
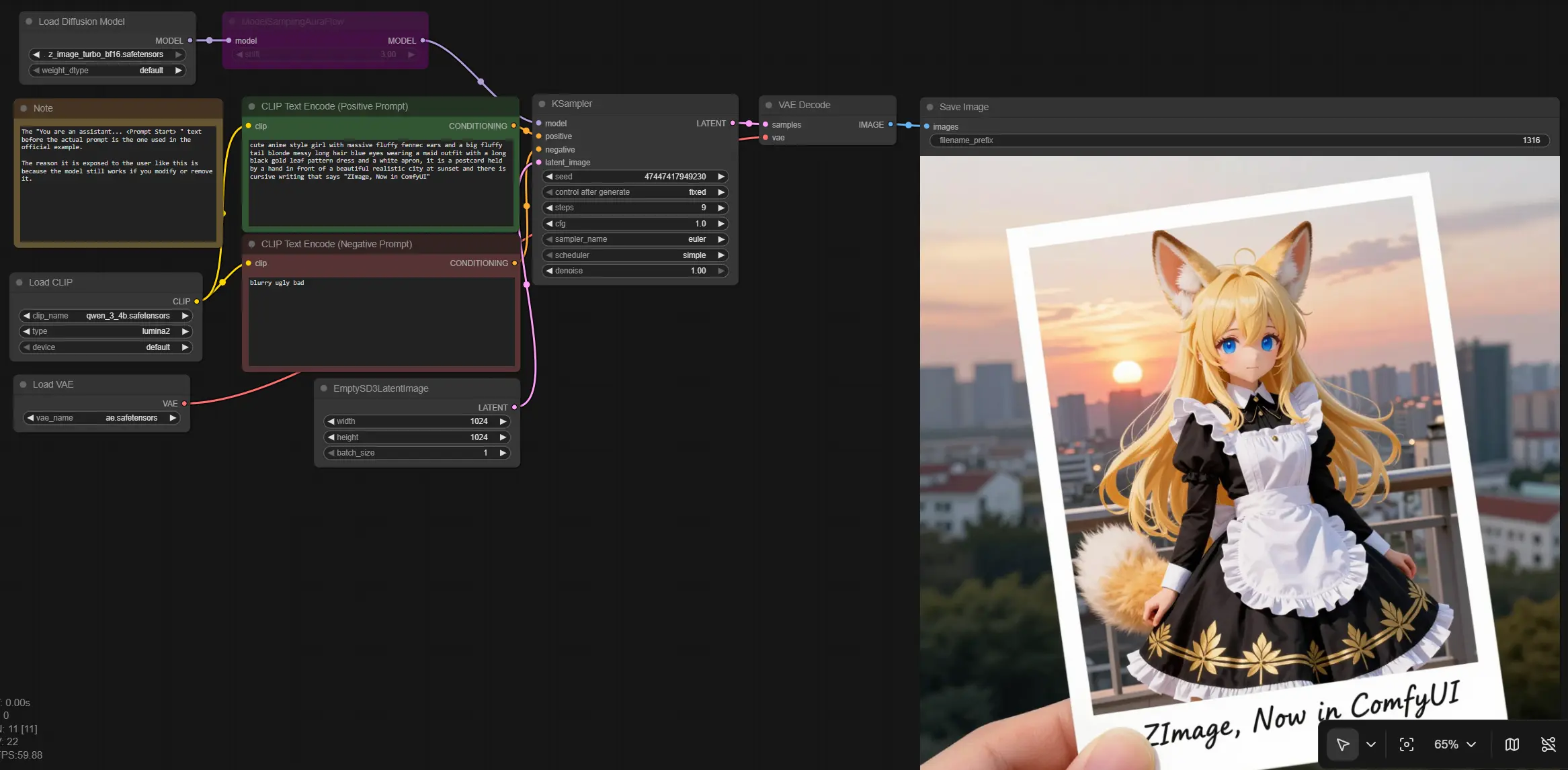







ComfyUI用Z Image Turbo: ほぼリアルタイムの反復による高速テキストからイメージ生成#
このワークフローは、Z Image TurboをComfyUIに導入し、わずかなステップで高解像度でフォトリアリスティックなビジュアルを生成し、厳密なプロンプト遵守が可能です。コンセプトアート、広告コンプ、インタラクティブメディア、迅速なA/Bテストのために迅速で一貫したレンダリングが必要なクリエイター向けに設計されています。
グラフは、テキストプロンプトからイメージへのクリーンなパスを辿ります: Z Imageモデルとサポートコンポーネントをロードし、ポジティブおよびネガティブプロンプトをエンコードし、潜在キャンバスを作成し、AuraFlowスケジュールでサンプリングし、RGBにデコードして保存します。その結果、ディテールを犠牲にせずにスピードを重視する効率的なZ Imageパイプラインが得られます。
Comfyui Z Imageワークフローの主要モデル#
- Tongyi-MAI Z Image Turbo。ノイズ除去を効率的なステップで行う主要なジェネレーターです。フォトリアリズム、シャープなテクスチャ、忠実な構成を目指しながら、遅延を低く抑えます。 Model card
- Qwen 4Bテキストエンコーダー (qwen_3_4b.safetensors)。モデルに言語条件を提供し、プロンプト内のスタイル、主題、構成がノイズ除去の軌跡を導くようにします。
- Autoencoder AE (ae.safetensors)。潜在空間とピクセルの間を変換し、最終的なZ Image結果を表示およびエクスポートできるようにします。
Comfyui Z Imageワークフローの使い方#
高レベルでは、プロンプトから条件付け、Z Imageサンプリング、イメージへのデコードまでのパスを走ります。ノードは操作を簡単に保つためにステージごとにクラスター化されています。
モデルローダー: UNETLoader (#16), CLIPLoader (#18), VAELoader (#17)#
このステージでは、コアZ Image Turboチェックポイント、テキストエンコーダー、およびオートエンコーダーをロードします。BF16チェックポイントがある場合はそれを選択すると、消費者向けGPUにおいて速度と品質のバランスが取れます。CLIPスタイルのエンコーダーは、シーンとスタイルを制御するためにあなたの言葉を保証します。AEは、サンプリングが終了した後に潜在を再びRGBに変換するために必要です。
プロンプティング: CLIP Text Encode (Positive Prompt) (#6) および CLIP Text Encode (Negative Prompt) (#7)#
具体的な名詞、スタイルの手がかり、カメラのヒント、ライティングを使用して、ポジティブプロンプトであなたの望むものを書きます。ネガティブプロンプトを使用して、ぼやけや不要なオブジェクトなどの一般的なアーティファクトを抑制します。公式の例からの指示ヘッダーのようなプロンプトの前置きが見られる場合、それを保持、編集、または削除してもワークフローは動作します。これらのエンコーダーは一緒に、サンプリング中にZ Imageを導く条件付けを生成します。
潜在とスケジューラー: EmptySD3LatentImage (#13) および ModelSamplingAuraFlow (#11)#
潜在キャンバスを設定して出力サイズを選択します。スケジューラーノードは、モデルをステップ効率の良い蒸留モデルと一致するAuraFlowスタイルのサンプリング戦略に切り替えます。これにより、低ステップ数でも軌跡が安定し、細部が保たれます。キャンバスとスケジュールが設定されると、パイプラインはノイズ除去の準備が整います。
サンプリング: KSampler (#3)#
このノードは、読み込まれたZ Imageモデル、選択されたスケジューラー、およびあなたのプロンプト条件付けを使用して実際のノイズ除去を行います。必要に応じて、速度とディテールをトレードオフするためにサンプラータイプとステップ数を調整します。ガイダンススケールは、プロンプトの強さを以前のものと比較して制御します。中程度の値が通常、忠実度と創造的な変化のバランスを最もよく与えます。探索のためにシードをランダム化するか、繰り返し可能な結果のために固定します。
デコードと保存: VAEDecode (#8) および SaveImage (#9)#
サンプリング後、AEは潜在をイメージにデコードします。保存ノードは、ファイルを出力ディレクトリに書き込み、反復を比較したり、下流のタスクに結果をフィードしたりできるようにします。アップスケールや後処理を計画している場合、希望する作業解像度でデコードを維持し、最高の品質保持のためにロスレスフォーマットをエクスポートします。
Comfyui Z Imageワークフローの主要ノード#
UNETLoader (#16)#
Z Image Turboチェックポイント (z_image_turbo_bf16.safetensors) をロードします。これを使用して、精度のバリエーションや更新されたウェイトに切り替えることができます。セッション中にモデルを一貫させると、シードとプロンプトが比較可能なままになります。ベースモデルを変更すると、外観、色の応答、ディテールの密度が変わります。
ModelSamplingAuraFlow (#11)#
高速収束に適したAuraFlowスタイルのスケジュールにサンプリング戦略を設定します。これは、Z Imageを低いステップ数で効率的にしながら、ディテールと一貫性を保つための鍵です。後でスケジュールを切り替える場合は、出力特性を維持するためにステップ数とガイダンスを再確認してください。
KSampler (#3)#
サンプラーアルゴリズム、ステップ、ガイダンス、およびシードを制御します。ラピッドなアイデーションのためにステップを少なくし、より多くのマイクロディテールまたは厳格なプロンプト遵守が必要な場合のみ増やします。異なるサンプラーは異なる外観を好みます; 結果を比較する際には、他のパイプラインを固定したままいくつか試してみてください。
CLIP Text Encode (Positive Prompt) (#6)#
Z Imageを駆動する創造的意図をエンコードします。対象、媒体、レンズ、ライティング、構成、およびブランドまたはデザイン制約に焦点を当てます。ネガティブプロンプトノードとペアを組んで、既知のアーティファクトをフィルタリングしながら、目標とする外観に向けてイメージを押し進めます。
オプションの追加機能#
- 最初のパスでは正方形またはほぼ正方形の解像度を使用し、構成が固定されたらアスペクト比を調整します。
- プロジェクト全体での反復をスピードアップするために、被写体、レンズ、およびライティングの再利用可能なプロンプトフラグメントのライブラリを保持します。
- 一貫したアートディレクションのために、シードを固定し、スタイルタグやカメラの手がかりなど、1回の反復ごとに単一の要因のみを変更します。
- 出力が過度に制御されていると感じた場合、ガイダンスをわずかに減らすか、ポジティブプロンプトから過度に指示的なフレーズを削除します。
- 下流編集のためのアセットを準備する際には、ロスレスPNGをエクスポートし、各Z Imageレンダーと共にプロンプト、シード、解像度の記録を保持します。
謝辞#
このワークフローは、次の作品やリソースを実装および構築しています。私たちは、彼らの貢献とメンテナンスに感謝し、権威ある詳細については、以下にリンクされた元のドキュメントとリポジトリを参照してください。
リソース#
- Tongyi-MAI/Z-Image-Turbo
- Hugging Face: Tongyi-MAI/Z-Image-Turbo
注: 参照されたモデル、データセット、およびコードの使用は、それらの著者およびメンテナーによって提供されるそれぞれのライセンスおよび条件に従います。