
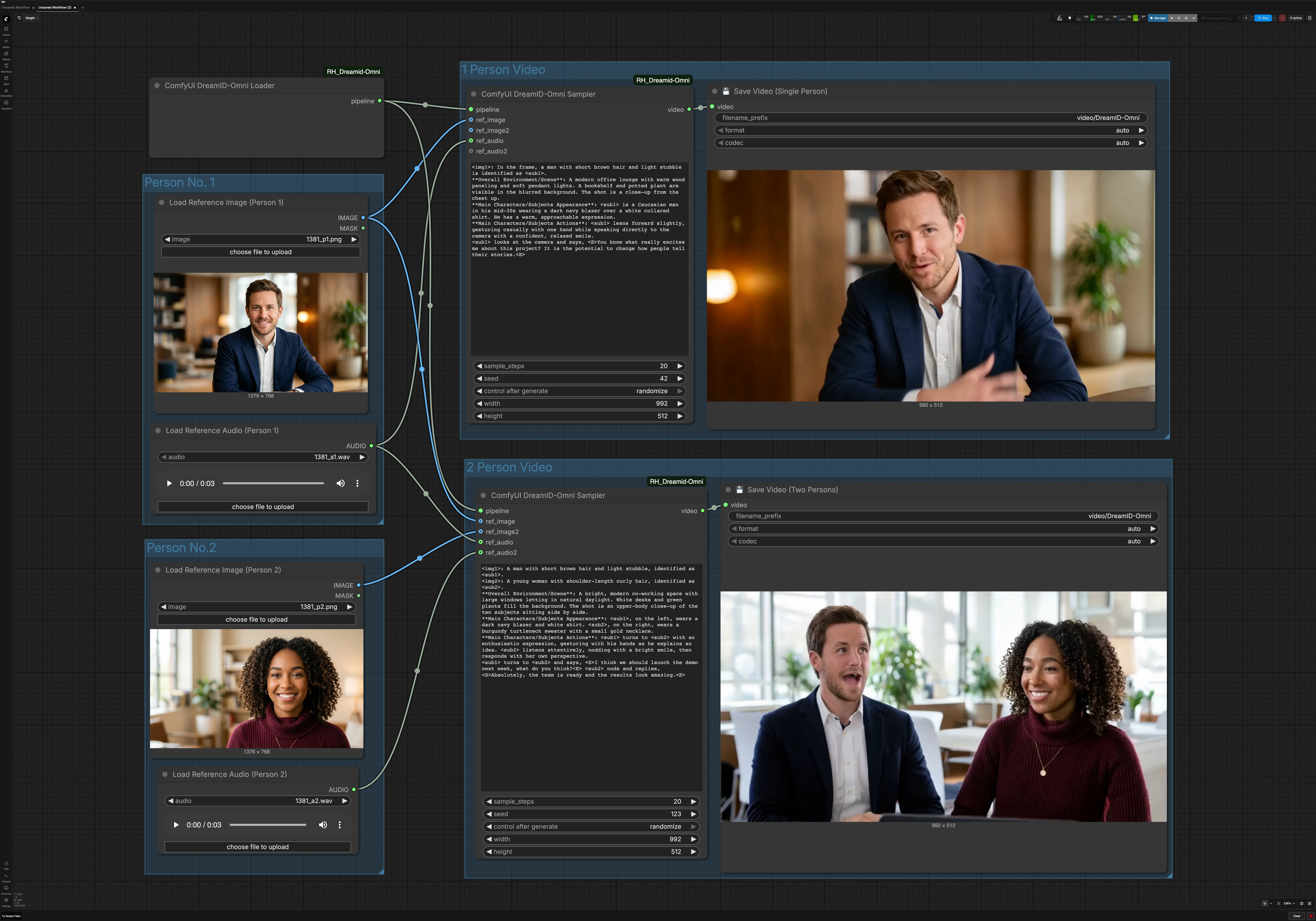
DreamID-Omni 單人及雙人角色對話影片工作流程在 ComfyUI 中的應用#
此工作流程將單張參考照片及音頻片段轉換成保持身份特徵的對話頭影片。由 DreamID-Omni 模型驅動,它將現代影片骨幹與 MMAudio 驅動的唇部運動結合,讓主題自然說話,同時保持你的影像中的面孔。它還支持兩個角色,實現由兩個聲音驅動的並排對話片段。
專為創作者、產品團隊及研究人員設計,DreamID-Omni 工作流程在 ComfyUI 中非常適合數位化身、個性化公告、教程介紹及 AI 對話場景。你提供照片和音頻,並可選擇在短提示中描述拍攝,圖表會生成一個精緻的影片,隨時可分享。
Comfyui DreamID-Omni 工作流程中的關鍵模型#
- DreamID-Omni。核心身份模組在影格間保持你參考影像中的個人,同時響應音頻實現真實的唇部運動。詳情請參見官方 repo 和權重:DreamID-Omni 和 DreamID-Omni on Hugging Face。
- Wan 2.2 影片生成。一個高容量的影片擴散骨幹,能合成一致的運動、光照和拍攝構圖,而 DreamID-Omni 控制面部身份。
- MMAudio。一個音頻表示模型,條件化口型和細微的面部提示與提供的語音對齊,提高唇同步的真實性。
如何使用 Comfyui DreamID-Omni 工作流程#
此圖表有兩條平行路徑。單人路徑使用一張圖片和一個音頻。雙人路徑使用兩張圖片和兩個音頻來生成對話片段。共享的 DreamID-Omni 加載器初始化兩者的管道。
人物 1#
使用 Load Reference Image (Person 1) (#6) 選擇一個清晰、正面照的肖像,光線均勻且遮擋最小。使用 Load Reference Audio (Person 1) (#7) 提供你希望角色說的語音。越乾淨的音頻會產生更好的唇同步,因此選擇沒有音樂或強背景噪音的語音。這對於單人模式以及啟用時的雙人模式中的左或第一個主題都是共用的。
人物 2#
在創建對話時,使用 Load Reference Image (Person 2) (#9) 和 Load Reference Audio (Person 2) (#11)。選擇一張與人物 1 的構圖匹配的照片以保持平衡。確保第二個音頻的音量與第一個相似,以避免突然的感知變化。如果你只製作單人片段,則可以忽略此組。
單人影片#
單人演講路徑由 ComfyUI DreamID-Omni Sampler (#21) 驅動。它將 DreamID-Omni 管道與人物 1 的照片和音頻融合,然後根據節點提示區的簡短場景描述生成一致的拍攝。保持提示簡潔實用,例如描述背景、鏡頭距離和舉止。結果由 💾 Save Video (Single Person) (#4) 寫入,為你命名並導出文件。
雙人影片#
對話路徑使用 ComfyUI DreamID-Omni Sampler (#22) 在一個畫面中合成兩個身份,並用其配對音頻驅動每個嘴巴。提供一個簡短的提示來設置環境和互動風格,例如協作空間、隨意語氣或誰先說話。這有助於穩定相機位置和手勢,同時 DreamID-Omni 和 MMAudio 保持身份和唇部對齊。片段由 💾 Save Video (Two Persons) (#5) 導出。
共享 DreamID-Omni 管道#
ComfyUI DreamID-Omni Loader (#23) 初始化兩條路徑使用的 DreamID-Omni 組件。通常你不需要調整這裡的任何內容。只要權重和 ComfyUI 節點可用,加載器就會準備管道以便取樣器渲染。
Comfyui DreamID-Omni 工作流程中的關鍵節點#
ComfyUI DreamID-Omni Loader (#23)#
初始化 DreamID-Omni 管道並使其權重可供下游取樣器使用。這裡沒有典型的用戶輸入。如果你維護多個模型變體,請在排隊渲染前確認正確的權重已安裝。
ComfyUI DreamID-Omni Sampler (#21)#
單人渲染。此節點將加載器管道與第一個參考影像和音頻結合,以合成保持身份特徵的對話頭。提示欄位是你定義場景和舉止的地方;種子控制可重複性;解析度決定構圖和面部細節;步驟以速度換取保真度。為了在多次拍攝中獲得一致的結果,重用相同的種子,並保持提示變化最小。
ComfyUI DreamID-Omni Sampler (#22)#
雙人渲染。此實例接收兩張照片和兩個音頻,將每個聲音與其主題配對,以實現同步的唇部運動。提示可以安排對話和相機佈局。像單人模式一樣調整種子和解析度,並確保兩個音頻修剪到所需時間再渲染。
💾 Save Video (Single Person) (#4)#
將單人演講輸出寫入磁盤。設置文件夾或基名以保持版本有序。如果可用,當你不確定時,將編解碼器和幀速率選項設為自動。
💾 Save Video (Two Persons) (#5)#
將對話輸出寫入磁盤。使用不同的基名以便單人和雙人片段易於區分。保持自動導出設置的可靠性,除非你有特定的交付需求。
可選附加項#
- 確保參考影像中的面孔足夠大,以佔據畫面中有意義的部分,以加強身份鎖定。
- 使用乾淨、音量均勻的語音音頻。修剪開頭的沉默以避免最初的嘴唇凍結。
- 為了更穩定的外觀,在迭代提示或裝束時重用相同的種子。
- 如果雙人間距感覺緊湊,重新措辭提示以拓寬相機或增加肩部空間,而不是裁剪面孔。
- 有關資產和更新,請參見官方模型和節點:DreamID-Omni、ComfyUI_RH_Dreamid-Omni 和 DreamID-Omni weights。
致謝#
此工作流程實現並基於以下作品和資源。我們感謝 Guoxu1233 提供的 DreamID-Omni 模型/工作流程,HM-RunningHub 提供的 DreamID-Omni ComfyUI 節點,以及 XuGuo699 提供的 DreamID-Omni 模型權重的貢獻和維護。請參閱以下鏈接的原始文檔和倉庫以獲取權威信息。
資源#
- DreamID-Omni 官方倉庫 - https://github.com/Guoxu1233/DreamID-Omni
- GitHub: Guoxu1233/DreamID-Omni
- DreamID-Omni ComfyUI 節點 (RunningHub) - https://github.com/HM-RunningHub/ComfyUI_RH_Dreamid-Omni
- DreamID-Omni 模型權重 (Hugging Face) - https://huggingface.co/XuGuo699/DreamID-Omni
- Hugging Face: XuGuo699/DreamID-Omni
注意:所引用的模型、數據集和代碼的使用受其作者和維護者提供的各自許可和條款的約束。
