
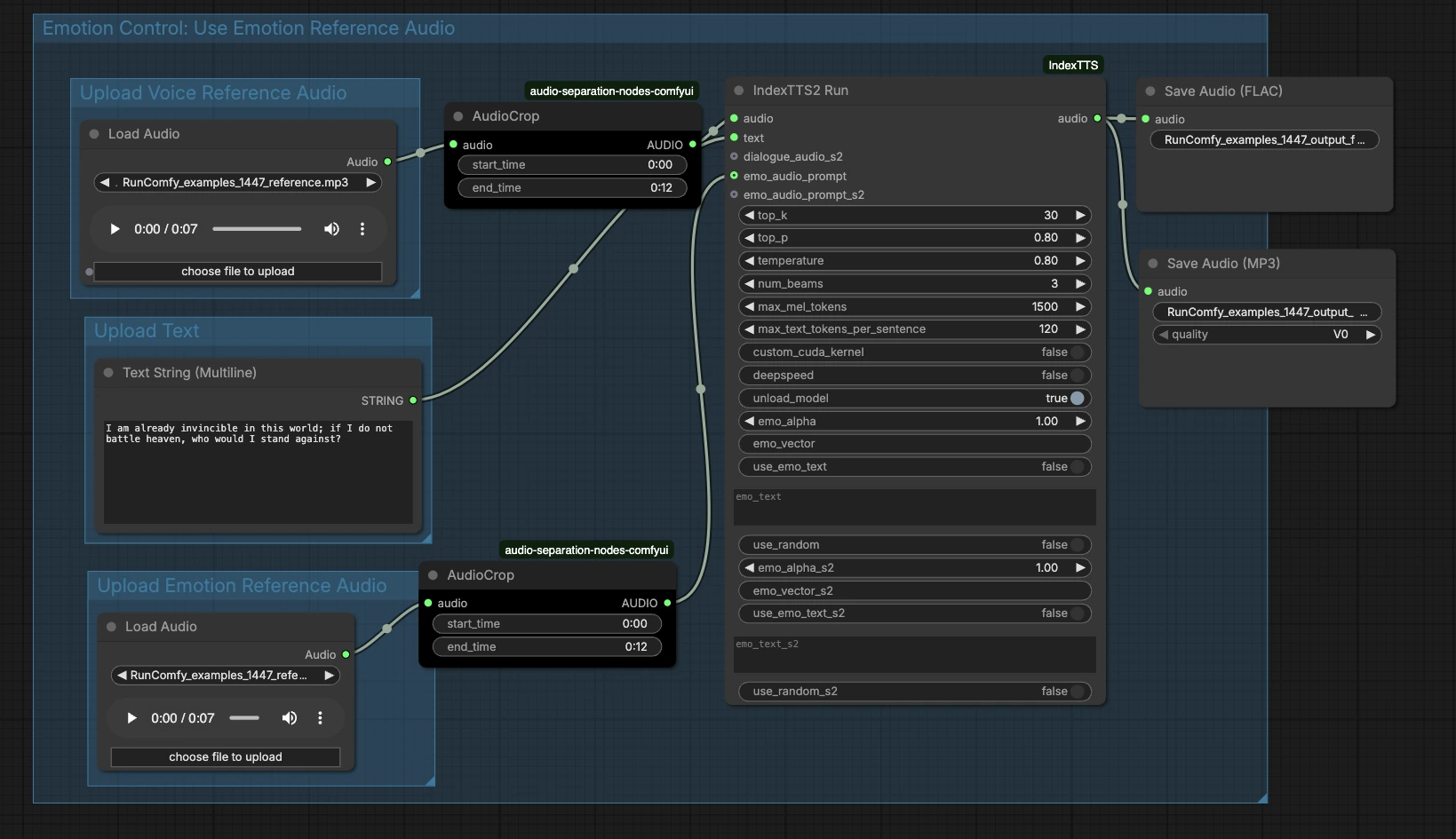
IndexTTS2 ComfyUI ワークフロー: 参照オーディオを使用した感情的な音声クローン#
このIndexTTS2 ComfyUIワークフローは、短い参照クリップを自然で表現豊かな音声に変え、話者の音色とスタイルに一致させます。クリーンな参照オーディオ、オプションの感情プロンプト、スクリプトを提供すると、グラフは高品質の音声クローンを生成し、アーカイブ用にFLACとして、迅速な共有用にMP3としてエクスポートします。
IndexTTS-2モデルとComfyUI IndexTTSノードを中心に構築されたこのワークフローは、迅速で再現可能な感情的なTTSを求めるクリエイター、キャラクターデザイナー、教育者、RunComfyユーザーに最適です。すべてがComfyUI内で行われるため、入力を確認し、設定を調整し、ナレーション、対話、ボイスオーバーの例をすばやく反復できます。
Comfyui IndexTTS2 ComfyUI ワークフローの主要モデル#
- IndexTTS-2 by IndexTeam. 参照条件付き音声クローンと表現豊かなプロソディー制御を行う最新のテキスト音声変換システム。短い話者の例に基づいて、オプションで感情の手がかりに基づいてテキストから自然な音声をレンダリングします。Hugging Faceのモデルカードと付随する論文で、アーキテクチャとトレーニングの詳細を参照してください: IndexTTS-2, IndexTTSプロジェクト, IndexTTS-2論文。
Comfyui IndexTTS2 ComfyUI ワークフローの使用方法#
高レベルでは、グラフは3つの入力を受け取ります—参照音色オーディオ、テキスト、およびオプションの感情オーディオ—そして生成を実行し、結果をエクスポートします。以下のグループは、どこに入力を追加し、最終的な音声にどのように接続するかを示しています。
音声参照オーディオをアップロード#
このグループは話者のアイデンティティを準備します。LoadAudio (#13)にターゲット音声のクリーンサンプルをロードします。理想的には、音楽やエフェクトなしで明確に話す単一の話者です。AudioCrop (#37)を使用して安定したセグメントを分離し、システムが一貫した音色を学習できるようにします。安定したピッチと中立的なデリバリーを持つ短いセグメントは、最も信頼性の高いクローンを生成することがよくあります。クロップされた参照は、ジェネレーターを条件付けるために送信されます。
テキストをアップロード#
スクリプトをPrimitiveStringMultiline (#14)に入力します。明確な句読点はモデルが休止と強調を推測するのに役立つので、話したいようにテキストを書きます。複数の文を読むことを計画する場合は、各文を適切に形成し、絵文字や珍しい記号を避けてください。テキストは直接合成ノードに流れ込み、レンダリングされます。
感情参照オーディオをアップロード#
望む感情やデリバリーをキャプチャするオプションのクリップをLoadAudio (#15)を通じて提供します。AudioCrop (#38)で、模倣したい表現豊かな部分のみを保持するようにトリミングします。これは音色参照とは別で、リズム、エネルギー、トーンに焦点を当てます。このステップをスキップすると、IndexTTS2 ComfyUI ワークフローはテキストのみを使用してプロソディーを制御します。
感情制御: 感情参照オーディオを使用#
このエリアは、感情プロンプトをジェネレーターに接続します。クロップされた感情クリップは、IndexTTS2Run (#12)のemo_audio_prompt入力を供給し、声のターゲットを維持しながら、ケイデンスと強度をガイドします。感情オーディオの例がない場合は、ノードの感情テキストコントロールを使用してスタイルを調整することもできます。実際には、感情オーディオはより強く、一貫した表現力を提供し、感情テキストは軽い方向性を提供します。具体的な例とテキストのヒントの両方が欲しい場合は、これらを組み合わせてください。
生成とエクスポート#
IndexTTS2Run (#12)は、あなたのテキスト、音色参照、および任意の感情ガイダンスを使用して音声を合成します。出力はSaveAudio (#17)でロスレスFLACとして、SaveAudioMP3 (#39)で小さく、ウェブフレンドリーなプレビューとしてルートされます。保存ノードのファイル名フィールドを使用して、テイクを反復間で整理しておきます。このデザインにより、同じ話者のアイデンティティを維持しながら、異なるテキストや感情をA/Bテストするのが簡単です。
Comfyui IndexTTS2 ComfyUI ワークフローの主要ノード#
IndexTTS2Run (#12)#
これは、IndexTTS-2をラップし、サンプリング、ビームサーチ、感情条件付けのためのコントロールを公開するコアジェネレーターです。top_p、top_k、temperatureを調整して、安定性と多様性のバランスを取ります。値が低いとより一貫した読み取りが得られ、値が高いと自発性が増します。num_beamsを使用して、ノードがより多くの候補読み取りを検索する場合、速度と品質を交換します。長いスクリプトの場合、max_mel_tokensおよびmax_text_tokens_per_sentenceは、オーディオとテキストのチャンクサイズを制限することでオーバーランを防ぎます。感情はemo_audio_prompt、emo_alphaでミックスの強度を調整するか、テキストの手がかりが好ましい場合はuse_emo_textおよびemo_textで制御できます。deepspeed、custom_cuda_kernel、およびunload_modelなどのパフォーマンスヘルパーは、ハードウェアに応じて利用できます。ノードの実装はComfyUI IndexTTSカスタムノードによって提供されています: ComfyUI_IndexTTS、基礎となるモデルはここで文書化されています: IndexTTS-2, IndexTTSプロジェクト。
AudioCrop (#37) — 参照音色#
このノードを使用して、スピーカーサンプルからクリーンで安定した抜粋を分離します。バックグラウンドノイズ、笑い声、または極端な感情を避けてください。これらの詳細はクローンされた音声に漏れる可能性があります。一貫したトーンにクロップすることで、アイデンティティロックが改善され、不要なアーティファクトが減少します。
AudioCrop (#38) — 感情プロンプト#
このクロップは、デリバリーを制御する表現豊かな手がかりを選択します。望む正確なリズムや強度を持つ部分を選択し、信号を希釈しないように簡潔に保ちます。最良の一貫性を得るには、可能であれば音色参照と同じスピーカーからの感情プロンプトを使用します。
オプションの追加機能#
- 参照オーディオをドライかつモノフォニックに保ちます; リバーブ、バックグラウンドミュージック、重い圧縮を取り除いて、クリーンなクローンを作成します。
- 意図的に句読点をつけます。コンマ、ピリオド、疑問符は、モデルがあなたの意図に一致する休止と抑揚を配置するのに役立ちます。
- 再現可能なテイクのために、ノードでランダム性を無効にするか、テキストとオーディオの選択に関するメモを保持し、後で同じ出力を再生成できるようにします。
- VRAMが厳しい場合、実行間でのモデルのアンロードを有効にします。これにより、わずかな時間コストが発生する可能性がありますが、他のグラフのためにメモリを解放します。
- 声の権利を尊重します。クローンを生成する権限を持つ参照録音のみを使用し、必要に応じて合成音声を開示します。
謝辞#
このワークフローは、以下の作品とリソースを実装し、構築しています。ワークフローレファレンスのためのRunningHub、Cloud SaveワークフローのためのRunComfy、IndexTTSとIndexTTS-2のためのIndexTeam、IndexTTS2論文の著者、ComfyUI IndexTTSカスタムノードのためのbillwuhaoの貢献とメンテナンスに感謝します。権威ある詳細については、以下にリンクされた元のドキュメントとリポジトリを参照してください。
リソース#
- RunningHub/ワークフローレファレンス
- ドキュメント / リリースノート: RunningHub post
- RunComfy/Cloud Save ワークフロー
- ドキュメント / リリースノート: RunComfy workflow
- index-tts/index-tts
- GitHub: index-tts/index-tts
- IndexTeam/IndexTTS-2
- Hugging Face: IndexTeam/IndexTTS-2
- IndexTTS2/論文
- arXiv: 2506.21619
- billwuhao/ComfyUI_IndexTTS
- GitHub: billwuhao/ComfyUI_IndexTTS
注: 参照されたモデル、データセット、およびコードの使用は、それぞれの著者とメンテナンス提供者によって提供されたライセンスと条件に従います。
