
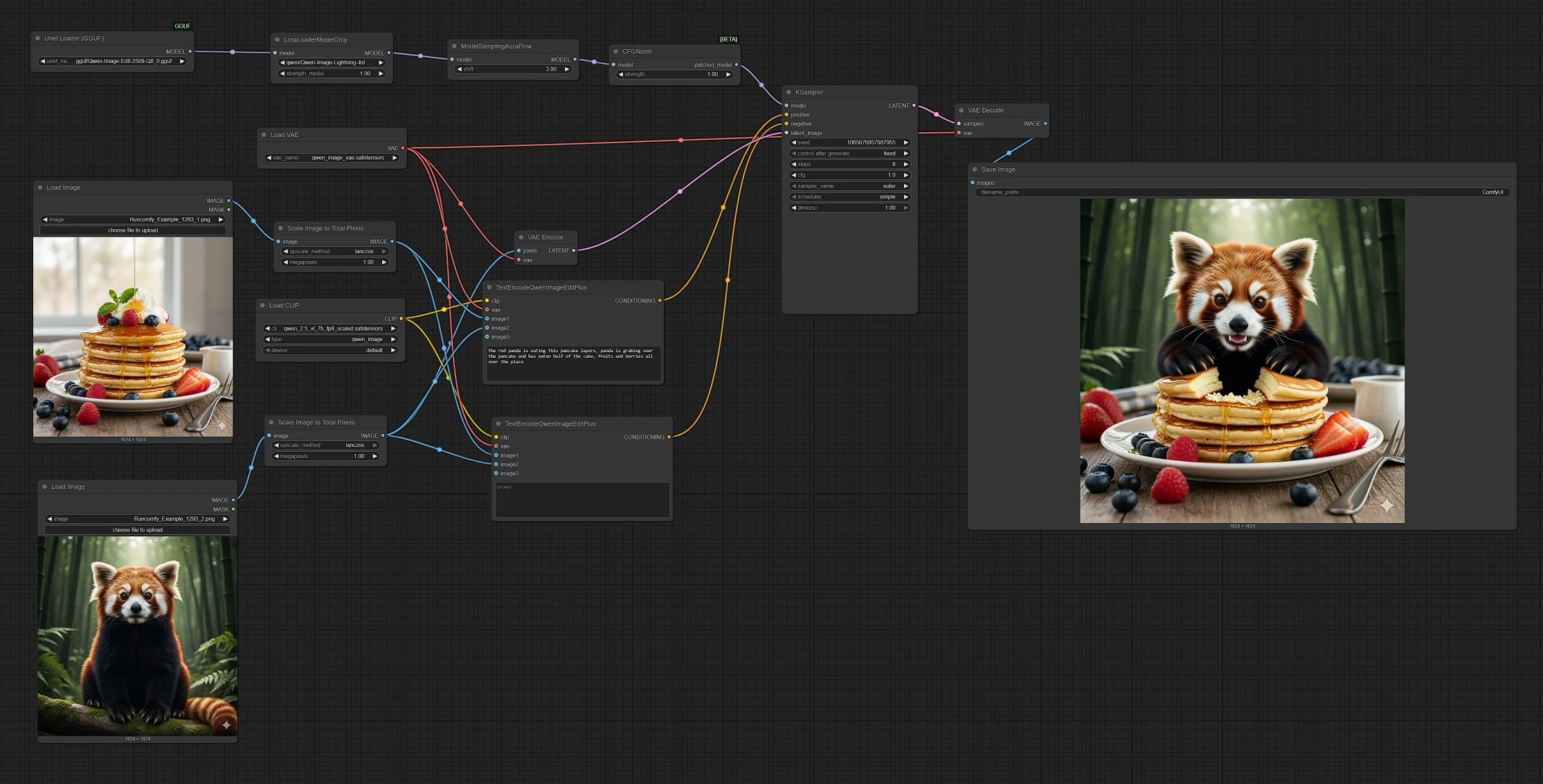






Qwen Image Edit 2509: multi‑image, prompt‑driven editing and blending for ComfyUI#
Qwen Image Edit 2509 is a multi‑image editing workflow for ComfyUI that fuses 2–3 input images under a single prompt to create precise edits and seamless blends. It is designed for creators who want to composite objects, restyle scenes, replace elements, or merge references while keeping control intuitive and predictable.
This ComfyUI graph pairs the Qwen image model with an editing‑aware text encoder so you can steer results with natural language and one or more visual references. Out of the box, Qwen Image Edit 2509 handles style transfer, object insertion, and scene remixes, producing coherent results even when sources vary in look or quality.
Key models in Comfyui Qwen Image Edit 2509 workflow#
- Qwen Image Edit 2509 (Diffusion Model & GGUF, Q8_0). The primary image editing checkpoint, loaded in quantized form to reduce VRAM while preserving editing behavior. It provides the diffusion backbone that interprets text and reference images during sampling.
- Qwen Image VAE. A dedicated VAE tailored for Qwen Image that encodes the base canvas to latent space and decodes final results back to pixels. Asset source: Comfy-Org/Qwen-Image_ComfyUI.
- Qwen 2.5 VL 7B text encoder (FP8 scaled). A vision‑language text encoder packaged for ComfyUI that turns your prompt plus reference images into editing conditions. Asset source: Comfy-Org/Qwen-Image_ComfyUI.
- Qwen‑Image‑Lightning‑4steps‑V1.0 LoRA. An optional LoRA that biases the model toward fast, high‑impact updates, useful for quick iterations or low step counts. Model page: lightx2v/Qwen-Image-Lightning.
How to use Comfyui Qwen Image Edit 2509 workflow#
This workflow follows a clear path from inputs to output: you load 2–3 images, write a prompt, the graph encodes both text and references, sampling runs over a latent base, and the result is decoded and saved.
Stage 1 — Load and size your sources
- Use
LoadImage(#103) for Image 1 andLoadImage(#109) for Image 2. Image 2 acts as the base canvas that will receive edits. - Each image passes through
ImageScaleToTotalPixels(#93 and #108) so both references share a consistent pixel budget. This stabilizes composition and style transfer. - If you want a third reference, plug another
LoadImageinto theimage3input on the encoding nodes. Qwen Image Edit 2509 accepts up to three images for richer guidance.
Stage 2 — Write the prompt and set intent
- The positive encoder
TextEncodeQwenImageEditPlus(#104) combines your text prompt with Image 1 and Image 2 to describe the result you want. Use natural language to request merges, replacements, or style cues. - The negative encoder
TextEncodeQwenImageEditPlus(#106) lets you steer away from unwanted details. Keep it empty to stay neutral or add phrases that suppress artifacts or styles you do not want. - Both encoders use the Qwen text encoder and VAE, so the model “sees” your references as part of the instruction.
Stage 3 — Prepare the model
UnetLoaderGGUF(#102) loads the Qwen Image Edit 2509 backbone in GGUF format for efficient inference.LoraLoaderModelOnly(#89) applies the Qwen‑Image‑Lightning LoRA. Increase its influence for punchier edits or reduce it for more conservative updates.- The model is then readied for sampling with a configuration tuned for editing stability.
Stage 4 — Guided generation
- The base canvas (Image 2) is encoded by
VAEEncode(#88) and provided toKSampler(#3) as the starting latent. This makes the run image‑to‑image rather than pure text‑to‑image. KSampler(#3) fuses the positive and negative conditions with the latent canvas to produce the edited result. Lock the seed for reproducibility or vary it to explore alternatives.- Guidance and sampling choices balance fidelity to your sources with prompt adherence, giving Qwen Image Edit 2509 its blend of precision and flexibility.
Stage 5 — Decode and save
VAEDecode(#8) converts the final latent to an image, andSaveImage(#60) writes it to your output folder. Filenames reflect the run so you can compare versions easily.
Key nodes in Comfyui Qwen Image Edit 2509 workflow#
TextEncodeQwenImageEditPlus (#104)#
This node creates the positive editing condition by combining your prompt with up to three reference images via the Qwen encoder. Use it to specify what should appear, which style to adopt, and how strongly references should influence the result. Start with a clear, single‑sentence goal, then add style descriptors or camera cues as needed. Assets for the encoder are packaged in Comfy-Org/Qwen-Image_ComfyUI.
TextEncodeQwenImageEditPlus (#106)#
This node forms the negative condition to prevent unwanted traits. Add short phrases that block artifacts, over‑smoothing, or mismatched styles. Keep it minimal to avoid fighting the positive intent. It uses the same Qwen encoder and VAE stack as the positive path.
UnetLoaderGGUF (#102)#
Loads the Qwen Image Edit 2509 checkpoint in GGUF format for VRAM‑friendly inference. Higher quantization saves memory but may slightly affect fine detail; if you have headroom, try a less aggressive quant to maximize fidelity. Implementation reference: city96/ComfyUI-GGUF.
LoraLoaderModelOnly (#89)#
Applies the Qwen‑Image‑Lightning LoRA on top of the base model to accelerate convergence and strengthen edits. Increase strength_model to emphasize this LoRA’s effect or lower it for subtle guidance. Model page: lightx2v/Qwen-Image-Lightning. Core node reference: comfyanonymous/ComfyUI.
ImageScaleToTotalPixels (#93, #108)#
Resizes each input to a consistent total pixel count using high‑quality resampling. Raising the megapixel target yields sharper results at the cost of time and memory; lowering it speeds iteration. Keep both references at similar scales to help Qwen Image Edit 2509 blend elements cleanly. Core node reference: comfyanonymous/ComfyUI.
KSampler (#3)#
Runs the diffusion steps that transform the latent canvas according to your conditions. Adjust steps and sampler to balance speed and fidelity, and vary the seed to explore multiple compositions from the same setup. For tight edits that preserve structure from Image 2, keep step counts moderate and rely on the prompt and references for control. Core node reference: comfyanonymous/ComfyUI.
Optional extras#
- Treat Image 2 as the canvas and Image 1 as the donor; describe in the prompt which elements should transfer and which should remain.
- Use concise negatives to curb halos, texture drift, or over‑stylization; long negative lists can conflict with your goal.
- If results look too conservative, increase the LoRA strength or sampling steps slightly; if they drift too far from the base, reduce them.
- Raise the megapixel target when finalizing, then reuse the same seed to upscale the exact composition you liked.
- Keep prompts concrete: subject, action, setting, and style. Qwen Image Edit 2509 responds best to clear intent with a few strong descriptors.
Acknowledgements#
This workflow implements and builds upon the following works and resources. We gratefully acknowledge RobbaW for the Qwen Image Edit 2509 Workflow for their contributions and maintenance. For authoritative details, please refer to the original documentation and repositories linked below.
Resources#
- RobbaW/Qwen Image Edit 2509 Workflow
- Hugging Face: QuantStack/Qwen-Image-Edit-2509-GGUF
- Docs / Release Notes: Qwen Image Edit 2509 Workflow @RobbaW from Reddit r/comfyui
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.

