
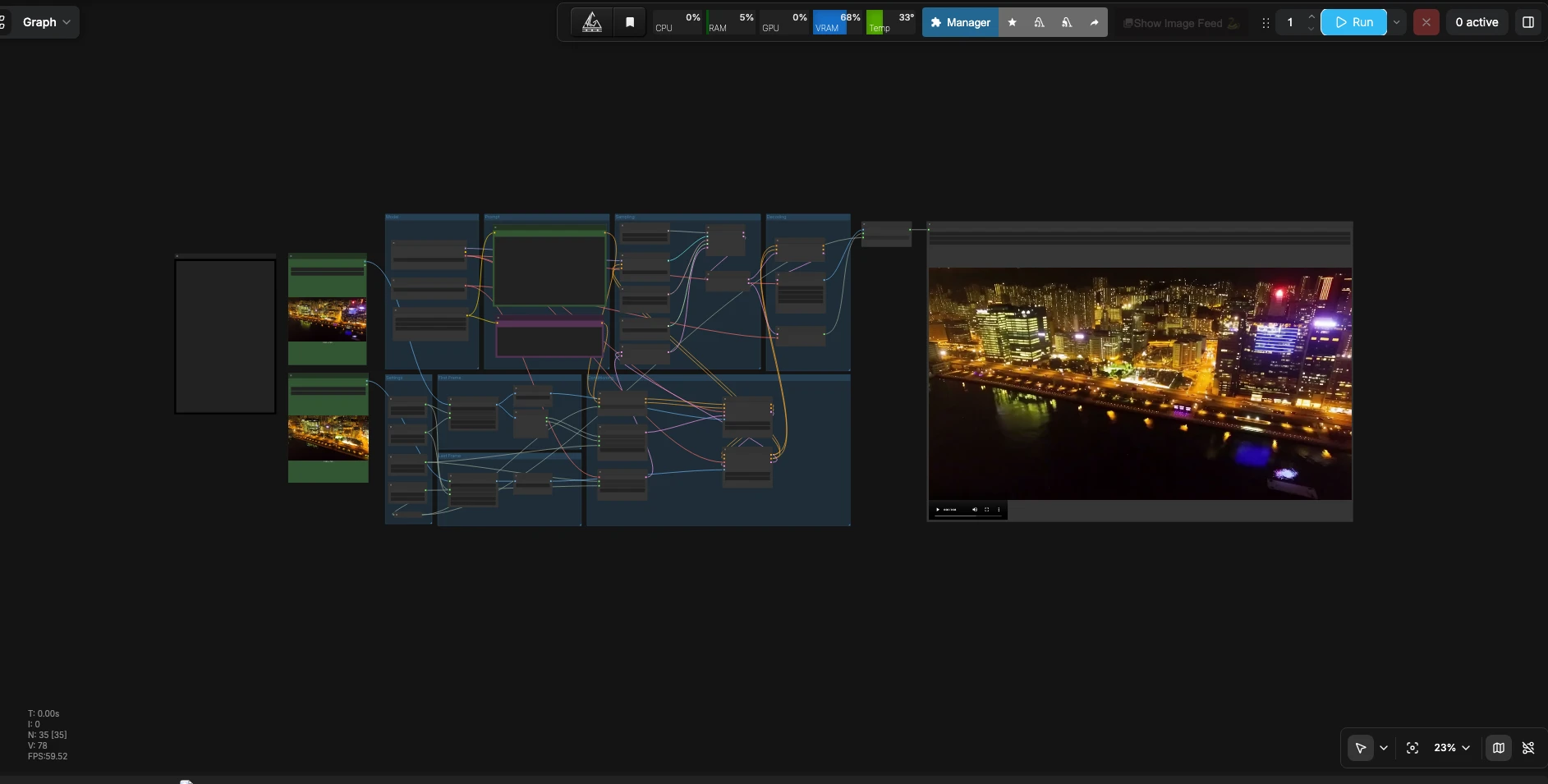
LTX 2.3 First Last Frame to Video#
LTX 2.3 First Last Frame to Videoは、ComfyUIワークフローで、2つの静止画像を滑らかで連続したビデオに変換し、音声を同期させます。最初のフレーム、最後のフレーム、動き、シーンの詳細、音声を説明する自然言語プロンプトを提供します。LTX-2.3 22B distilled FP8チェックポイントによって駆動されるパイプラインは、画像間を補間し、一貫した外観とタイミングを維持します。シームレストランジションまたはComfyUI内で直接作成された短いループクリップが必要なエディター、モーションデザイナー、ストーリーボードアーティストに理想的です。
このLTX 2.3 First Last Frameワークフローは、効率的な推論と高いプロンプト忠実性を強調しています。FP8ウェイトはVRAMの使用を抑え、Gemma 3 12Bテキストエンコーダーは視覚と音声指示の意味理解を向上させます。結果は、プロンプトを尊重し、生成された音声と同期した、最初から最後のフレームへの一貫した視覚的なパッセージです。
Comfyui LTX 2.3 First Last Frameワークフローの主要モデル#
- LightricksによるLTX-2.3 22B Distilled FP8チェックポイント。効率的な推論のために蒸留されたコアビデオ生成モデルで、ここで2つの画像ガイドとテキストプロンプトに基づいて時間的に一貫したフレームを合成するために使用されます。Model card
- Gemma 3 12B ITテキストエンコーダー。プロンプトの視覚的および音声的側面のための堅牢な言語理解を提供し、正確な動き、シーン属性、およびサウンドトラックのキューを可能にします。Model card
- LTX-2.3の潜在VAEは、ビデオとオーディオ用です。これらのコンポーネントは、画像と波形オーディオをコンパクトな潜在変数にマッピングし、デコード中に品質を保持しながらサンプリングを効率化します。LTX-2.3 FP8リリースとともに出荷されます。Model card
Comfyui LTX 2.3 First Last Frameワークフローの使用方法#
このワークフローは、2つの参照画像とプロンプトを取り、最初と最後のフレームガイドでコンディショニングを構築し、同期されたオーディオを伴うビデオ潜在変数をサンプリングし、すべてを再生可能なファイルにデコードします。
設定
- 設定グループでターゲット解像度、フレーム数、フレームレートを設定します。幅と高さは作業キャンバスを定義し、入力フレームはモデルがクリーンに補間できるようにサイズ変更されます。フレーム数はトランジションの長さを制御し、フレームレートは再生速度を設定します。ソースに一致するアスペクト比を選択して、不必要なクロッピングを避けます。ノード
WIDTH(#113)、HEIGHT(#98)、Length(#102)、およびFrame Rate(int)(#114)がこれらの選択をアンカーします。
最初のフレーム
Load First Frame(#31)で開始画像をロードします。それはResizeImageMaskNode(#124)によってターゲット寸法にリサイズされ、LTXVPreprocess(#104)によって正規化されます。これにより、クリップの開始時に強力な構造と色のガイドとして機能します。最良の結果を得るには、シャープで明るい画像を使用してください。
最後のフレーム
Load Last Frame(#39)で終了画像をロードします。画像はResizeImageMaskNode(#125)で同じサイズに合わせられ、LTXVPreprocess(#99)で正規化されます。これにより、トランジションの最後に望む最終的な外観とレイアウトが保証されます。ループの場合、最初のフレームと視覚的に互換性のある最後のフレームを作成してください。
プロンプト
LTXAVTextEncoderLoader(#103)がテキストエンコーダーを提供し、2つのCLIPTextEncodeノードが肯定的および否定的なプロンプトをキャプチャします。肯定的なプロンプト(CLIPTextEncode(#128))では、カメラの動き、被写体、照明を説明し、「Music: ambient pads with soft percussion」や「Dialogue: brief whisper」のような音声キューも含めてください。否定的なプロンプト(CLIPTextEncode(#112))では、抑制したいアーティファクトや特性をリストできます。
コンディショニング
LTXVConditioning(#109)は、タイミング情報とともにテキストコンディショニングを統合し、動きとオーディオが選択したフレームレートと一致するようにします。EmptyLTXVLatentVideo(#108)は、解像度と長さに合わせたビデオ潜在変数を作成します。2回のLTXVAddGuideのパスは、最初に最初のフレームを(LTXVAddGuide(#115))、次に最後のフレームを(LTXVAddGuide(#111))アタッチし、モデルが開始と終了の場所を知るようにします。LTXVEmptyLatentAudio(#101)は、同じ期間のオーディオ潜在変数を初期化し、LTXVConcatAVLatent(#119)がオーディオとビデオの潜在変数をサンプリングのために束ねます。
モデル
CheckpointLoaderSimple(#127)は、LTX-2.3 22B distilled FP8ウェイトとビデオVAEをロードし、LTXVAudioVAELoader(#126)がオーディオVAEを提供します。これらは事前に設定されているので、クリエイティブな入力に集中でき、設定の詳細に気を取られることはありません。
サンプリング
CFGGuider(#116)は、テキストとガイドフレームへの追従と創造的自由のバランスを取ります。RandomNoise(#100)は再現性のためのシードを設定します。サンプラーはSamplerEulerAncestral(#117)を使い、ManualSigmas(#118)からのカスタムスケジュールで、SamplerCustomAdvanced(#120)によってオーケストレーションされ、潜在変数を段階的に洗練して、動きとオーディオの指示に従った一貫したシーケンスにします。
デコード
- サンプリング後、
LTXVSeparateAVLatent(#121)が結合された潜在変数をビデオとオーディオに分割します。LTXVCropGuides(#106)は、画像デコード前にエッジアーティファクトを減らすために空間ガイダンスを洗練します。VAEDecodeTiled(#105)はフレームシーケンスを生成し、LTXVAudioVAEDecode(#107)がオーディオ波形を生成します。CreateVideo(#122)が選択したfpsでフレームとサウンドをマルチプレックスし、SaveVideo(#68)が最終ファイルをComfyUI出力に書き込みます。
Comfyui LTX 2.3 First Last Frameワークフローの主要ノード#
EmptyLTXVLatentVideo (#108)
- クリップの作業解像度と期間を定義します。ここで幅、高さ、長さを調整して、視覚的スケールとトランジション時間を設定します。長い期間には、プロンプトに強い動きのキューが必要です。
LTXVAddGuide (#115)
- シーケンスの開始時に最初のフレームを構造と色のアンカーとして注入します。オープニングがソースからずれる場合は、このガイドの影響力を増やし、過剰に制約されていると感じる場合は、動きをより許容するために少し減らします。
LTXVAddGuide (#111)
- クリップの終わりにターゲットの外観をアンカーします。トランジションがオーバーシュートするか、最後のフレームにまったく到達しない場合は、ガイドの影響力を上げ、終わりに硬くスナップする場合は、少し下げます。
CFGGuider (#116)
- モデルがテキストと画像のコンディショニングにどれだけ強く従うかを制御します。ガイダンスを高くすると、プロンプトとガイドが強調されますが、滑らかさが低下する可能性があります。自由度が高く感じるが、意図した外観から逸脱する場合があります。小さなステップで調整し、比較する際に同じシードを再利用します。
SamplerCustomAdvanced (#120) with SamplerEulerAncestral (#117) and ManualSigmas (#118)
- 一貫したスケジュールで安定した動きを駆動します。短いスケジュールは高速ですが、粗くなる可能性があります。長いまたは穏やかなスケジュールは、一貫性を改善しますが、追加の計算コストがかかります。A/Bテストで他のパラメータをテストする際に、スケジュールを一貫させてください。
CreateVideo (#122)
- デコードされたフレームとオーディオを選択したフレームレートで最終クリップにマルチプレックスします。条件付けたのと同じfpsを使用して、リップシェイプ、足音、または音楽の脈動が整列したままになるようにします。
オプションの追加#
- 動詞とタイミングでプロンプトを書く: “camera trucks forward,” “lights dim as we approach,” “Music: sparse piano with soft reverb.” 明確な動詞はLTX 2.3 First Last Frameパイプラインが動きとリズムを推測するのに役立ちます。
- 2つの画像のアスペクト比と向きを一致させる。大きな不一致は不要なクロッピングやストレッチングを引き起こす可能性があります。
- シームレスなループのために、最後のフレームを最初のフレームに近いものにし、カメラの動きを循環させます。
RandomNoiseでシードを再利用して、プロンプトやガイドの強さを反復する間に外観を再現します。シードを変更して、新しいバリエーションを探ります。- 実装の詳細やカスタムノードの参照が必要な場合は、ComfyUIのLTX統合とComfyUI-LTXTricksなどのユーティリティを参照してください。Repository
謝辞#
このワークフローは、以下の作品とリソースを実装し、構築しています。LightricksによるLTX-2.3 22B Distilled FP8 Checkpoint、GoogleによるGemma 3 12B IT FP4 Text Encoder、logtdによるComfyUI-LTXTricks Custom Nodes、Comfy.orgによるComfy.org Official Workflowに感謝いたします。詳細については、以下のリンクされたオリジナルのドキュメントとリポジトリを参照してください。
リソース#
- Lightricks/LTX-2.3 22B Distilled FP8 Checkpoint
- Hugging Face: Lightricks/LTX-2.3-fp8
- Google/Gemma 3 12B IT FP4 Text Encoder
- Hugging Face: google/gemma-3-12b-it
- logtd/ComfyUI-LTXTricks Custom Nodes
- GitHub: logtd/ComfyUI-LTXTricks
- Comfy.org/Comfy.org Official Workflow
- Docs / Release Notes: comfy.org/workflows/video_ltx2_3_flf2v
注意: 参照されたモデル、データセット、およびコードの使用は、それぞれの著者および管理者によって提供されるライセンスおよび条件に従います。