
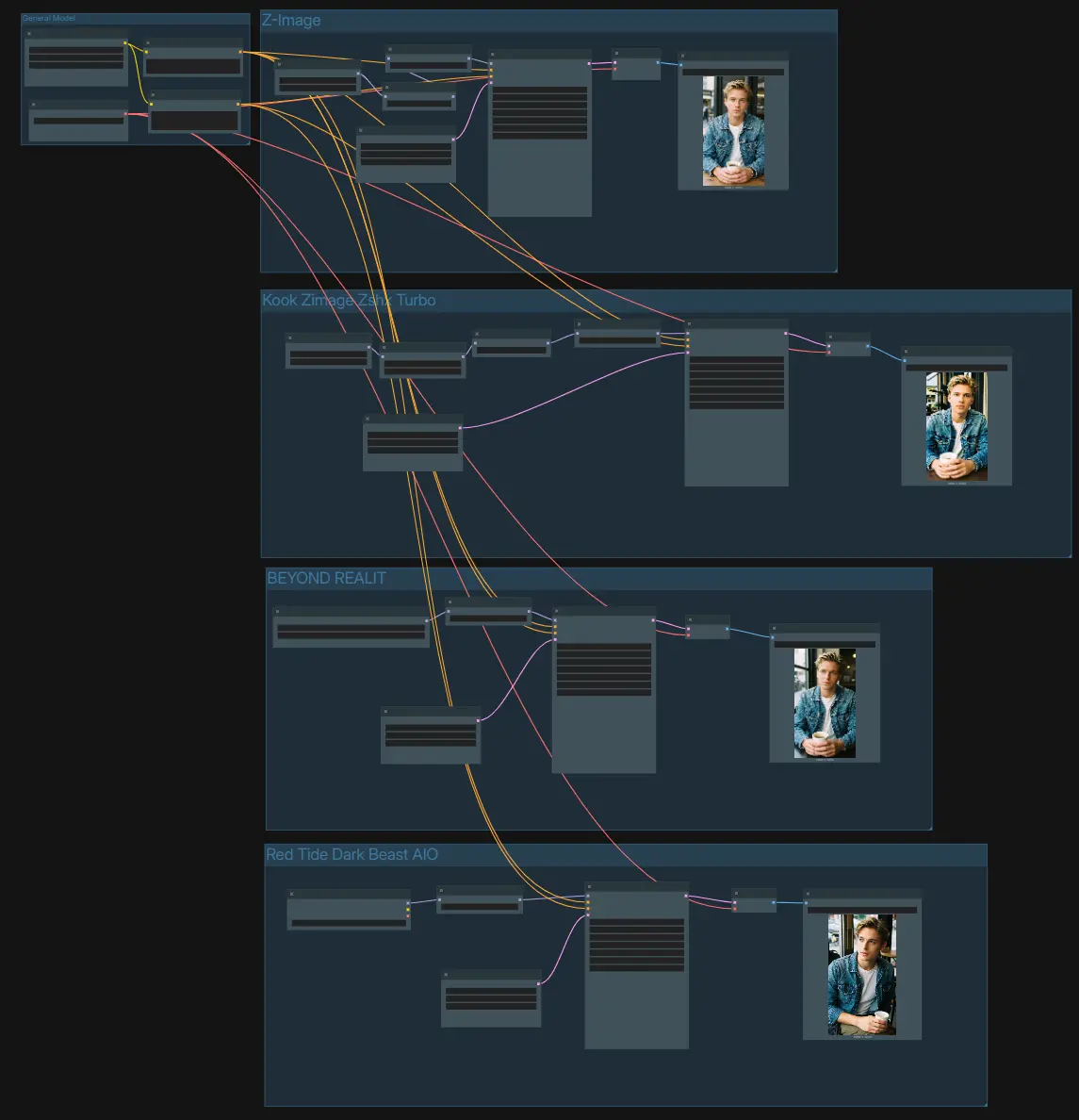





Z-Imageファインチューニングモデル: ComfyUIにおけるマルチスタイル、高品質画像生成#
このワークフローは、Z-Image-Turboと回転セットのZ-Imageファインチューニングモデルを単一の、プロダクションレディのComfyUIグラフに組み合わせています。スタイルを並べて比較し、プロンプトの動作を一貫させ、最小限のステップでシャープで一貫性のある結果を生成するよう設計されています。内部では、最適化されたUNetローディング、CFG正規化、AuraFlow互換のサンプリング、オプションのLoRA注入を組み合わせており、リアリズム、映画的ポートレート、ダークファンタジー、アニメ風のルックをキャンバスを再配線することなく探索できます。
Z-Imageファインチューニングモデルは、複数のチェックポイントとLoRAを評価しながら、一貫したパイプライン内に留まりたいアーティスト、プロンプトエンジニア、モデル探検者に最適です。1つのプロンプトを入力し、異なるZ-Imageファインチューンから4つのバリエーションをレンダリングし、あなたの要件に最も合ったスタイルをすばやく確定できます。
ComfyUI Z-Imageファインチューニングモデルワークフローの主要モデル#
- Tongyi-MAI Z-Image-Turbo。6Bパラメーターのシングルストリーム拡散トランスフォーマーで、少ステップ、フォトリアルなテキストから画像への変換を強力な指示遵守とバイリンガルテキストレンダリングで蒸留。公式の重みと使用ノートはモデルカードにあり、技術報告と蒸留方法はarXivおよびプロジェクトリポジトリに詳述されています。 Model • Paper • Decoupled-DMD • DMDR • GitHub • Diffusers pipeline
- BEYOND REALITY Z-Image (community finetune)。光沢のあるテクスチャ、シャープなエッジ、スタイライズされた仕上げを強調するフォトリアリスティックな傾向のZ-Imageチェックポイントで、ポートレートや製品のような構成に適しています。 Model
- Z-Image-Turbo-Realism LoRA (example LoRA used in this workflow’s LoRA lane)。ベースのZ-Image-Turboプロンプトの整合性を維持しつつ、超リアルなレンダリングを推進する軽量アダプター。ベースモデルを置き換えることなくロード可能。 Model
- AuraFlow family (sampling-compatible reference)。ワークフローは安定した少ステップ生成のためにAuraFlowスタイルのサンプリングフックを使用します。AuraFlowスケジューラーの設計目標についてはパイプラインのリファレンスを参照してください。 Docs
ComfyUI Z-Imageファインチューニングモデルワークフローの使用方法#
グラフは共通のテキストエンコーダーとVAEを共有する4つの独立した生成レーンに編成されています。1つのプロンプトを使用してすべてのレーンを駆動し、各ブランチから保存された結果を比較します。
- General Model
- 共有セットアップはテキストエンコーダーとVAEをロードします。正の
CLIPTextEncode(#75)に説明を入力し、負のCLIPTextEncode(#74)にオプションの制約を追加します。これにより、各ブランチの条件付けが同一に保たれ、各ファインチューンがどのように振る舞うかを公平に判断できます。VAELoader(#21)は、すべてのレーンが潜在を画像に戻すために使用するデコーダーを提供します。
- 共有セットアップはテキストエンコーダーとVAEをロードします。正の
- Z-Image (Base Turbo)
- このレーンは
UNETLoader(#100)を介して公式のZ-Image-Turbo UNetを実行し、ModelSamplingAuraFlow(#76)で少ステップの安定性をパッチします。CFGNorm(#67)は、プロンプト間でサンプラーのコントラストとディテールが予測可能であるように、分類器フリーガイダンスの動作を標準化します。EmptyLatentImage(#19)がキャンバスサイズを定義し、KSampler(#78)が潜在を生成し、VAEDecode(#79)がデコードし、SaveImage(#102)が書き込みます。他のZ-Imageファインチューニングモデルを評価する際のベースラインとしてこのブランチを使用します。
- このレーンは
- Z-Image-Turbo + Realism LoRA
- このレーンは、ベースの
UNETLoader(#82)の上にLoraLoaderModelOnly(#106)を使用してスタイルアダプターを注入します。ModelSamplingAuraFlow(#84)とCFGNorm(#64)が出力をシャープに保ちながら、LoRAがリアリズムを推進しつつ主題を圧倒しません。EmptyLatentImage(#71)で解像度を定義し、KSampler(#85)で生成し、VAEDecode(#86)でデコードし、SaveImage(#103)で保存します。LoRAが強すぎると感じた場合は、プロンプトを過度に編集するのではなく、ここでその重みを減らします。
- このレーンは、ベースの
- BEYOND REALITY finetune
- このパスは
UNETLoader(#88)を使用してコミュニティチェックポイントを入れ替え、スタイライズされた高コントラストのルックを提供します。CFGNorm(#66)はガイダンスを調整し、サンプラーやステップを変更したときにビジュアルシグネチャがクリーンに保たれるようにします。EmptyLatentImage(#72)でターゲットサイズを設定し、KSampler(#89)でレンダリングし、VAEDecode(#90)でデコードし、SaveImage(#104)で保存します。ベースレーンと同じプロンプトを使用して、このファインチューンが構図とライティングをどのように解釈するかを確認します。
- このパスは
- Red Tide Dark Beast AIO finetune
- ダークファンタジー指向のチェックポイントは
CheckpointLoaderSimple(#92)でロードされ、CFGNorm(#65)で正規化されます。このレーンはムーディーなカラーパレットと重いマイクロコントラストに寄りかかりながら、良好なプロンプト準拠を維持します。EmptyLatentImage(#73)でフレームを選択し、KSampler(#93)で生成し、VAEDecode(#94)でデコードし、SaveImage(#105)からエクスポートします。Z-Imageファインチューニングモデルセットアップ内でよりグリティな美学をテストする実用的な方法です。
- ダークファンタジー指向のチェックポイントは
ComfyUI Z-Imageファインチューニングモデルワークフローの主要ノード#
ModelSamplingAuraFlow(#76, #84)- 目的: 非常に低いステップ数で安定しているAuraFlow互換のサンプリングパスを使用するようにモデルをパッチします。
shiftコントロールはサンプリングの軌道を微調整します。サンプラーの選択やステップ予算と相互作用する微調整ダイヤルとして扱います。レーン間での最良の比較可能性のために、同じサンプラーを保持し、テストごとに1つの変数(例:shiftまたはLoRAウェイト)のみを調整します。参照: AuraFlowパイプラインの背景とスケジューリングノート。 Docs
- 目的: 非常に低いステップ数で安定しているAuraFlow互換のサンプリングパスを使用するようにモデルをパッチします。
CFGNorm(#64, #65, #66, #67)- 目的: モデル、ステップ、またはスケジューラーを変更した際に、コントラストとディテールが大きく変動しないように分類器フリーガイダンスを正規化します。ハイライトが洗い流されたり、テクスチャがレーン間で一貫しない場合は、その
strengthを増やします。画像が過度に圧縮されて見える場合は、その値を減らします。Z-ImageファインチューニングモデルのクリーンなA/Bを希望する場合は、ブランチ間でそれを同様に保ちます。
- 目的: モデル、ステップ、またはスケジューラーを変更した際に、コントラストとディテールが大きく変動しないように分類器フリーガイダンスを正規化します。ハイライトが洗い流されたり、テクスチャがレーン間で一貫しない場合は、その
LoraLoaderModelOnly(#106)- 目的: ベースチェックポイントを変更せずにロードされたUNetに直接LoRAアダプターを注入します。
strengthパラメーターはスタイリスティックな影響を制御します。低い値はベースのリアリズムを維持し、高い値はLoRAのルックを課します。LoRAが顔やタイポグラフィを圧倒する場合は、まずその重みを減らし、次にプロンプトの表現を微調整します。
- 目的: ベースチェックポイントを変更せずにロードされたUNetに直接LoRAアダプターを注入します。
KSampler(#78, #85, #89, #93)- 目的: 実際の拡散ループを実行します。少ステップ蒸留に適したサンプラーとスケジューラーを選択します。多くのユーザーはTurboクラスのモデルに対してEulerスタイルのサンプラーを均一またはマルチステップスケジューラーと組み合わせることを好みます。種子を固定してレーンを比較し、各ファインチューンがどのように振る舞うかを理解するために1つの変数のみを変更します。
オプションの付加機能#
- 1つの説明的な段落スタイルのプロンプトで開始し、それをすべてのレーンで再利用してZ-Imageファインチューニングモデル間の違いを判断します。お気に入りのブランチを選んだ後にのみスタイルワードを繰り返します。
- Turboクラスのモデルには、非常に低いまたはゼロのCFGが最もクリーンな結果をもたらすことがよくあります。特定の要素を除外する必要がある場合にのみ負のプロンプトを使用します。
- A/Bテストを行う際には、同じ解像度、サンプラー、種子を維持し、LoRAの重みや
shiftを小刻みに変更して原因と効果を隔離します。 - 各ブランチは独自の出力を書き込みます。4つの
SaveImageノードはユニークにラベル付けされているため、迅速に比較およびキュレーションできます。
詳細な読み物のリンク:
- Z-Image-Turboモデルカード: Tongyi-MAI/Z-Image-Turbo
- 技術報告と方法: Z-Image • Decoupled-DMD • DMDR
- プロジェクトリポジトリ: Tongyi-MAI/Z-Image
- 例のファインチューン: Nurburgring/BEYOND_REALITY_Z_IMAGE
- 例のLoRA: Z-Image-Turbo-Realism-LoRA
謝辞#
このワークフローは、以下の作品やリソースを実装し、それに基づいて構築されています。我々は、彼らの貢献と維持に感謝しています。権威ある詳細については、以下にリンクされた元のドキュメントとリポジトリを参照してください。
リソース#
- HuggingFaceモデル:
注: 参照されたモデル、データセット、およびコードの使用は、それぞれの著者および保守者によって提供されるライセンスおよび条件に従います。


