
Wan2.2 VACE Fun: Reference Image to Animated Video in ComfyUI#
Wan2.2 VACE Fun is a creative, prompt-driven reference-to-video workflow for ComfyUI. Provide a single reference image and a text description, and the graph animates your subject into a coherent video while preserving identity and style. Built on the Wan 2.2 VACE module with a staged sampler, it balances motion, fidelity, and runtime, making it ideal for concept reels, character tests, and short storytelling clips.
This ComfyUI Wan2.2 VACE Fun workflow focuses on three things: strong subject adherence from the reference image, expressive motion guided by your prompt, and reliable export to an MP4 video. Use it when you need quick iterations that still feel cinematic, or when you want to turn a still image into a dynamic scene without complex keyframing.
Key models in Comfyui Wan2.2 VACE Fun workflow#
- Alibaba PAI Wan 2.2 VACE Fun A14B. The VACE module is the core that turns a reference image plus prompts into a video-ready latent sequence. It is designed for subject-driven animation and identity preservation. Model card
- Wan 2.2 Text-to-Video A14B (HIGH/LOW). The workflow uses HIGH and LOW variants in a staged denoising pipeline to trade speed and detail where each is most effective. Packaged weights compatible with ComfyUI are available here: Comfy-Org/Wan_2.2_ComfyUI_Repackaged
- UMT5-XXL text encoder. A large multilingual text encoder used by Wan 2.x for prompt understanding; it supports rich English and Chinese prompts. See the repackaged text encoders in Comfy-Org/Wan_2.2_ComfyUI_Repackaged
- Wan 2.1 VAE. Used to decode the final video latents into RGB frames before encoding. Available in the same repack: Comfy-Org/Wan_2.2_ComfyUI_Repackaged
How to use Comfyui Wan2.2 VACE Fun workflow#
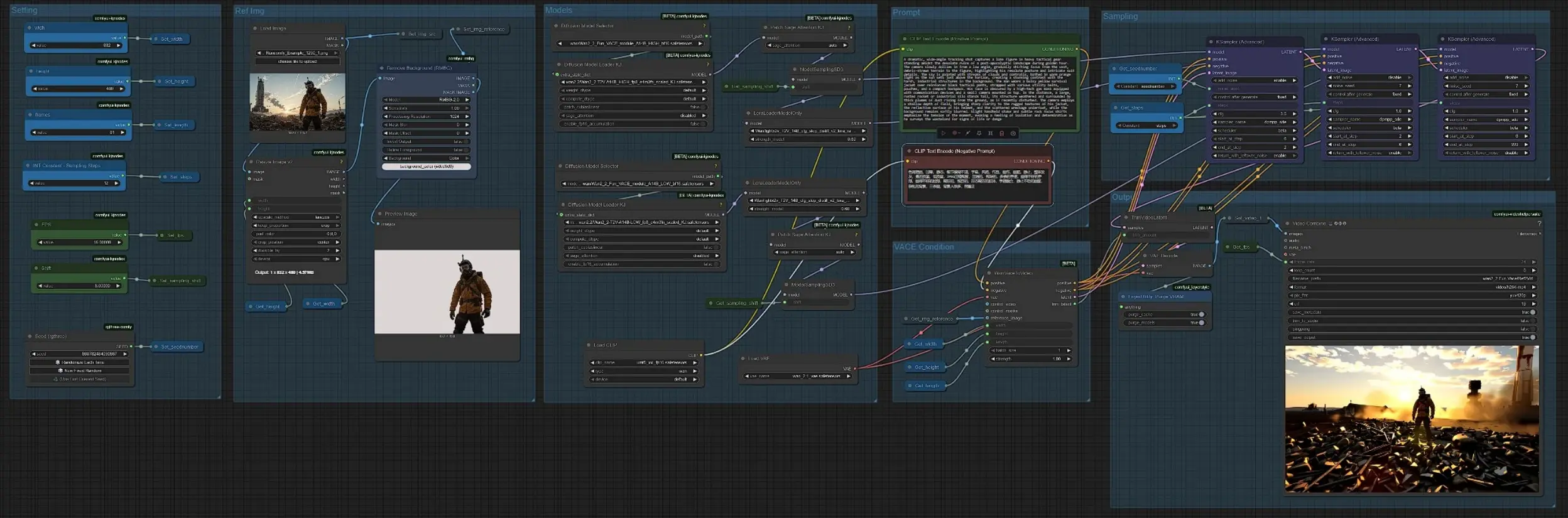
The workflow runs in stages: you set global controls, prepare the reference image, write prompts, generate a VACE-conditioned latent video, refine it through staged sampling, then decode and export. Groups are organized so you can work top to bottom with minimal friction.
Setting#
This group centralizes the controls the rest of the graph reads: width, height, length (frames), fps, steps, sampling_shift, and seed. Change these once and every downstream node picks up the values via SetNode/GetNode pairs. Resolution and length influence both quality and VRAM, while fps controls perceived motion in the final MP4. Keep width and height aspect-aligned to your reference image to avoid stretching. The seed is exposed for reproducibility across runs.
Ref Img#
Load your subject with LoadImage (#118), then the image is resized in ImageResizeKJv2 (#112) to match your target resolution. RMBG (#73) removes the background so VACE can lock onto the foreground subject more reliably, helping identity consistency across frames. A preview node lets you quickly inspect the cutout before generation. The processed image is stored as the reference and fed downstream.
Prompt#
Prompts are encoded with CLIP Text Encode (Positive Prompt) (#56) and CLIP Text Encode (Negative Prompt) (#54) using the UMT5-XXL encoder. Write clear action verbs, camera language, and scene context in the positive prompt to direct motion and composition. Use the negative prompt to suppress unwanted artifacts, styles, or clutter; multilingual phrasing works well. The outputs provide rich conditioning for the VACE step and the samplers that follow.
Models#
The graph loads Wan 2.2 T2V A14B weights and applies the Wan2.2 VACE Fun module, then augments attention and scheduling for stability. The HIGH branch passes through PathchSageAttentionKJ (#8) and ModelSamplingSD3 (#57), while the LOW branch uses LoraLoaderModelOnly (#61), PathchSageAttentionKJ (#66), and ModelSamplingSD3 (#20). This split gives you a detail-first early pass and a motion-focused refinement. All model choices are prewired; you simply run the graph once your settings and prompts are ready.
VACE Condition#
WanVaceToVideo (#43) injects your reference_image, positive/negative conditioning, and VAE, then generates an initial video latent sequence sized by width, height, and length. Think of this as the moment the still image “learns” to move according to your prompt. The node returns both conditioning streams for reuse and an integer for latent trimming to keep the pipeline frame-consistent. No manual mask or control video is required unless you want to experiment.
Sampling#
A three-stage sampler stack shapes the result. First pass KSamplerAdvanced (#108) seeds the latent sequence for overall composition and motion cues. Second pass KSamplerAdvanced (#107) deepens detail and temporal stability using the same conditioning while preserving the scene layout. Final pass KSamplerAdvanced (#109) runs on the LOW variant to polish motion and reduce artifacts, striking a practical balance between speed and quality. TrimVideoLatent (#65) aligns the frames to the target length before decoding.
Output#
VAEDecode (#19) turns the refined latents into RGB frames. VHS_VideoCombine (#69) then assembles those frames into an MP4 at your chosen fps, saving with a sensible filename pattern. This group is optimized for quick review loops, so you can iterate on prompts, length, or resolution without touching the rest of the graph. When satisfied, keep the same seed for repeatability or change it to explore variations.
Key nodes in Comfyui Wan2.2 VACE Fun workflow#
WanVaceToVideo (#43) The heart of Wan2.2 VACE Fun: it binds prompt semantics to your reference image and produces the initial video latents. Adjust width, height, and length here via the shared settings to match your creative target and VRAM budget. Keep the reference subject centered and well-lit for best identity retention. If motion feels off, revise the positive prompt to emphasize actions, camera moves, and timing words.
KSamplerAdvanced (#108, #107, #109) A staged sampler chain that progressively improves composition, detail, and motion smoothness. Increase steps when you need more detail or temporal stability, and reuse the same seed to compare changes fairly. The final pass on the LOW variant often cleans subtle artifacts; if results look too soft, shift some steps to the earlier passes. sampling_shift is exposed to nudge the schedule toward either motion emphasis or finer texture.
RMBG (#73) Automatic background removal improves subject adherence for Wan2.2 VACE Fun, especially with busy or low-contrast scenes. Use high-quality, non-blurry references to minimize cutout errors. If you want natural backgrounds, replace them later in post or composite a plate behind the decoded frames.
TrimVideoLatent (#65) Keeps the latent sequence aligned to the requested length. If you extend or shorten a clip, let this node handle the bookkeeping; it prevents subtle frame drift across the sampler stages.
VHS_VideoCombine (#69) Encodes the final frames to MP4. Tune frame_rate to control clip duration relative to length (duration equals frames divided by fps). Raise quality for final delivery or lower it for rapid previews; higher quality increases file size and encode time.
Optional extras#
- Start with a reference image whose aspect matches your target
widthandheightto avoid stretching and unwanted crops. - Write prompts that describe action and camera movement, not just appearance; Wan2.2 VACE Fun responds well to verbs like “walks,” “pans,” “dollies,” and “whip tilt.”
- Keep
lengthandfpsin sync with your goal: higher fps looks smoother but shortens total duration for the same frame count. - If identity wobbles, simplify the background via
RMBGand add a brief identity clause in the prompt (clothing, color, or gear). - For faster drafts, reduce resolution or steps, then restore them for finals; keep the same seed to compare versions reliably.
Acknowledgements#
This workflow implements and builds upon the following works and resources. We gratefully acknowledge @BenjisAIPlayground for the “Wan2.2 VACE Fun Demo” workflow and for their contributions and maintenance. For authoritative details, please refer to the original documentation and repositories linked below.
Resources#
- PWan2.2 VACE Fun Demo
- Docs / Release Notes @BenjisAIPlayground: YouTube
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.
