






Qwen Image 2512 ComfyUIワークフロー:テキストに忠実な肖像画とシーン#
このワークフローは、Qwen Image 2512を使用してプロンプトを高忠実度の画像に変換します。強力なテキストから画像への整合性、リアルな人物、シーン内での信頼性のあるバイリンガルテキストレンダリングが必要なクリエイター向けに設計されています。グラフにはQwenのVAEとテキストエンコーダー、さらにオプションのLightning LoRAが予め接続されており、最小限のセットアップでプロンプトから結果に移行できます。
コンセプトアート、イラストレーション、看板、ポスター、日常的な写真スタイルに使用してください。Qwen Image 2512は安定した構成と鮮明なタイポグラフィをもたらし、人々、環境、読みやすいテキストを混ぜたプロンプトに最適です。
Comfyui Qwen Image 2512ワークフローの主要モデル#
- Qwen-Image 2512ベースモデル (bfloat16)。調整から画像を合成するコア拡散モデル。Comfy-OrgパッケージでComfy対応の重みが提供されています。 モデルファイル
- Qwen2.5-VL 7Bテキストエンコーダー。プロンプトをQwen Image 2512のレイアウト、スタイル、テキストレンダリングを駆動する条件ベクトルにエンコードします。 テキストエンコーダーファイル
- Qwen Image VAE。サンプラーによって生成された潜在を忠実な色と詳細でRGB画像にデコードします。 VAEファイル
- Qwen-Image-2512-Lightning-4steps-V1.0 LoRA (オプション)。少ステップ生成用に調整されたコミュニティLoRAで、わずかな品質のトレードオフでレンダリングを加速します。 LoRAカード
- モデルファミリーとトレーニングアプローチの背景については、Qwen-Image技術報告書をご覧ください。 ペーパー
Comfyui Qwen Image 2512ワークフローの使用方法#
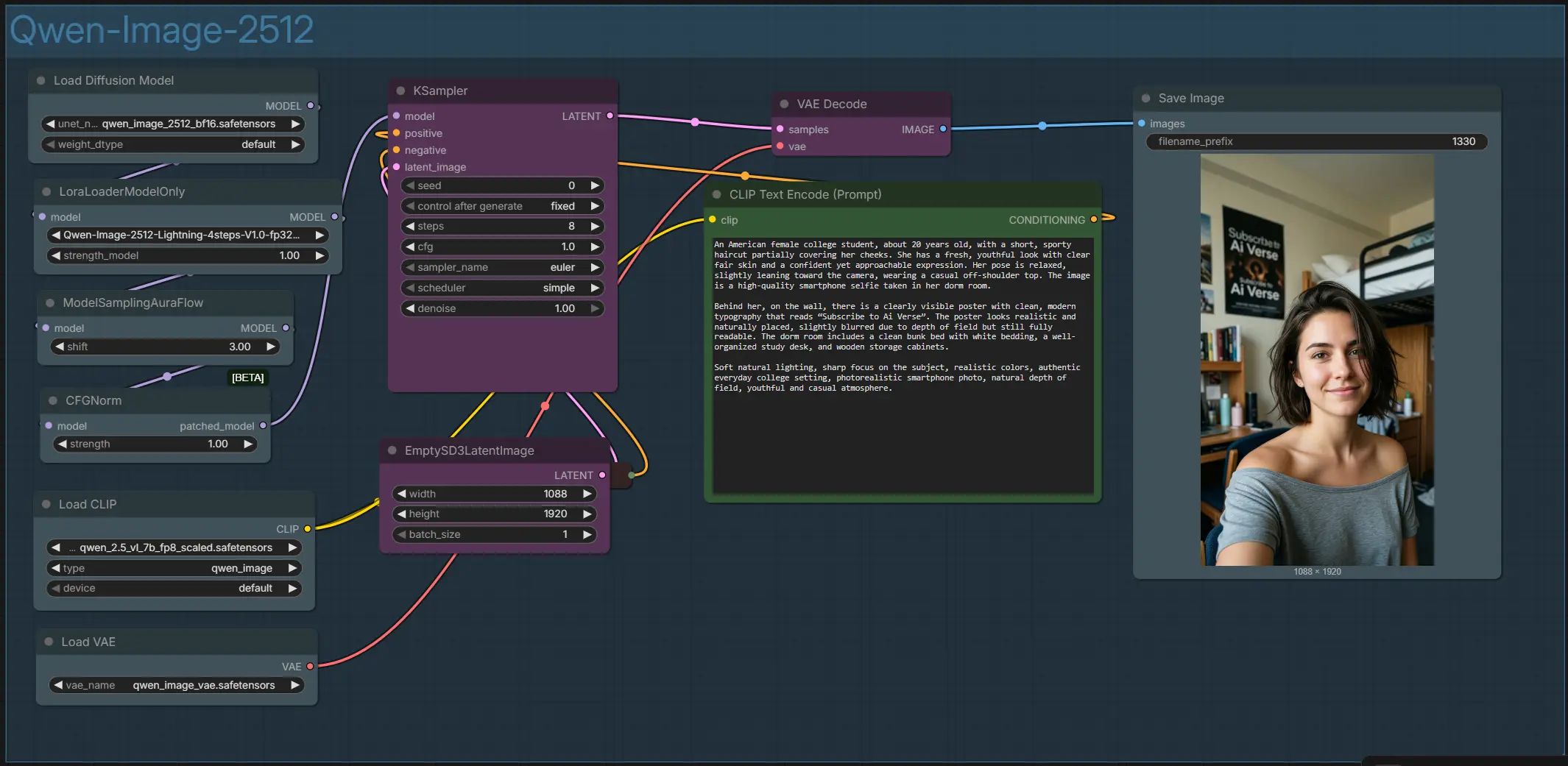
全体の流れ:プロンプトがエンコードされ、選択した解像度で潜在キャンバスが作成され、モデルスタックがベースモデルとオプションのLoRAを適用し、サンプラーが潜在を洗練し、VAEが最終画像をデコードして保存します。
- Qwen-Image-2512グループ概要
- グラフ全体は「Qwen-Image-2512」という単一のグループに編成されています。テキストエンコーダー、モデルとLoRAスタック、サンプリングヘルパー、VAEデコードを結び付けます。ポジティブおよびネガティブプロンプト、キャンバスサイズ、いくつかのサンプラー設定で外観を制御します。出力は高解像度のポートレートスタイルの画像で、ComfyUI出力フォルダに保存されます。
CLIPTextEncode(#52)とオプションのネガティブCLIPTextEncode(#32)CLIPTextEncode(#52)にメインの説明を入力します。シーン、被写体、およびレンダリングしたい画像内テキストを記述してください。Qwen Image 2512は特に看板、ポスター、UIモックアップ、バイリンガルキャプションに強いです。アーティファクトや不要なスタイルを避けるためにオプションのネガティブCLIPTextEncode(#32)を使用してください。正確な文言が必要な場合は、テキストスニペットを引用符で囲んでください。
EmptySD3LatentImage(#57)でキャンバスとアスペクト比を設定- ここで目標の幅と高さを選択して構成を設定します。ポートレートフォーマットは人物や自撮りに適しており、正方形や横長の比率は製品やシーンレイアウトに適しています。より大きなキャンバスはメモリと時間のコストで詳細を向上させます。フレーミングが気に入ったら、 modestに始めてからスケールアップしてください。一貫性は、繰り返しの中で同じアスペクト比を維持することで向上します。
UNETLoader(#100)とLoraLoaderModelOnly(#101)でモデルとLoRAスタックを設定- ベースジェネレータは
UNETLoader(#100)によってロードされるQwen Image 2512です。レンダリングを速くしたい場合は、LoraLoaderModelOnly(#101)でLightning LoRAを有効にして少ステップワークフローに切り替えます。このスタックは、リアリズム、レイアウト、およびテキストから画像への整合性のモデルの機能をサンプリングが始まる前に設定します。
- ベースジェネレータは
ModelSamplingAuraFlow(#43)とCFGNorm(#55)でサンプリングヘルパーを設定- これらの2つのノードは、安定したコントラストバランスのサンプリングのためにモデルを準備します。
ModelSamplingAuraFlow(#43)は、テクスチャを過度に調理することなく詳細をシャープに保つためにスケジュールを調整します。CFGNorm(#55)は、プロンプトに従って一貫した色と露出を維持するためにガイダンスを正規化します。
- これらの2つのノードは、安定したコントラストバランスのサンプリングのためにモデルを準備します。
KSampler(#54)でデノイズと洗練を行う- これはノイズから一貫した画像に潜在を繰り返し改善するワークホースステージです。再現性のためにシードを設定し、サンプラーとスケジューラーを選択し、実行するステップ数を選びます。Lightningが有効な場合は少ステップを目指し、ベースモデルのみの場合は最大の忠実度のためにより多くのステップを使用します。
VAEDecode(#45)とSaveImage(#117)でデコードと保存を行う- サンプリング後、VAEは潜在からRGBをきれいに再構築し、
SaveImageは最終PNGを書き込みます。色やコントラストがオフに見える場合は、ポストプロセッシングではなくガイダンスやプロンプトの表現を再検討してください。Qwen Image 2512は、説明的な照明や素材のヒントに良く反応します。
- サンプリング後、VAEは潜在からRGBをきれいに再構築し、
Comfyui Qwen Image 2512ワークフローの主要ノード#
UNETLoader(#100)- 全体的な能力とスタイル空間を決定するQwen-Image-2512ベースモデルをロードします。GPUが許可する場合はbf16ビルドを使用して最大品質を確保します。メモリをフィットさせるかスループットを増やす必要がある場合のみ、fp8または圧縮バリアントに切り替えてください。
LoraLoaderModelOnly(#101)- ベースモデルにQwen-Image-2512-Lightning-4steps-V1.0 LoRAを適用します。
strength_modelを上げたり下げたりして、速度調整とベースの忠実度をブレンドするか、0に設定して無効にします。このLoRAがアクティブな場合は、KSamplerのstepsを少ステップに減らしてスピードアップを実現してください。
- ベースモデルにQwen-Image-2512-Lightning-4steps-V1.0 LoRAを適用します。
ModelSamplingAuraFlow(#43)- モデルのサンプリング動作をフロースタイルのスケジュールにパッチし、シャープなエッジとスムージーの少ない結果をもたらします。結果が過度にシャープまたは詳細不足に見える場合は、
shiftパラメータをわずかに調整して再サンプリングしてください。他の変数を安定させてテストして効果を特定してください。
- モデルのサンプリング動作をフロースタイルのスケジュールにパッチし、シャープなエッジとスムージーの少ない結果をもたらします。結果が過度にシャープまたは詳細不足に見える場合は、
CFGNorm(#55)- クラシファイアフリーガイダンスを正規化して、色あせや過度に飽和した出力を防ぎます。
strengthを使用して、正規化がどの程度強く作用するかを決定します。テキストの精度が低下する場合は、CFGをさらに押し上げるのではなく、正規化の強度を増加させてください。
- クラシファイアフリーガイダンスを正規化して、色あせや過度に飽和した出力を防ぎます。
EmptySD3LatentImage(#57)- フレーミングとアスペクト比を定義する潜在キャンバスサイズを設定します。人の場合、ポートレート比率は歪みを減らし、体のプロポーションに役立ちます。ポスターの場合は、正方形や横長の比率がレイアウトとテキストブロックを強調します。構成に満足したら解像度を上げてください。
CLIPTextEncode(#52)とCLIPTextEncode(#32)- ポジティブエンコーダー (#52)は、シーンにレンダリングされる明示的なテキスト文字列を含む条件に説明を変換します。ネガティブエンコーダー (#32)は、アーティファクト、余分な指、ノイズのある背景などの不要な特性を抑制します。プロンプトを簡潔かつ事実に基づいたもので、一番良い整合性を得るためにしてください。
KSampler(#54)- シード、サンプラー、スケジューラー、ステップ、CFG、デノイズ強度を制御します。Qwen Image 2512を使用する場合、中程度のCFG値が通常、モデルの強力なテキスト整合性を維持します。文字が変形する場合は、サンプラーを変更する前にCFGを下げてください。迅速なドラフトにはLightningを有効にして非常に少ないステップを試し、必要に応じて最終レンダリングのためにステップを増やします。
VAELoader(#34)とVAEDecode(#45)- QwenのVAEをロードし、忠実な色と細部を再構築します。カラーシフトを避けるためにベースモデルとペアのVAEを維持します。ベースウェイトを切り替える場合は、対応するVAEビルドにも切り替えてください。
オプションの追加#
- 画像内テキストのプロンプト
- 正確な単語をストレート引用符で囲み、「クリーンモダンタイポグラフィ」や「ボールドサンセリフ」などの簡潔なタイポグラフィのヒントを追加してください。「壁ポスター」や「店頭看板」などの配置のヒントを含めてテキストが表示される場所を固定してください。
- Lightningを使用した高速な反復
- Lightning LoRAを有効にして少ステップを使用してプレビューを行います。フレーミングとワーディングが正しい場合、LoRAの強度を無効にするか減らし、ステップを増やして最大の忠実度を回復してください。
- アスペクト比の選択
- バリエーション全体で一貫した比率を維持してください。人の場合はポートレート、製品やロゴスタディの場合は正方形、環境やスライドの場合は横長を使用してください。後でアップスケールする場合は、構成を維持するために同じ比率を維持してください。
- ガイダンスの規律
- Qwen Image 2512は通常、控えめなCFGを好みます。テキストの忠実度が低下する場合は、CFGを下げるか、
CFGNormの強度を増加させてください。
- Qwen Image 2512は通常、控えめなCFGを好みます。テキストの忠実度が低下する場合は、CFGを下げるか、
- 再現性
- 結果が気に入った場合はシードを固定し、安全に反復してください。影響を理解するために、一度に1つの制御を変更してから次に進んでください。
謝辞#
このワークフローは、以下の作品とリソースを実装し、構築しています。Qwen Image 2512モデルファイルの寄稿とメンテナンスに対して、Comfy-Orgに心より感謝申し上げます。権威ある詳細については、以下にリンクされた元のドキュメントとリポジトリを参照してください。
リソース#
- Comfy-Org/Qwen Image 2512モデルファイル
- Hugging Face: Comfy-Org/Qwen-Image_ComfyUI
- ドキュメント / リリースノート: Qwen Image 2512モデルファイル
注:参照されたモデル、データセット、およびコードの使用は、それぞれの著者と管理者によって提供されたライセンスおよび条件に従います。