUDIO(#6)
Декодирует аудио латенты в звуковую волну и отправляет их через нормализацию громкости для равномерного воспроизведения. Если вы позже переключитесь на аудио-управляемую генерацию, направьте ваше внешнее аудио в построитель латентов и сохраните этот путь декодирования для финального совмещения.
RTXVideoSuperResolution(#93)
Опциональный пост-увеличитель, который улучшает края и уменьшает звенение. Используйте умеренную силу для улучшения четкости без введения временного мерцания.
Дополнительные опции#
- Шаблон подсказки для надежной синхронизации губ: включите метку говорящего и язык, а также цитируемую фразу, например Dialogue: <Presenter, English>: "Welcome to the show." Добавьте краткую заметку о подаче, размере кадра и стабильности камеры.
- Сохраните ссылочный портрет как средний крупный план с полностью в кадре головой. Плотные кадрирования оставляют мало места для динамики челюсти и щек.
- Если вам нужна более строгая синхронизация, обрежьте или расширьте ваш сценарий, чтобы он соответствовал выбранной продолжительности. Очень длинные предложения в очень коротких клипах могут вынудить неестественную артикуляцию.
- Этот шаблон работает в режиме только подсказки. Для аудио-управляемых тестов подключите внешний аудиофайл к аудио входу на
MagiHuman_LATENTS(#13) и настройте ваш Video Prompt для описания выражения, а не содержания речи.
Благодарности#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы выражаем благодарность daVinci-MagiHuman за daVinci-MagiHuman Workflow Source за их вклад и поддержку. Для авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, указанным ниже.
Ресурсы#
- daVinci-MagiHuman/Workflow Source
- Документы / Примечания к выпуску: daVinci-MagiHuman Workflow Source
Примечание: Использование ссылочных моделей, наборов данных и кода подлежит соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими.