
Wan2.1 Stand In: ComfyUIのための単一画像、キャラクター一貫性のあるビデオ生成#
このワークフローは、1枚の参照画像を短いビデオに変換し、同じ顔とスタイルがフレーム全体で持続します。Wan 2.1ファミリーと目的に合ったStand In LoRAによって動力を供給され、安定したアイデンティティが最小限のセットアップで必要な物語の語り手、アニメーター、アバタークリエイター向けに設計されています。Wan2.1 Stand Inパイプラインは、背景のクリーンアップ、クロッピング、マスキング、埋め込みを処理するため、プロンプトと動きに集中できます。
単一の写真から信頼できるアイデンティティの継続性、迅速なイテレーション、エクスポート準備が整ったMP4、さらにオプションのサイドバイサイド比較出力を望むときに、Wan2.1 Stand Inワークフローを使用してください。
Comfyui Wan2.1 Stand Inワークフローの主要モデル#
- Wan 2.1 Text‑to‑Video 14B。時間的な一貫性と動きの主な生成を担当します。480pと720pの生成をサポートし、ターゲットとなる行動やスタイルのためにLoRAsと統合します。Model card
- Wan‑VAE for Wan 2.1。モーションキューを保持しながらビデオの潜在をエンコードおよびデコードする高効率の時空間VAEです。このワークフローの画像エンコード/デコード段階を支えます。Wan 2.1モデルリソースとDiffusers統合ノートを参照してVAEの使用法を確認してください。Model hub • Diffusers docs
- Stand In LoRA for Wan 2.1。単一の画像からアイデンティティをロックするようにトレーニングされたキャラクター一貫性アダプターです。このグラフでは、モデルロード時に適用され、アイデンティティ信号が基盤に融合されることを保証します。Files
- LightX2V Step‑Distill LoRA (オプション)。Wan 2.1 14Bのガイダンス行動と効率を向上させる軽量アダプターです。Model card
- VACE module for Wan 2.1 (オプション)。ビデオ対応のコンディショニングを介してモーションと編集の制御を可能にします。ワークフローにはVACE制御を有効にするための埋め込みパスが含まれています。Model hub
- UMT5‑XXL text encoder。Wan 2.1テキストからビデオへの堅牢な多言語プロンプトエンコーディングを提供します。Model card
Comfyui Wan2.1 Stand Inワークフローの使用方法#
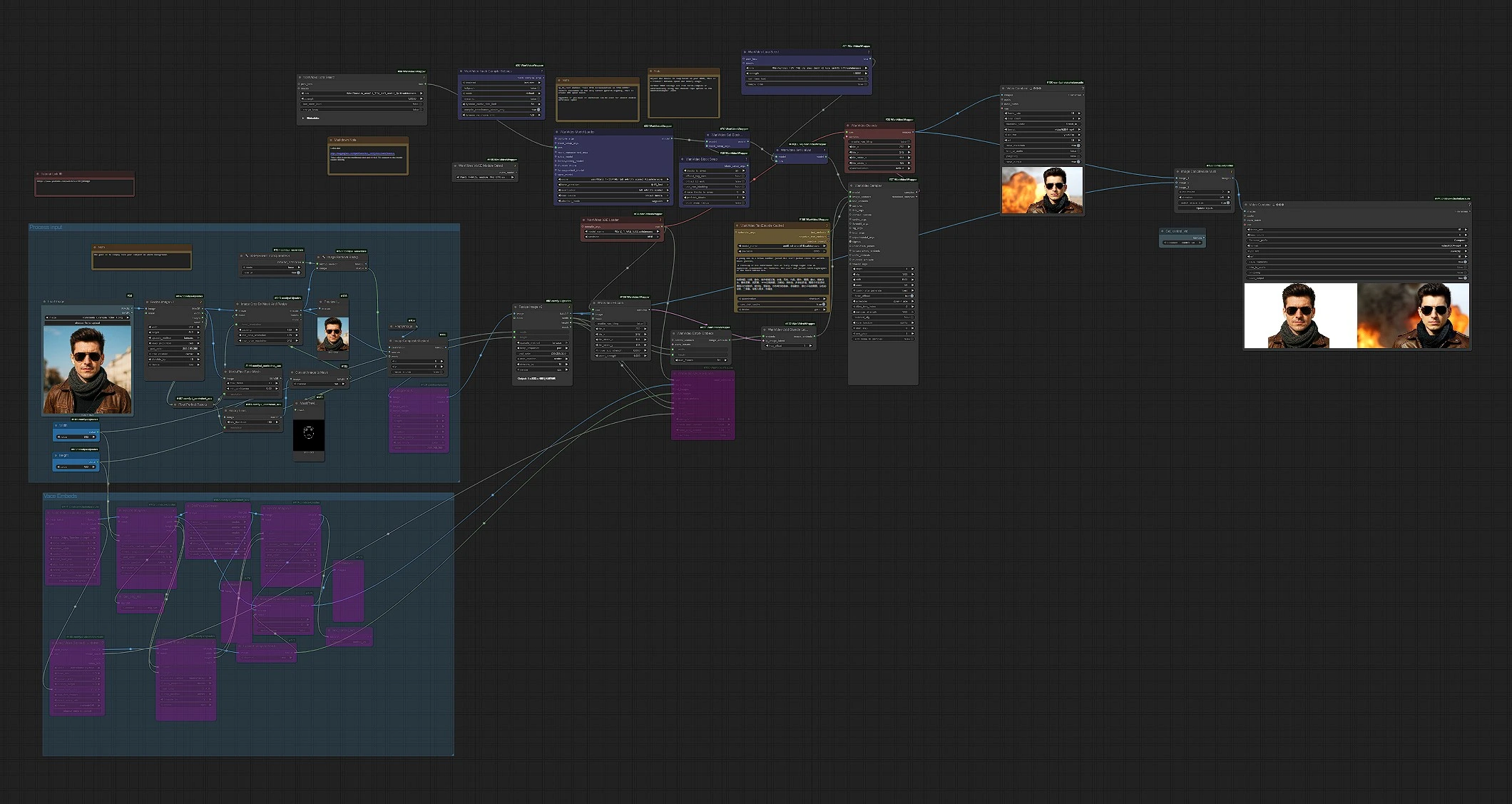
一目で:クリーンな正面向きの参照画像をロードし、ワークフローが顔に焦点を当てたマスクとコンポジットを準備し、潜在にエンコードし、そのアイデンティティをWan 2.1画像埋め込みにマージし、ビデオフレームをサンプリングしてMP4をエクスポートします。2つの出力が保存されます:メインレンダーとサイドバイサイド比較。
入力処理 (グループ)#
シンプルな背景に明るく照らされた前向きの画像から開始します。パイプラインはLoadImage (#58)で画像をロードし、ImageResizeKJv2 (#142)でサイズを標準化し、MediaPipe-FaceMeshPreprocessor (#144)とBinaryPreprocessor (#151)を使用して顔中心のマスクを作成します。背景はTransparentBGSession+ (#127)とImageRemoveBackground+ (#128)で削除され、被写体はImageCompositeMasked (#108)でクリーンなキャンバス上に合成され、色のブリーディングを最小限に抑えます。最後に、ImagePadKJ (#129)とImageResizeKJv2 (#68)で生成のためにアスペクトを整え、準備されたフレームはWanVideoEncode (#104)で潜在にエンコードされます。
VACE埋め込み (オプショングループ)#
既存のクリップからモーション制御を望む場合、VHS_LoadVideo (#161)でロードし、オプションでセカンダリガイドやアルファビデオをVHS_LoadVideo (#168)でロードします。フレームはDWPreprocessor (#163)でポーズキューを通過し、ImageResizeKJv2 (#169)で形状を一致させます;ImageToMask (#171)とImageCompositeMasked (#174)を使用して正確に制御イメージをブレンドできます。これらはVACE埋め込みに変換され、WanVideoVACEEncode (#160)により行われます。このパスはオプションです;Wan 2.1からのテキスト駆動のモーションを望むときにはそのままにしておきます。
モデル、LoRAs、およびテキスト#
WanVideoModelLoader (#22)がWan 2.1 14BベースとStand In LoRAをロードし、アイデンティティが最初から焼き込まれます。VRAMに優しいスピード機能はWanVideoBlockSwap (#39)で利用可能で、WanVideoSetBlockSwap (#70)で適用されます。LightX2Vのような追加のアダプターをWanVideoSetLoRAs (#79)で接続できます。プロンプトはWanVideoTextEncodeCached (#159)でエンコードされ、UMT5‑XXLが内部で多言語制御を提供します。プロンプトは簡潔で記述的に保ち、被写体の服装、角度、照明を強調してStand Inのアイデンティティを補完します。
アイデンティティ埋め込みとサンプリング#
WanVideoEmptyEmbeds (#177)が画像埋め込みのターゲット形状を確立し、WanVideoAddStandInLatent (#102)がエンコードされた参照潜在を注入し、アイデンティティを時間を通じて運びます。結合された画像とテキストの埋め込みはWanVideoSampler (#27)にフィードされ、設定されたスケジューラーとステップを使用して潜在ビデオシーケンスを生成します。サンプリング後、フレームはWanVideoDecode (#28)でデコードされ、VHS_VideoCombine (#180)でMP4に書き込まれます。
比較ビューとエクスポート#
即時QAのために、ImageConcatMulti (#122)は生成されたフレームをリサイズされた参照の横にスタックし、フレームごとに類似性を判断できます。VHS_VideoCombine (#74)はそれを別の"Compare" MP4として保存します。Wan2.1 Stand Inワークフローは、余分な労力なしでクリーンな最終ビデオとサイドバイサイドのチェックを生成します。
Comfyui Wan2.1 Stand Inワークフローの主要ノード#
WanVideoModelLoader(#22)。Wan 2.1 14Bをロードし、モデル初期化時にStand In LoRAを適用します。アイデンティティがデノイズパス全体で強制されるように、Stand Inアダプターをここに接続しておきます。対応するWan‑VAEのためにWanVideoVAELoader(#38)とペアにします。WanVideoAddStandInLatent(#102)。エンコードされた参照画像潜在を画像埋め込みに融合します。アイデンティティが漂流する場合はその影響を増やし、モーションが過度に制約されているように見える場合はそれを少し減らします。WanVideoSampler(#27)。主要な生成器。ステップの調整、スケジューラーの選択、およびガイダンス戦略は、ディテール、モーションの豊かさ、時間的安定性に最大の影響を与えます。解像度や長さを押し上げるときには、上流の変更を行う前にサンプラー設定を調整することを検討してください。WanVideoSetBlockSwap(#70)とWanVideoBlockSwap(#39)。デバイス間で注意ブロックを交換することでGPUメモリを速度に交換します。メモリエラーが発生した場合はオフローディングを増やし、余裕がある場合はオフローディングを減らして迅速なイテレーションを行います。ImageRemoveBackground+(#128)とImageCompositeMasked(#108)。これらは、被写体がクリーンに孤立され、中立的なキャンバスに配置されることを保証し、色の汚染を減らし、フレーム全体でのStand Inのアイデンティティロックを改善します。VHS_VideoCombine(#180)。メインMP4出力のエンコーディング、フレームレート、およびファイル命名を制御します。配信のために好みのFPSと品質目標を設定するために使用します。
オプションの追加#
- ベストな結果を得るために、単純な背景で前向きで均一に照らされた参照を使用してください。小さな回転や重度の遮蔽はアイデンティティ転送を弱める可能性があります。
- プロンプトを簡潔に保ち、参照に一致する服装、ムード、および照明を記述してください。Wan2.1 Stand In信号と対立する顔の記述を避けてください。
- VRAMが不足している場合は、ブロックスワッピングを増やすか、解像度を下げてください。余裕がある場合は、ローダースタックでコンパイル最適化を有効にしてからステップを増やしてみてください。
- Stand In LoRAは非標準であり、モデルロード時に接続する必要があります;このグラフのパターンに従ってアイデンティティを安定させてください。LoRAファイル:Stand‑In
- 高度な制御のために、ガイドクリップでモーションを操縦するためにVACEパスを有効にします。Wan 2.1からの純粋なテキスト駆動の動きを望む場合は、まずそれを使用せずに始めてください。
リソース
- Wan 2.1 14B T2V: Hugging Face
- Wan 2.1 VACE: Hugging Face
- Stand In LoRA: Hugging Face
- LightX2V Step‑Distill LoRA: Hugging Face
- UMT5‑XXLエンコーダー: Hugging Face
- WanVideoラッパーノード: GitHub
- リサイズ、パディング、およびマスキングに使用されるKJNodesユーティリティ: GitHub
- ControlNet Auxプリプロセッサ(MediaPipe Face Mesh, DWPose): GitHub
謝辞#
このワークフローは、ArtOfficial Labsの作品とリソースを実装し、構築しています。ArtOfficial LabsとWan 2.1の著者に感謝の意を表します。Wan2.1 Demoの貢献とメンテナンスに感謝します。権威ある詳細については、以下のリンクされた元のドキュメントとリポジトリを参照してください。
リソース#
- Wan 2.1/Wan2.1 Demo
- ドキュメント / リリースノート: Wan2.1 Demo
注:参照されたモデル、データセット、およびコードの使用は、それぞれの著者およびメンテナーによって提供されたライセンスおよび条件に従う必要があります。

