
ACE-Step 1.5XL Base текст в музыку: Рабочий процесс от подсказки к песне для ComfyUI#
Этот рабочий процесс превращает описания на естественном языке в готовое аудио, используя семейство диффузий ACE-Step 1.5XL Base. Он сочетает базовую модель с её ACE Step VAE и двойными текстовыми кодировщиками Qwen, чтобы результаты оставались в музыкальной области, а не в TTS или речи. Если вам нужна AI музыка, основанная на подсказках, с предсказуемой структурой, темпами и инструментовкой, этот рабочий процесс ACE-Step 1.5XL Base текст в музыку — это сфокусированная, минимальная настройка, которая быстро переводит вас от идеи к MP3.
Разработанный для продюсеров, звуковых дизайнеров и создателей, график подчеркивает ясность: выберите модели, установите продолжительность, напишите музыкальную подсказку, затем создайте и сохраните. Рабочий процесс ACE-Step 1.5XL Base текст в музыку достаточно компактный для быстрой итерации, оставаясь выразительным для детализированных аранжировок, ключей и темпов.
Ключевые модели в рабочем процессе Comfyui ACE-Step 1.5XL Base текст в музыку#
- ACE-Step 1.5 XL Base (bf16) модель диффузии. Генеративная основа, которая устраняет шум аудиолатентов в связные музыкальные фразы и текстуры. Файл модели
- ACE Step 1.5 VAE. Парный вариационный автоэнкодер, который кодирует/декодирует между латентным пространством и доменом волновой формы, сохраняя тембр и баланс микса. Файл модели
- Qwen 4B ACE15 текстовый кодировщик. Большой текстовый кодировщик, адаптированный для ACE, который улавливает богатую музыкальную семантику, структуру и аранжировочные подсказки из подсказки. Файл модели
- Qwen 0.6B ACE15 текстовый кодировщик. Более легкий кодировщик, адаптированный для ACE, который приоритизирует скорость и эффективность ресурсов, сохраняя сильное понимание подсказок. Файл модели
Как использовать рабочий процесс Comfyui ACE-Step 1.5XL Base текст в музыку#
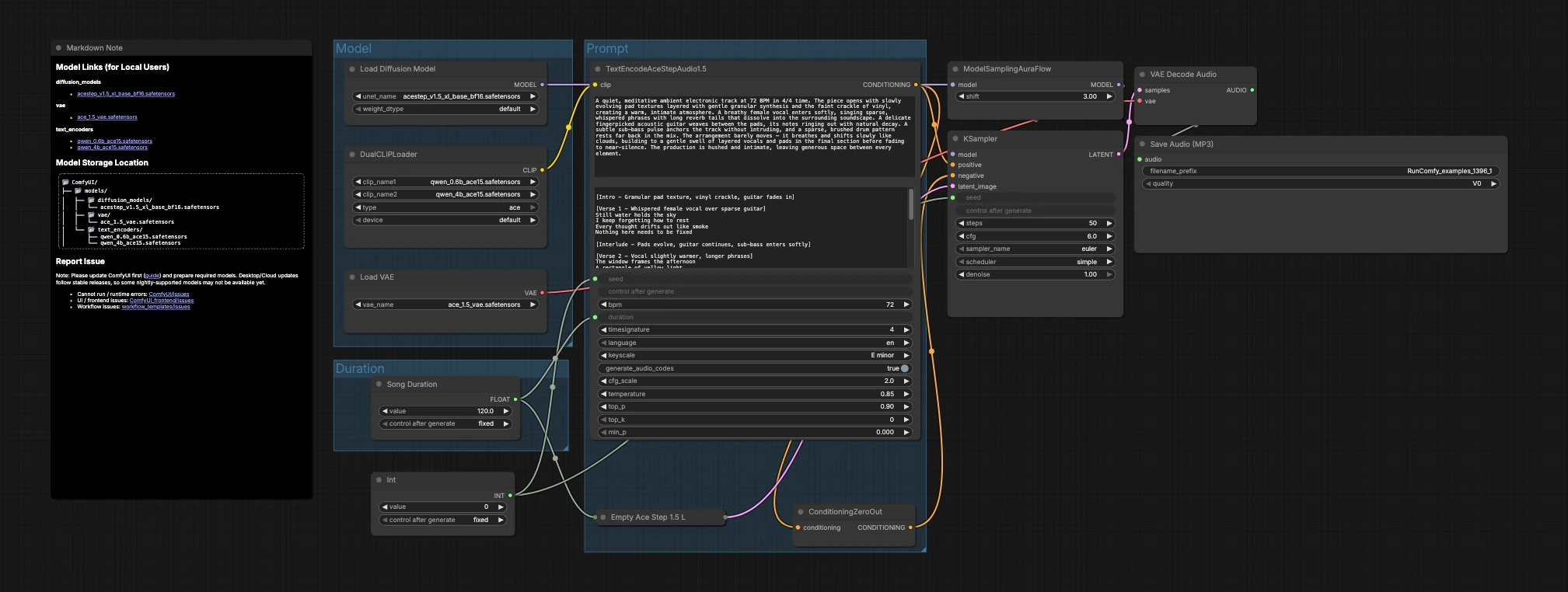
График организован в три группы, которые переходят в генерацию и экспорт: Модель, Продолжительность и Подсказка. Вы загружаете модели, выбираете целевую длину, описываете музыку, затем семплер создает латенты, которые VAE декодирует в аудио.
Модель#
Эта группа загружает основные ресурсы. UNETLoader (#104) выбирает контрольную точку диффузии ACE-Step 1.5 XL Base, а VAELoader (#106) загружает соответствующий ACE Step 1.5 VAE, чтобы качество декодирования соответствовало обучению. DualCLIPLoader (#105) включает оба кодировщика Qwen ACE15; рабочий процесс использует их совместно, чтобы богатые текстовые подсказки переводились в сильное музыкальное условие.
Продолжительность#
Здесь вы решаете, какой длины должно быть произведение. Song Duration (#99) устанавливает целевую длину в секундах и передает её вперед, чтобы латентное полотно и текстовое условие совпадали. PrimitiveInt (#109) предоставляет семя, позволяя вам фиксировать точные результаты для воспроизводимости или менять его для изучения альтернативных вариантов.
Подсказка#
Здесь язык становится музыкой. Напишите свое описание в TextEncodeAceStepAudio1.5 (#94), включая полезные музыкальные метаданные, такие как темп (BPM), размер, ключ, инструментовка, аранжировка, наличие вокала и заметки о миксе. Узел излучает положительное условие; ConditioningZeroOut (#47) обеспечивает нейтральный отрицательный путь, чтобы генерация оставалась сосредоточенной на вашем описании. EmptyAceStep1.5LatentAudio (#98) инициализирует латентную аудиоленту на выбранную продолжительность. ModelSamplingAuraFlow (#78) адаптирует базовую модель к планировщику, подходящему для ACE-Step аудио. KSampler (#3) комбинирует модель, условие, латент и семя для генерации музыкального латента. VAEDecodeAudio (#18) преобразует латент обратно в волновую форму, а SaveAudioMP3 (#107) записывает результат в MP3 файл, готовый для обмена.
Ключевые узлы в рабочем процессе Comfyui ACE-Step 1.5XL Base текст в музыку#
TextEncodeAceStepAudio1.5 (#94)#
Преобразует вашу подсказку в условие, которое может следовать модель диффузии. Он принимает музыкальные детали, такие как темп, размер, ключ, заметки об аранжировке, инструментовку, язык и намерение вокала. Для наилучших результатов будьте конкретны в отношении жанра, ощущения и размещения микса, и сохраняйте структурные подсказки краткими, чтобы модель могла поддерживать связность в течение запрошенной длительности.
EmptyAceStep1.5LatentAudio (#98)#
Создает латентное аудио "полотно" для произведения. Соответствуйте его секунды тому, что вы установили в Song Duration (#99) и упомянули в текстовом кодировщике, чтобы избежать непреднамеренного обрезания или добавления. Более длинные полотна приглашают более постепенное развитие, в то время как более короткие подходят для циклов, сигналов и джинглов.
ModelSamplingAuraFlow (#78)#
Настраивает стратегию семплирования, адаптированную для ACE-Step аудио. Используйте её как предоставлено для стабильных результатов; настраивайте только если у вас есть конкретное предпочтение планировщика, так как это взаимодействует с количеством шагов и направлением в KSampler (#3).
KSampler (#3)#
Выполняет устранение шума, которое превращает условие в аудиолатенты. Ключевые рычаги здесь — тип семплера, количество шагов и семя. Увеличивайте шаги, чтобы уточнить детали за счет времени, и сохраняйте семя фиксированным при сравнении подсказок, чтобы вы могли приписывать изменения тексту, а не случайности.
DualCLIPLoader (#105)#
Загружает оба текстовых кодировщика Qwen ACE15. Если у вас есть доступ к обоим, начните с активного кодировщика 4B для более богатого понимания языка; переключайтесь на вариант 0.6B, когда вам нужны более быстрые итерации или меньшее использование памяти. Держите выбор кодировщика постоянным в течение съемок при оценке тонких правок подсказок.
ConditioningZeroOut (#47)#
Обеспечивает нейтральный отрицательный путь. Если вы хотите подавить определенные артефакты или отказаться от речевого контента, вы можете заменить это на реальный узел отрицательной подсказки; в противном случае обнуленный отрицательный оставляет генерацию ACE-Step 1.5XL Base текст в музыку сосредоточенной на вашем положительном описании.
Дополнительные опции#
- Начинайте подсказки с компактного рецепта: жанр + настроение + темп + размер + ключ + инструментовка + аранжировка + заметки о миксе.
- Используйте явные музыкальные глаголы и роли (лид, пад, бас, ударные), чтобы модель размещала пространство в миксе и избегала контента, похожего на речь.
- Фиксируйте семя при A/B тестировании подсказок, затем варьируйте семя, чтобы изучить альтернативные исполнения выигрышной идеи.
- Держите продолжительность согласованной между
Song Duration(#99),TextEncodeAceStepAudio1.5(#94) иEmptyAceStep1.5LatentAudio(#98) для предсказуемой фразировки. - Выбирайте Qwen 4B для более богатого понимания подсказок или 0.6B для скорости; держите ваш выбор постоянным, пока вы итеративно делаете сравнения справедливыми.
Благодарности#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы с благодарностью отмечаем Comfy.org за рабочий процесс audio_ace_step1_5_xl_base, Comfy-Org за модель диффузии ACE Step 1.5 XL Base и ACE Step 1.5 VAE, а также команду Qwen за текстовые кодировщики 0.6B и 4B ACE15 за их вклад и поддержку. Для авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, приведенным ниже.
Ресурсы#
- Comfy.org/Workflow source page
- Документы / Примечания к выпуску: audio_ace_step1_5_xl_base workflow page
- Comfy-Org/ACE Step 1.5 XL Base diffusion model
- Hugging Face: acestep_v1.5_xl_base_bf16.safetensors
- Comfy-Org/ACE Step 1.5 VAE
- Hugging Face: ace_1.5_vae.safetensors
- Comfy-Org/Qwen 0.6B ACE15 text encoder
- Hugging Face: qwen_0.6b_ace15.safetensors
- Comfy-Org/Qwen 4B ACE15 text encoder
- Hugging Face: qwen_4b_ace15.safetensors
Примечание: Использование упомянутых моделей, наборов данных и кода подлежит соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими организациями.