
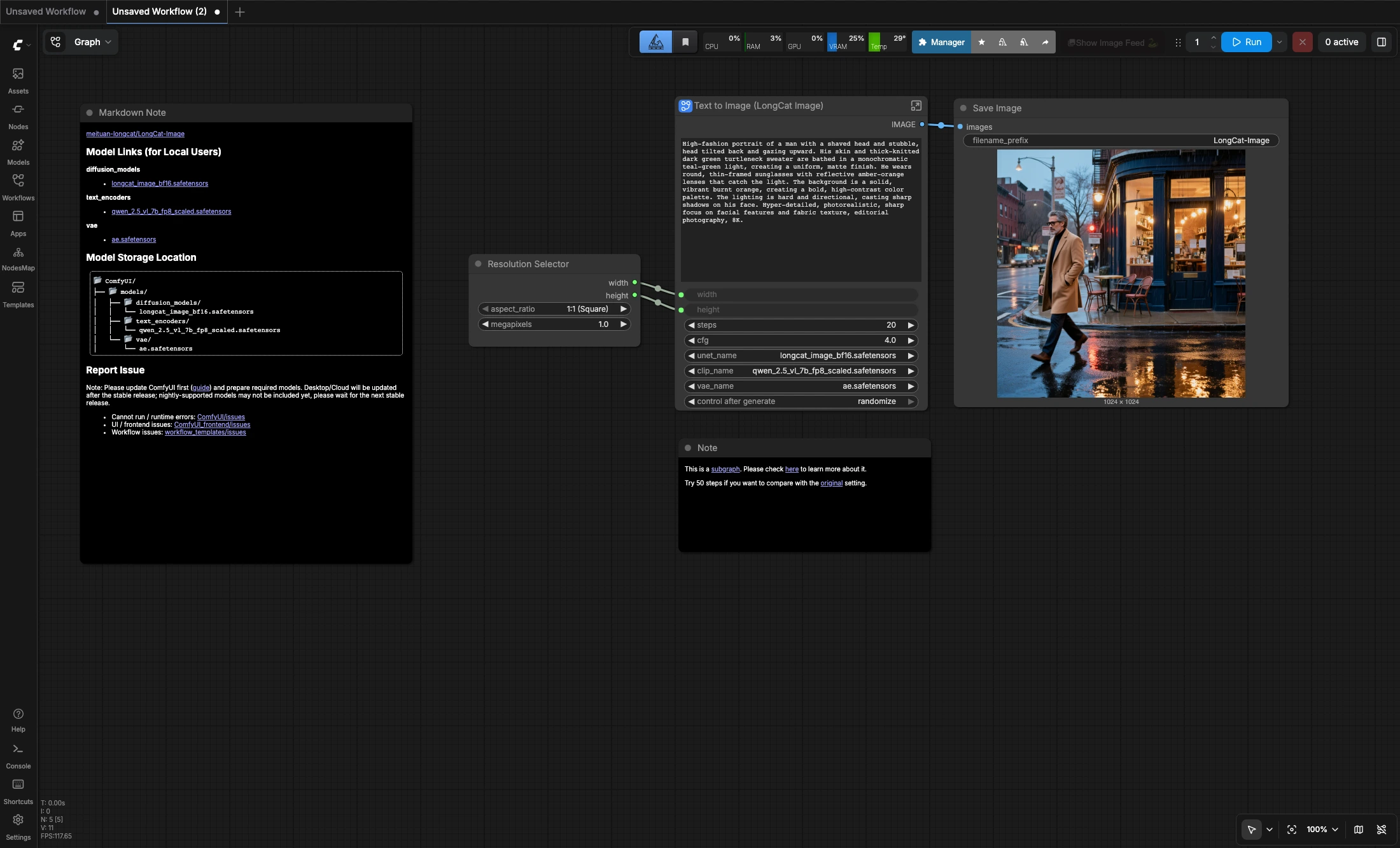



LongCat Imageテキストから画像へのComfyUIワークフローとは?#
LongCat Imageテキストから画像へは、テキストプロンプトから1024x1024のスクエア画像を生成するためのコンパクトなComfyUIワークフローです。LongCat-Image拡散モデルをQwen 2.5 VLテキストエンコーダーとAE VAEとともに使用し、ポートレート、商品撮影、洗練された編集スタイルのビジュアルのためのシンプルなプロンプトから画像へのセットアップを提供します。
グラフは意図的にシンプルです:スクエア解像度を選択し、プロンプトを書き、ワークフローを実行し、画像を保存します。英語または中国語のプロンプトで迅速な反復に適しており、元のモデル設定と比較したい場合は50ステップを試すことをお勧めします。
LongCat Imageテキストから画像への主な特徴#
- スクエア優先生成: デフォルトの設定は1:1出力の1024x1024に調整されています。
- コンパクトなワークフローデザイン: グラフは余分なルーティングの複雑さなしでプロンプトから画像生成に集中しています。
- 柔軟なプロンプト: 英語と中国語のテキストプロンプトの両方に適しています。
- 簡単な品質調整: デフォルトの20ステップ設定から開始し、よりゆっくりした慎重なサンプリングを望むときはステップ数を増やします。
ComfyUIでLongCat Imageを使用する方法#
- 出力サイズを選択する
Resolution Selectorノードを使用してデフォルトのスクエアレイアウトを維持するか、必要に応じてターゲットメガピクセルを調整します。
- プロンプトを書く
Text to Image (LongCat Image)サブグラフを開き、デフォルトのプロンプトを自分の主題、照明、ムード、構図の指示に置き換えます。
- ワークフローを実行する
- グラフをキューに入れてプロンプトから単一の画像を生成します。
- 結果を保存する
Save Imageノードは、実行が完了すると最終出力を書き込みます。
ヒントと設定#
- 現在のデフォルト設定は20ステップでCFG 4です。
- ソースワークフローからの元の推奨事項と比較したい場合は、50ステップを試してください。
- 明確で具体的なプロンプトは、このコンパクトなグラフでは幅広いまたは抽象的なプロンプトフラグメントよりもうまく機能する傾向があります。
リソース#
- ワークフローソース: Comfy.org workflow page
- 公式モデル: meituan-longcat/LongCat-Image on Hugging Face
