
Pose Control LipSync with Wan2.2 S2V: audio‑driven, pose‑controlled image‑to‑video for expressive avatars#
Pose Control LipSync with Wan2.2 S2V turns a single image, an audio clip, and a pose reference video into a synchronized talking performance. The character in your reference image follows the reference video’s body motion while lip movements match the audio. This ComfyUI workflow is ideal for avatars, story scenes, trailers, explainers, and music videos where you want tight control over pose, expression, and speech timing.
Built on the Wan 2.2 S2V 14B model family, the workflow fuses text prompts, clean vocal features, and pose maps to generate cinematic motion with stable identity. It is designed to be simple to operate while giving creators fine control over look, pacing, and framing.
Key models in Comfyui Pose Control LipSync with Wan2.2 S2V workflow#
- Wan2.2‑S2V‑14B. The core speech‑to‑video generator that transforms a still image plus audio into video, with optional pose conditioning for motion guidance. See the official repository and model card for capabilities and usage notes: Wan‑Video/Wan2.2 and Wan‑AI/Wan2.2‑S2V‑14B.
- Wan VAE. The Wan autoencoder encodes and decodes video latents with high fidelity and is used across Wan 2.x pipelines. Reference implementation: Wan pipelines in Diffusers documentation.
- Google UMT5‑XXL text encoder. Provides strong multilingual text conditioning for high‑level scene intent and style control within Wan pipelines. Model card: google/umt5‑xxl.
- Facebook Wav2Vec2‑Large. Extracts robust speech features that drive lip sync and micro‑expression. Model card: facebook/wav2vec2‑large‑960h.
- DWPose with YOLOX detector. Generates human pose keypoints and pose maps from the reference video to guide full‑body movement. Repos: IDEA‑Research/DWPose and Megvii‑BaseDetection/YOLOX.
- LightX2V LoRA for Wan. A lightweight LoRA used to accelerate low‑step image‑to‑video style denoising while preserving motion quality; Wan 2.2 supports LoRAs in its denoisers. See the Wan Diffusers guidance on LoRA usage in Wan pipelines.
How to use Comfyui Pose Control LipSync with Wan2.2 S2V workflow#
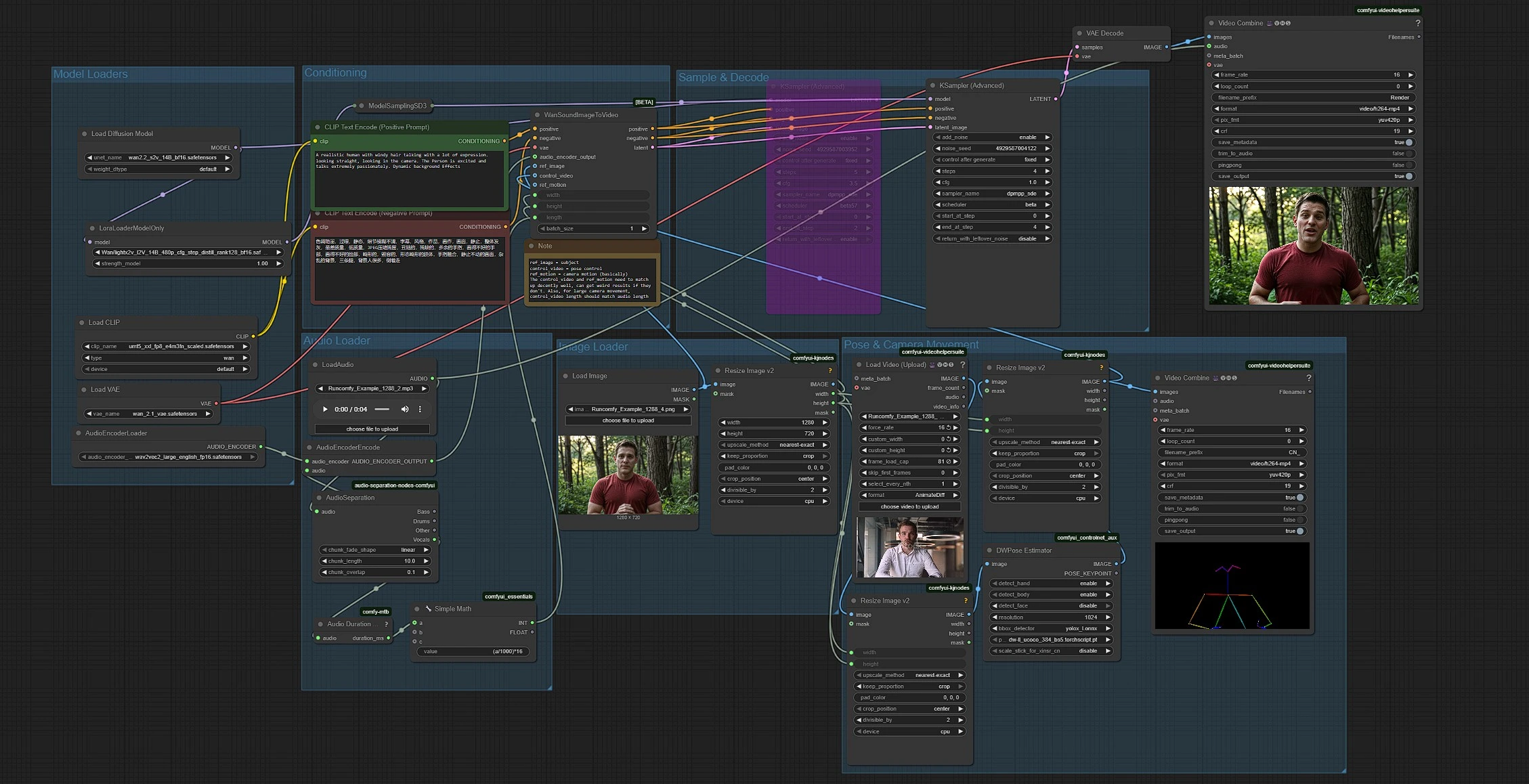
The workflow combines five parts: model loading, audio preparation, image and pose inputs, conditioning, and generation. Groups run in a left‑to‑right flow, with audio length automatically setting clip duration at 16 fps.
Model Loaders#
This group loads the Wan 2.2 S2V model, its VAE, the UMT5‑XXL text encoder, and a LightX2V LoRA. The base transformer is initialized in UNETLoader (#37) and adapted with LoraLoaderModelOnly (#61) for faster low‑step sampling. The Wan VAE is supplied by VAELoader (#39). Text encoders are provided by CLIPLoader (#38) which loads the UMT5‑XXL weights referenced by Wan. You rarely need to touch this group unless you swap model files.
Audio Loader#
Drop in an audio file with LoadAudio (#58). AudioSeparation (#85) isolates the vocal stem so the lips follow clear speech or singing rather than background instruments. Audio Duration (mtb) (#70) measures the clip and SimpleMath+ (#71) converts duration to a frame count at 16 fps so the video length matches your audio. AudioEncoderEncode (#56) feeds a Wav2Vec2‑Large encoder so Wan can map phonemes to mouth shapes for accurate lip sync.
Image Loader#
LoadImage (#52) provides the subject still that carries identity, clothing, and camera setup. ImageResizeKJv2 (#69) reads dimensions from the image so the pipeline consistently derives target width and height for all later stages. Use a sharp, front‑facing image with an unobstructed mouth for the most faithful lip movements.
Pose & Camera Movement#
VHS_LoadVideo (#80) imports your pose reference video. ImageResizeKJv2 (#83) adapts frames to the target size, and DWPreprocessor (#78) turns them into pose maps with YOLOX detection plus DWPose keypoints. A final ImageResizeKJv2 (#81) aligns pose frames to the generation resolution before they are passed forward as the control video. You can preview pose outputs by routing to VHS_VideoCombine (#95), which helps confirm that the reference framing and timing fit your subject.
Conditioning#
Write the style and scene intent in CLIP Text Encode (Positive Prompt) (#6) and use CLIP Text Encode (Negative Prompt) (#7) to discourage unwanted artifacts. Prompts steer high‑level aesthetics and background motion, while the audio drives lip movements and the pose reference governs body dynamics. Keep prompts concise and aligned with your target camera angle and mood.
Sample & Decode#
WanSoundImageToVideo (#55) fuses text, audio features, the reference image, and the pose control video, then prepares a latent sequence. KSamplerAdvanced (#64) performs low‑step denoising suited to LightX2V‑style acceleration, and VAEDecode (#8) reconstructs frames. VHS_VideoCombine (#62) assembles frames into an MP4 and attaches your original audio so the output is ready to review or edit.
Key nodes in Comfyui Pose Control LipSync with Wan2.2 S2V workflow#
WanSoundImageToVideo (#55)#
The heart of the workflow that conditions Wan2.2‑S2V with your prompt, vocals, subject image, and pose control video. Adjust only what matters: set width, height, and length to match your subject image and audio length, and plug a preprocessed pose video for motion control. Leave ref_motion empty unless you plan to inject a separate camera track. The model’s speech‑to‑video behavior is described in Wan‑AI/Wan2.2‑S2V‑14B and Wan‑Video/Wan2.2.
DWPreprocessor (#78)#
Generates pose maps using YOLOX for detection and DWPose for whole‑body keypoints. Strong pose cues help Wan follow limbs and torso while audio controls lips and expressions. If your reference has heavy camera motion, use a pose video that aligns viewpoint and timing with the intended performance. DWPose and its variants are documented in IDEA‑Research/DWPose.
KSamplerAdvanced (#64)#
Executes denoising for the latent sequence. With a LightX2V LoRA loaded, you can keep steps low for fast previews while retaining motion coherence; increase steps when pushing for maximum detail. Scheduler choices affect motion smoothness versus crispness, and should be tuned together with LoRA usage as outlined for Wan in the Diffusers documentation.
VHS_LoadVideo (#80)#
Imports and scrubs your pose reference. Use its in‑node frame selection tools to pick the exact segment that matches your audio segment. Keeping framing and subject size consistent with the reference image will stabilize motion transfer. The node is part of VideoHelperSuite: ComfyUI‑VideoHelperSuite.
VHS_VideoCombine (#62)#
Combines generated frames and your audio into an MP4 and saves workflow metadata. Set the output frame rate to 16 fps to match the frame count computed from audio duration in this workflow. Disable or enable metadata saving depending on your asset management needs. See VideoHelperSuite documentation at ComfyUI‑VideoHelperSuite.
AudioSeparation (#85)#
Isolates vocals so Wav2Vec2 features drive mouth shapes without interference from instruments or FX. If your input is already clean speech, you can bypass separation. For best results, keep audio levels consistent and minimize reverb.
Optional extras#
- For best lip sync, prefer clean speech or acapella vocals. Wav2Vec2 works at 16 kHz; most pipelines resample automatically, but supplying 16 kHz files helps.
- Use a well‑lit, front‑facing subject image with visible teeth and lips. Occlusions reduce accuracy.
- Match the pose reference’s framing and movement to your subject. Large camera moves work best when the pose video length matches the audio segment.
- Start at 480p for quick iteration; move to 720p for final quality. Wan 2.2 supports both resolutions in S2V.
- Keep prompts short and consistent with the camera setup in your image and pose reference to avoid conflicts.
- If you experiment with LoRAs, ensure they are compatible with Wan 2.2 denoisers. See LoRA notes in the Wan Diffusers docs.
This Pose Control LipSync with Wan2.2 S2V workflow gives you a fast path from audio and a still image to a controllable, on‑beat performance that looks cohesive and feels expressive.
Acknowledgements#
This workflow implements and builds upon the following works and resources. We gratefully acknowledge @ArtOfficialLabs of Pose Control LipSync with Wan2.2 S2VDemo for their contributions and maintenance. For authoritative details, please refer to the original documentation and repositories linked below.
Resources#
- YouTube/Pose Control LipSync with Wan2.2 S2VDemo
- Docs / Release Notes from @ArtOfficialLabs: Pose Control LipSync with Wan2.2 S2VDemo
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.