
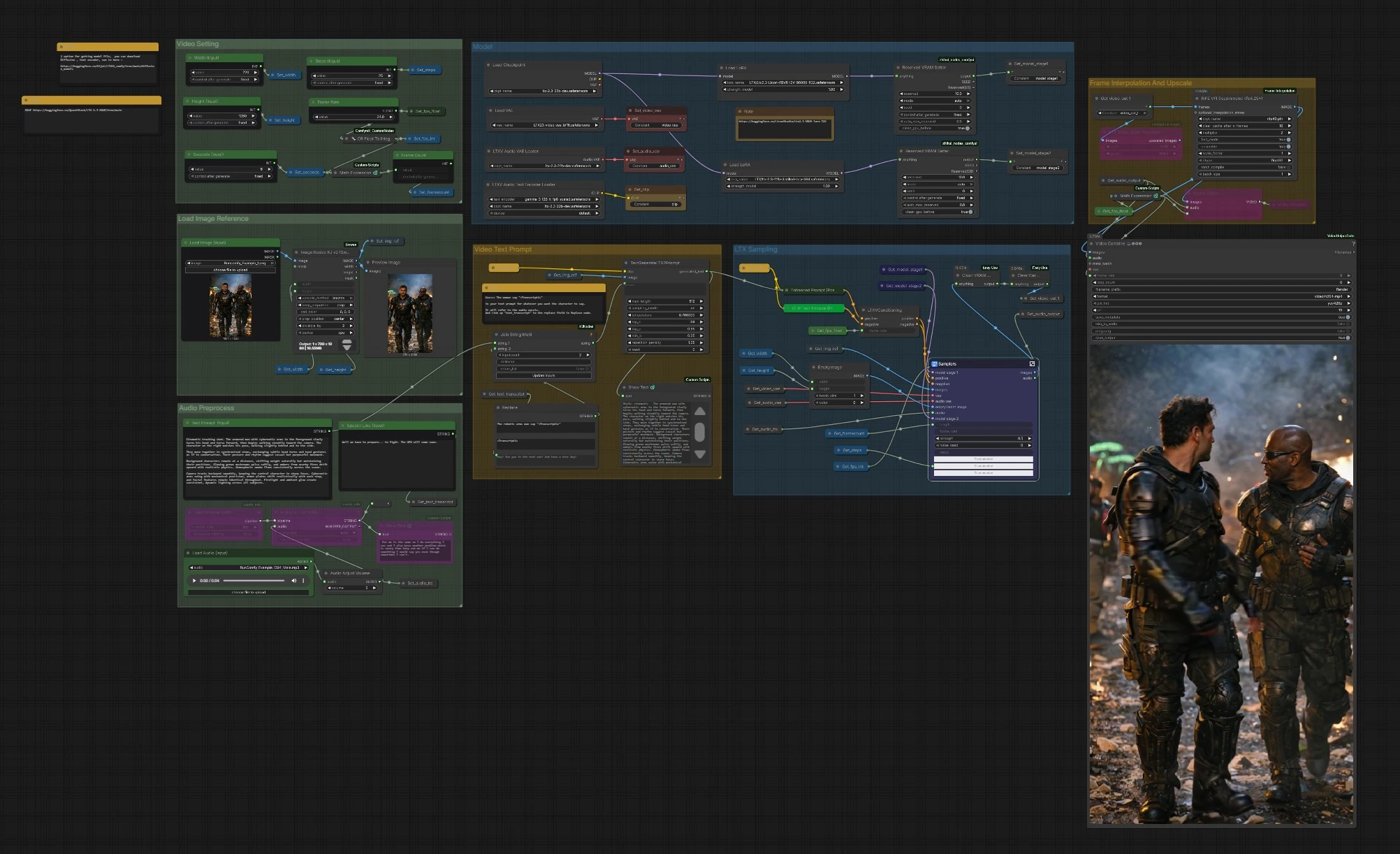
LTX 2.3 VBVR ComfyUIワークフロー: ダイアログ付き推論認識イメージからビデオへ#
このワークフローは、単一の参照画像をテキストとオプションの音声によって導かれる一貫したビデオシーケンスに変換します。LTX-2.3とLTX 2.3 VBVR LoRAによって強化されています。VBVRはビデオベースの視覚推論を意味し、モデルがフレーム全体でアイデンティティ、空間関係、因果関係を一貫して保つのを助けます。グラフには、音声認識プロンプト、2段階のLTXサンプリング、動きのスムージング、最終的なアップスケール/MP4へのエクスポートが含まれています。
物語の連続性、信じられる動き、またはダイアログのタイミングが必要なクリエイターにとって、LTX 2.3 VBVRワークフローは特に有用です。強力な参照フレームを提供し、アクションと相互作用を説明し、必要に応じて自動トランスクリプションされてプロンプトに組み込まれる音声行を挿入します。
Comfyui LTX 2.3 VBVRワークフローの主要モデル#
- LightricksのLTX-2.3 22Bビデオ生成モデルは、イメージからビデオおよびオーディオ条件付きデコーディングのためのメイン拡散バックボーンです。Hugging Face: Lightricks/LTX-2.3
- ビデオラテンツのエンコード/デコード用のLTX-2.3 Video VAEで、効率的なタイルデコーディングのためのベースチェックポイントとペアになっています。Hugging Face: Lightricks/LTX-2.3
- 初回パス後の空間詳細を強化するためのLTX-2.3 Spatial Upscaler x2ラテントモデル。Hugging Face: Lightricks/LTX-2.3
- 複雑な指示とダイアログトークンを解析するためにLTX-2にパッケージされたGemma 3 12Bテキストエンコーダー。Hugging Face: Comfy-Org/ltx-2
- 推論中心のシーン構造、オブジェクト相互作用、時間を超えた連続性のためのLTX 2.3 VBVR LoRA。Hugging Face: LiconStudio/Ltx2.3-VBVR-lora-I2V
- 生成されたフレーム間の動きをスムージングするRIFEフレーム補間モデル。GitHub: hzwer/Practical-RIFE
- オプションの音声からテキストへのプロンプト注入のためのWhisper音声認識モデル。GitHub: openai/whisper
Comfyui LTX 2.3 VBVRワークフローの使用方法#
グラフは明確なグループに整理されています。入力、モデルスタック、ビデオ設定を構成し、LTXサンプラーがフレームを生成し、必要に応じて補間とアップスケールを行ってからエクスポートします。
画像参照の読み込み#
Load Image (Input) (#5525) を使用して、スタイルに合った強力な参照フレームを選択します。画像は ImageResizeKJv2 (#5280) によって選択した幅と高さにリサイズされ、構成を維持します。プレビューノードは、モデルが実際に何を見るかを確認します。明確な被写体とライティングを備えた良い参照画像は、LTX 2.3 VBVRスタックにとって信頼できるアイデンティティとスタイルのアンカーを提供します。
ビデオ設定#
Width (Input) (#5284)、Height (Input) (#5286)、Seconds (Input) (#5573)、およびベース Frame Rate (#5289) を設定します。グラフはフレーム数を自動的に計算するため、期間やfpsを変更してもタイミングが一貫します。後で補間を有効にする予定の場合は、時間を節約するために控えめなベースfpsを選択し、RIFEがスムーズさを追加します。これらの設定は、条件付けノードに通知され、動きとペースを一貫させます。
モデル#
CheckpointLoaderSimple (#5493) がLTX-2.3をロードします。グラフは LoraLoaderModelOnly (#5616) を介してLTX 2.3 VBVR LoRAをアタッチし、オプションで蒸留されたLoRAとディテーラーLoRAを適用して追加の忠実度を提供できます。LTXAVTextEncoderLoader (#5494) はGemmaベースのテキストエンコーダーを導入し、VAELoader (#5629) と LTXVAudioVAELoader (#5492) がビデオとオーディオVAEを提供します。2つの ReservedVRAMSetter ノードはメモリ使用量をバランスさせ、長時間の実行を安定させます。
ビデオテキストプロンプト#
シーンを Text Prompt (Input) (#5620) に書き込みます。音声と合わせてダイアログを挿入するには、次のようなプレースホルダーを含めます: The woman says "<Transcript1>". 実際のセリフを Speech Line (Input) (#5524) に入力するか、Whisperが音声から生成します。StringReplace (#5226) と JoinStringMulti (#5602) が <Transcript1> をトランスクリプトに置き換えます。TextGenerateLTX2Prompt (#5488) は洗練された指示を構成し、Enhanced Prompt (Positive) (#5174) がエンコードしてから LTXVConditioning (#5173) が最終ガイダンスを準備します。明確な動詞、主題の参照、および空間的な手がかりは、LTX 2.3 VBVR LoRAが時間を超えて推論するために必要なコンテキストを与えます。
オーディオ前処理#
音声トラックを Load Audio (Input) (#5590) で持ち込むかTTSを接続します。AudioAdjustVolume (#5601) がレベルを正規化します。プロンプト認識ダイアログが必要な場合は、Load Whisper (mtb) (#5606) と Audio To Text (mtb) (#5607) を使用してプロンプトで使用されるトランスクリプトを生成します。同じ音声はラテントとしてもエンコードされ、最終ビデオに再びミックスされるため、唇とタイミングの手がかりが生成に影響を与えます。
LTXサンプリング#
LTXVPreprocess (#5240) と LTXVImgToVideoInplace (#5245) は、参照フレームを初期ラテントシーケンスに変換し、コアアイデンティティを保持しながら動きを許可します。Samplers サブグラフ (#5278) は、CFGガイダーとスケジューラを使用して2段階のプロセスを実行し、プロンプトとLTX 2.3 VBVR推論LoRAの両方を尊重する時空間ラテントを生成します。オーディオラテントはビデオラテントと連結され、音声のタイミングが動きに影響を与えます。LTXVSpatioTemporalTiledVAEDecode (#5237) がフレームをデコードし、LTXVAudioVAEDecode (#5103) が音声トラックを復元します。
フレーム補間とアップスケール#
RIFE VFI (#5554) はフレーム間を補間してスムーズな動きを作り、ベースfpsと組み合わせてターゲット再生速度に到達します。RTXVideoSuperResolution (#5631) は詳細を強化し、圧縮アーティファクトを減少させ、顔、エッジ、小道具の読みやすさを向上させます。この段階を使用して速度と品質のバランスを取ります: スムーズさのために補間し、鮮明さのためにアップスケールします。
エクスポート#
シンプルなマックスを CreateVideo (#5599) で選択するか、VHS_VideoCombine (#5618) を使用してフォーマット、メタデータ、トリミングに対するコントロールを増やします。パイプラインは SaveVideo (#5597) を介してH.264 MP4を書き込みます。フレームレートは設定と補間段階から導出され、再生が最初に作成した動きの意図に一致します。
Comfyui LTX 2.3 VBVRワークフローの主要ノード#
LoraLoaderModelOnly (#5616)#
論理的な連続性、オブジェクト相互作用、カメラ認識の動きを向上させるLTX 2.3 VBVR LoRAをロードします。LoRAの重みを調整して、ベースモデルと他のLoRAからのスタイルと推論の影響をバランスさせます。このノードは、LTX 2.3 VBVRワークフローを定義する独特の外観と一貫性の中心です。LTXノードとLoRAの使用法については、Lightricks/ComfyUI-LTXVideo およびVBVR LoRAカードを参照してください。
TextGenerateLTX2Prompt (#5488)#
基本説明、画像参照、<Transcript1> から置換されたダイアログトークンをマージすることで最終的なポジティブプロンプトを組み立てます。指示を簡潔で明確にし、主題と行動について一貫性を保ち、モデルが時間を超えて推論できるようにします。これは、LTX 2.3 VBVR LoRAがサンプリング中に強化する意図をエンコードする場所です。
LTXVConditioning (#5173)#
ポジティブとネガティブの条件付けをパッケージし、タイミング情報を転送して動きとペースがfpsの選択に一致するようにします。設定でフレームレートを変更する場合は、ここで更新して動きのダイナミクスを一貫させます。強いネガティブは、静止フレーム、透かし、または不要なオーバーレイがシーケンスに入り込むのを防ぐのに役立ちます。
Samplers (#5278)#
2段階のサンプラーブロックは、ノイズ、ガイダンス、およびスケジューリングを調整して、イメージとオーディオラテントを一貫したビデオに変換します。最も影響力のある調整は、steps の全体、初期I2V段階の image strength、および再現性のための noise_seed です。これらを慎重に調整して、参照フレームの忠実度と新しい動きや行動を追従する意欲をトレードオフします。
RIFE VFI (#5554)#
フレームを補間してスムーズな動きを作成したり、シーケンスを再生成せずに高い効果的なfpsに到達します。ベースfpsが低い場合や動きがぎこちないと感じる場合に補間を増やし、元の生成リズムを保持するために減らします。このモデルは高品質のVFIに広く使用されています。RIFEプロジェクトについてはGitHubを参照してください。
オプションのエクストラ#
- LTX 2.3 VBVRでのダイアログトリック: プレースホルダーを使用して自然な文を作成します。例えば、The woman says "<Transcript1>" と書き、Speech Lineに行を入力するか、Whisperが音声をトランスクリプションしてプロンプトと唇を一致させます。
- 推論のためのプロンプト: 誰が何を、どこで、なぜ行うかを呼び出します。一貫した主題名と時間の手がかり(例えば、その後、の間に、カメラが動くときなど)を使用してVBVRの強みを活用します。
- より速い繰り返し: 短い期間や低いベースfpsで始め、動きの拍子を確認し、補間や秒数を増やして仕上げます。
- 安定性のヒント: アイデンティティドリフトが見られる場合は、イメージからビデオへの強度を少し下げるか、VBVR LoRAの重みを上げます。過剰拘束が見られる場合は逆を行います。
謝辞#
このワークフローは、以下の作品とリソースを実装および基にしています。2.3 VBVRワークフローソースのための貢献と維持に感謝します。権威ある詳細については、以下の元のドキュメントおよびリポジトリを参照してください。
リソース#
- LTX/2.3 VBVRワークフローソース
- ドキュメント / リリースノート: LTX 2.3 VBVR Workflow Source @Benji’s AI Playground
注: 参照されたモデル、データセット、およびコードの使用は、各著者およびメンテナーによって提供されるそれぞれのライセンスおよび条件に従います。