
Wan 2.2 VACE pose-driven video generation for ComfyUI#
This ComfyUI Wan 2.2 VACE workflow turns a single reference image into a motion-matched video that follows the pose, rhythm, and camera movement of a source clip. It uses Wan 2.2 VACE to preserve identity while translating complex body motion into smooth, realistic animation.
Designed for dance generation, motion transfer, and creative character animation, the workflow automates style prompting from the reference image, extracts motion signals from the source video, and runs a two-stage Wan 2.2 sampler that balances motion coherence and fine detail.
Key models in Comfyui Wan 2.2 VACE workflow#
- Wan 2.2 14B Text-to-Video models (high-noise and low-noise variants). Dual stages use a high-noise backbone for robust motion shaping followed by a low-noise backbone for detail refinement.
- Wan 2.1 VAE (bf16). Decodes and encodes latent video frames for Wan 2.2 VACE.
- Google UMT5-XXL Encoder. Provides high-capacity text features used by Wan 2.2 for conditioning. Model card
- Microsoft Florence-2 (Flux Large). Generates a rich caption from the reference image to bootstrap and stylize the prompt. Repo
- Depth Anything v2 (ViT-L). Produces per-frame depth maps from the motion source video to guide structure and movement. Repo
How to use Comfyui Wan 2.2 VACE workflow#
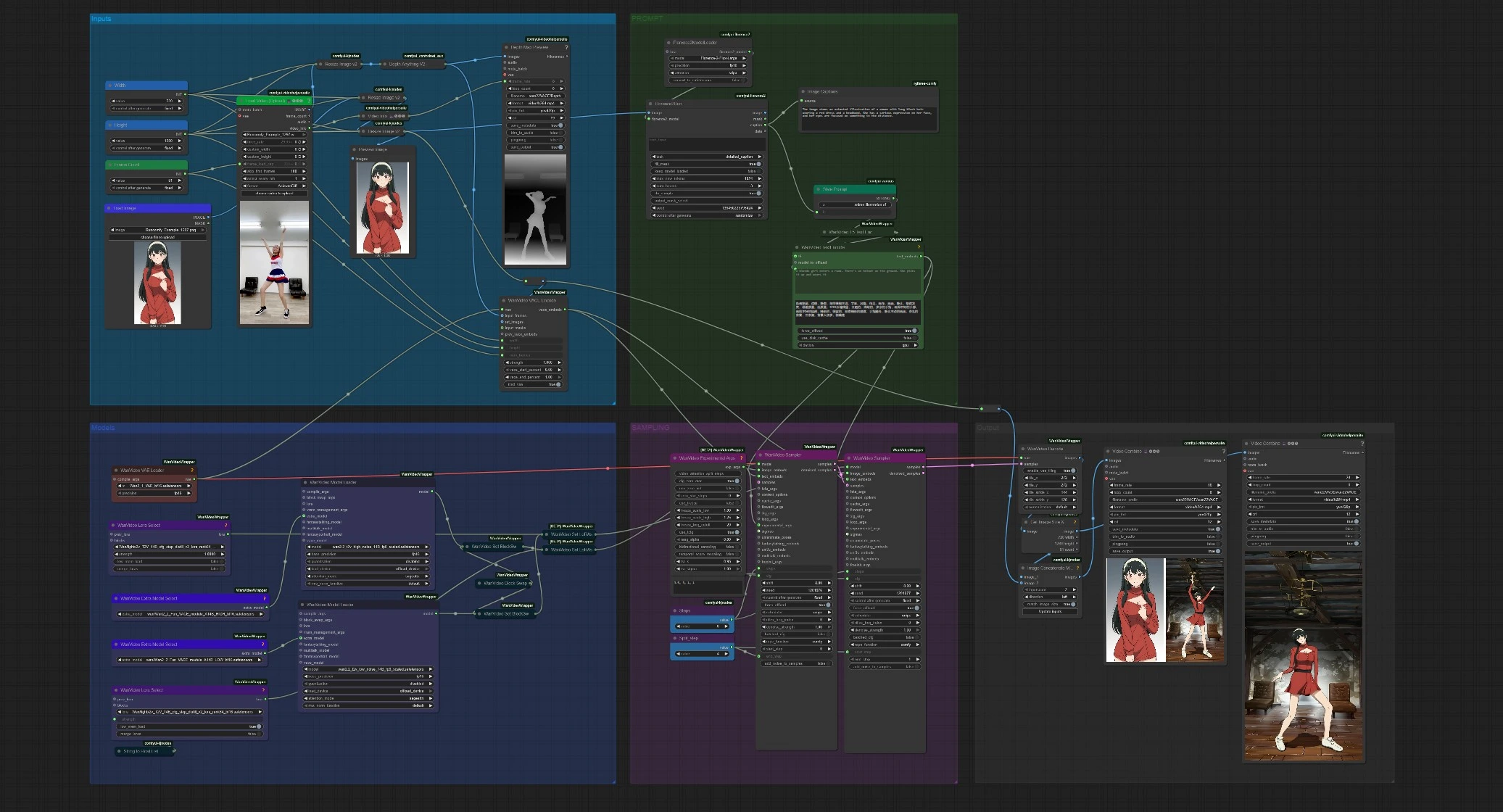
The workflow has five grouped stages: Inputs, PROMPT, Models, SAMPLING, and Output. You provide one reference image and one short motion video. The graph then computes motion guidance, encodes VACE identity features, runs a two-pass Wan 2.2 sampler, and saves both the final animation and an optional side-by-side preview.
Inputs#
Load a motion source clip in VHS_LoadVideo (#141). You can trim with simple controls and cap frames for memory. The frames are resized for consistency, then DepthAnythingV2Preprocessor (#135) computes a dense depth sequence that captures pose, layout, and camera movement. Load your identity image with LoadImage (#113); it is auto-resized and previewed so you can verify framing before sampling.
PROMPT#
Florence2Run (#137) analyzes the reference image and returns a detailed caption. Style Prompt (#138) concatenates that caption with a short style phrase, then WanVideoTextEncode (#16) encodes the final positive and negative prompts using UMT5-XXL. You can freely edit the style phrase or replace the positive prompt entirely if you want stronger creative direction. This prompt embedding conditions both sampler stages so the generated video stays faithful to your reference.
Models#
WanVideoVAELoader (#38) loads the Wan VAE used across encode/decode. Two WanVideoModelLoader nodes prepare Wan 2.2 14B models: one high-noise and one low-noise, each augmented with a VACE module selected in WanVideoExtraModelSelect (#99, #107). Optional refinement LoRA is attached through WanVideoLoraSelect (#56, #97), letting you nudge sharpness or style without changing the base models. The configuration is designed so you can swap VACE weights, LoRA, or the noise variant without touching the rest of the graph.
SAMPLING#
WanVideoVACEEncode (#100) fuses three signals into VACE embeddings: the motion sequence (depth frames), your reference image, and the target video geometry. The first WanVideoSampler (#27) runs the high-noise model up to a split step to establish motion, perspective, and global style. The second WanVideoSampler (#90) resumes from that latent and finishes with the low-noise model to recover textures, edges, and small details while keeping motion locked to the source. A short CFG schedule and step split control how much each stage influences the result.
Output#
WanVideoDecode (#28) converts the final latent back to frames. You get two saved videos: a clean render and a side-by-side concat that places the generated frames next to the reference for quick QA. A separate “Depth Map Preview” shows the inferred depth sequence so you can diagnose motion guidance at a glance. Frame rate and filename settings are available in the VHS_VideoCombine outputs (#139, #60, #144).
Key nodes in Comfyui Wan 2.2 VACE workflow#
WanVideoVACEEncode (#100)#
Creates the VACE identity-and-geometry embeddings used by both samplers. Supply your motion frames and the reference image; the node handles width, height, and frame count. If you change duration or aspect, keep this node in sync so the embeddings match your target video layout.
WanVideoSampler (#27)#
First-stage sampler using the high-noise Wan 2.2 model. Tune steps, a short cfg schedule, and the end_step split to decide how much of the trajectory is allocated to motion shaping. Larger motion or camera changes benefit from a slightly later split.
WanVideoSampler (#90)#
Second-stage sampler using the low-noise Wan 2.2 model. Set start_step to the same split value so it continues seamlessly from stage one. If you see texture oversharpening or drift, reduce the later cfg values or lower LoRA strength.
DepthAnythingV2Preprocessor (#135)#
Extracts a stable depth sequence from the source video. Using depth as motion guidance helps Wan 2.2 VACE retain scene layout, hand pose, and occlusion. For fast iteration, you can resize input frames smaller; for final renders, feed higher-resolution frames for better structural fidelity.
WanVideoTextEncode (#16)#
Encodes the positive and negative prompts with UMT5-XXL. The prompt is auto-built from Florence2Run, but you can override it for art-direction. Keep prompts concise; with VACE identity guidance, fewer keywords often yield cleaner, less constrained motion transfer.
Optional extras#
- Choose motion clips with clear subject separation and consistent lighting for the most stable Wan 2.2 VACE transfers.
- Use the side-by-side output to verify face alignment and outfit continuity before rendering a final pass.
- If motion looks too stiff, move the split a bit earlier so the low-noise stage has more room to refine.
- If identity is drifting, increase LoRA influence slightly or simplify the prompt.
- Depth preview is your friend: if depth is noisy, try a different source clip or adjust input resizing to reduce artifacts.
Acknowledgements#
This workflow implements and builds upon the following works and resources. We gratefully acknowledge the ComfyUI community creators of Wan 2.2 VACE Source for the workflow, for their contributions and maintenance. For authoritative details, please refer to the original documentation and repositories linked below.
Resources#
- Wan 2.2 VACE Source/Wan 2.2 VACE Source
- Docs / Release Notes: Wan 2.2 VACE @ComfyUI
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.