
Stable Audio Open 1.0 Text-to-Music Workflow#
This workflow turns plain text into original music and soundscapes using Stable Audio Open 1.0. It is designed for composers, sound designers, and creators who want fast, controllable audio generation without leaving ComfyUI. You write a prompt, set a target duration, and the graph renders an MP3 that reflects your style, mood, tempo, and instrumentation.
Under the hood, the workflow encodes your text with a T5-based text encoder, runs Stable Audio’s diffusion process in the latent audio space, then decodes to a waveform and saves the result. With clear prompt guidance and a simple length control, Stable Audio generation becomes predictable and repeatable for cinematic, ambient, or experimental tracks.
Key models in Comfyui Stable Audio workflow#
- Stable Audio Open 1.0. Open-weights latent diffusion model for text-to-music and sound design by Stability AI. It maps text intent to audio latents and supports varied musical styles and structures. Repository • Weights
- T5-Base Text Encoder. General-purpose text model used here to embed prompts for conditioning Stable Audio generation. Clear, descriptive inputs lead to more consistent music. Model card
How to use Comfyui Stable Audio workflow#
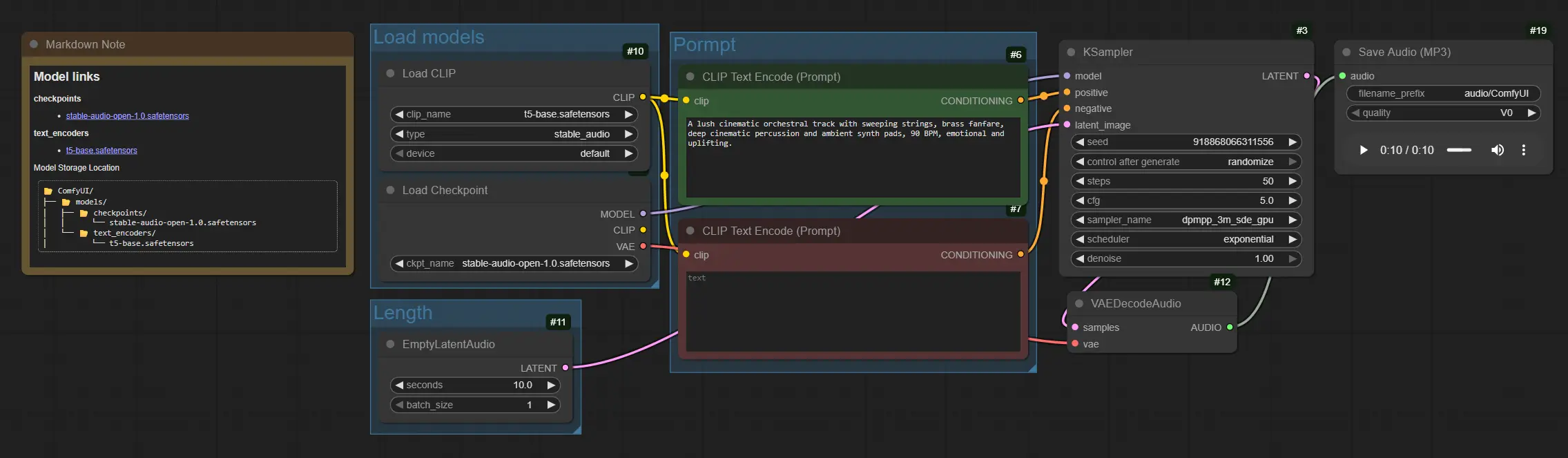
The graph flows from model loading to prompt conditioning, then sampling, decoding, and saving. Groups are organized so you can set models once, adjust length, write your prompt, and render.
Load models#
This group initializes the core assets. CheckpointLoaderSimple (#4) loads the Stable Audio Open 1.0 checkpoint, which includes the diffusion model and its audio VAE. CLIPLoader (#10) loads the T5-based text encoder used for conditioning. Once loaded, these models provide the backbone for Stable Audio generation and stay resident for subsequent runs.
Length#
This group defines how long your audio will be. EmptyLatentAudio (#11) creates a blank latent track with your chosen duration so the sampler knows how many frames to generate. Longer clips consume more time and memory, so start modestly, then scale. You can also produce multiple variations by increasing the batch dimension when exploring ideas.
Prompt#
This group turns text into the guidance signals for the diffusion process. Use CLIPTextEncode (#6) to write a positive prompt with instruments, genre, mood, tempo, and production cues, for example: “lush cinematic orchestra, sweeping strings and brass, deep percussion, ambient pads, 90 BPM, uplifting.” Use CLIPTextEncode (#7) for a negative prompt to suppress artifacts such as “harsh noise, clipping, distortion.” Together they steer Stable Audio toward the textures and structures you want.
Generate and export#
KSampler (#3) performs the diffusion steps that transform the empty latent into a musical latent guided by your text encodings. VAEDecodeAudio (#12) converts the latent audio back to a waveform. Finally, SaveAudioMP3 (#19) writes an MP3 file so you can review or drop it directly into your timeline. For iterative work, adjust the filename prefix to keep takes organized.
Key nodes in Comfyui Stable Audio workflow#
CLIPTextEncode(#6) This node encodes your positive prompt into conditioning that Stable Audio follows. Prioritize clear instrument lists, genre, mood, tempo or BPM, and production terms like “warm,” “lo-fi,” “cinematic,” or “ambient.” Subtle wording changes can meaningfully shift the composition. See ComfyUI core nodes for general behavior. ComfyUICLIPTextEncode(#7) The negative prompt helps avoid unwanted timbres or mix issues. Add terms that describe what to remove, for example “screechy, metallic ringing, glitch pops, radio hiss.” Keeping this concise often yields cleaner Stable Audio renders. ComfyUIEmptyLatentAudio(#11) Controls the clip duration in seconds and optionally the batch count for multiple variations. Increase seconds for longer pieces, noting that computation scales with length. Use batch generation to audition several Stable Audio takes from a single prompt. ComfyUIKSampler(#3) Drives the diffusion process for audio latents. The most influential controls aresteps,sampler,cfg, andseed. Raisestepsfor more refined detail, adjustcfgto balance prompt adherence with creativity, and set a fixedseedto reproduce a take or vary it for new ideas. Refer to ComfyUI’s sampler notes for general guidance. ComfyUISaveAudioMP3(#19) Exports the final waveform to an MP3. Use thefilename_prefixto label versions and keep iterations tidy. When comparing prompts or seeds, saving multiple takes side by side makes Stable Audio selection faster. ComfyUI
Optional extras#
- Write prompts like a session brief: instruments, genre, mood, tempo or BPM, and mix adjectives.
- Use short, focused negative prompts to reduce hiss, harshness, or unwanted instruments.
- Lock
seedwhile iterating text, then changeseedto explore new Stable Audio variations. - Start with shorter durations to dial in style, then lengthen once the sound is right.
- Keep a consistent filename prefix per concept so you can A/B Stable Audio takes later.
Resources for deeper reading: Stable Audio model details and examples here, ComfyUI core and node behavior here, and the T5-Base model card here.
Acknowledgements#
This workflow implements and builds upon the following works and resources. We gratefully acknowledge Stability AI for Stable Audio Open, comfyanonymous (ComfyUI) for the ComfyUI nodes and workflow references, and Comfy-Org and ComfyUI-Wiki for the Stable Audio Open 1.0 checkpoint and T5-Base text encoder for their contributions and maintenance. For authoritative details, please refer to the original documentation and repositories linked below.
Resources#
- Comfy-Org/Stable Audio Open 1.0 workflow
- GitHub: Stability-AI/stable-audio-open
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.
