
Wan2.1 Stand In: single‑image, character‑consistent video generation for ComfyUI#
This workflow turns one reference image into a short video where the same face and style persist across frames. Powered by the Wan 2.1 family and a purpose‑built Stand In LoRA, it is designed for storytellers, animators, and avatar creators who need stable identity with minimal setup. The Wan2.1 Stand In pipeline handles background cleanup, cropping, masking, and embedding so you can focus on your prompt and motion.
Use the Wan2.1 Stand In workflow when you want reliable identity continuity from a single photo, fast iteration, and export‑ready MP4s plus an optional side‑by‑side comparison output.
Key models in Comfyui Wan2.1 Stand In workflow#
- Wan 2.1 Text‑to‑Video 14B. The primary generator responsible for temporal coherence and motion. It supports 480p and 720p generation and integrates with LoRAs for targeted behaviors and styles. Model card
- Wan‑VAE for Wan 2.1. A high‑efficiency spatiotemporal VAE that encodes and decodes video latents while preserving motion cues. It underpins the image encode/decode stages in this workflow. See the Wan 2.1 model resources and Diffusers integration notes for VAE usage. Model hub • Diffusers docs
- Stand In LoRA for Wan 2.1. A character‑consistency adapter trained to lock identity from a single image; in this graph it is applied at model load to ensure the identity signal is fused at the foundation. Files
- LightX2V Step‑Distill LoRA (optional). A lightweight adapter that can improve guidance behavior and efficiency with Wan 2.1 14B. Model card
- VACE module for Wan 2.1 (optional). Enables motion and editing control via video‑aware conditioning. The workflow includes an embed path you can enable for VACE control. Model hub
- UMT5‑XXL text encoder. Provides robust multilingual prompt encoding for Wan 2.1 text‑to‑video. Model card
How to use Comfyui Wan2.1 Stand In workflow#
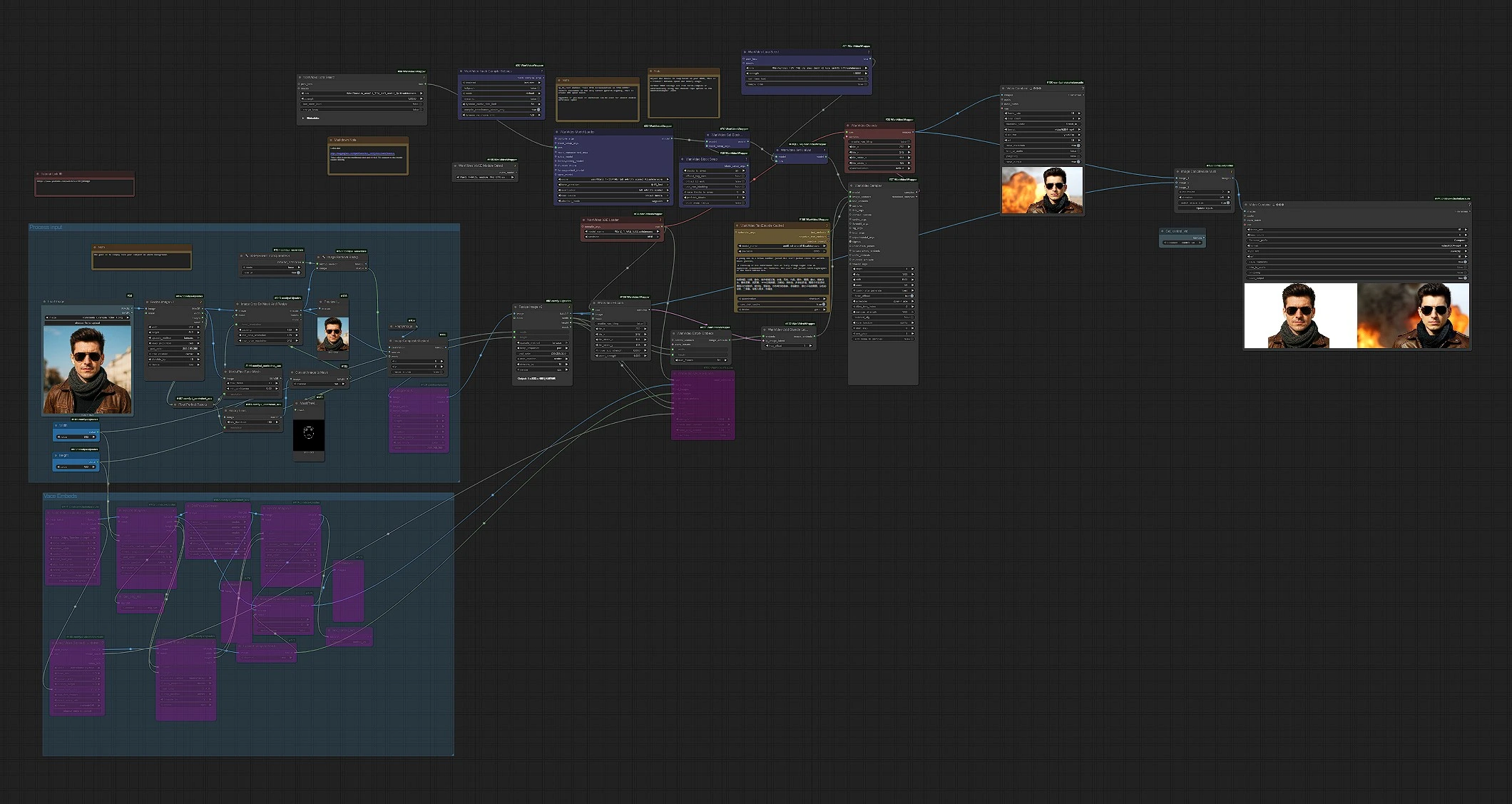
At a glance: load a clean, front‑facing reference image, the workflow prepares a face‑focused mask and composite, encodes it to a latent, merges that identity into Wan 2.1 image embeds, then samples video frames and exports MP4. Two outputs are saved: the main render and a side‑by‑side comparison.
Process input (group)#
Start with a well‑lit, forward‑facing image on a plain background. The pipeline loads your image in LoadImage (#58), standardizes size with ImageResizeKJv2 (#142), and creates a face‑centric mask using MediaPipe-FaceMeshPreprocessor (#144) and BinaryPreprocessor (#151). Background is removed in TransparentBGSession+ (#127) and ImageRemoveBackground+ (#128), then the subject is composited over a clean canvas with ImageCompositeMasked (#108) to minimize color bleeding. Finally, ImagePadKJ (#129) and ImageResizeKJv2 (#68) align the aspect for generation; the prepared frame is encoded to a latent via WanVideoEncode (#104).
VACE Embeds (optional group)#
If you want motion control from an existing clip, load it with VHS_LoadVideo (#161) and optionally a secondary guide or alpha video with VHS_LoadVideo (#168). The frames pass through DWPreprocessor (#163) for pose cues and ImageResizeKJv2 (#169) for shape matching; ImageToMask (#171) and ImageCompositeMasked (#174) let you blend control imagery precisely. WanVideoVACEEncode (#160) turns these into VACE embeddings. This path is optional; leave it untouched when you want text‑driven motion from Wan 2.1 alone.
Model, LoRAs, and text#
WanVideoModelLoader (#22) loads the Wan 2.1 14B base plus the Stand In LoRA so identity is baked in from the start. VRAM‑friendly speed features are available through WanVideoBlockSwap (#39) and applied with WanVideoSetBlockSwap (#70). You can attach an extra adapter such as LightX2V via WanVideoSetLoRAs (#79). Prompts are encoded with WanVideoTextEncodeCached (#159), using UMT5‑XXL under the hood for multilingual control. Keep prompts concise and descriptive; emphasize the subject’s clothing, angle, and lighting to complement the Stand In identity.
Identity embedding and sampling#
WanVideoEmptyEmbeds (#177) establishes the target shape for image embeddings, and WanVideoAddStandInLatent (#102) injects your encoded reference latent to carry identity through time. The combined image and text embeddings feed into WanVideoSampler (#27), which generates a latent video sequence using the configured scheduler and steps. After sampling, frames are decoded with WanVideoDecode (#28) and written to an MP4 in VHS_VideoCombine (#180).
Compare view and export#
For instant QA, ImageConcatMulti (#122) stacks the generated frames beside the resized reference so you can judge likeness frame by frame. VHS_VideoCombine (#74) saves that as a separate “Compare” MP4. The Wan2.1 Stand In workflow therefore produces a clean final video plus a side‑by‑side check without extra effort.
Key nodes in Comfyui Wan2.1 Stand In workflow#
WanVideoModelLoader(#22). Loads Wan 2.1 14B and applies the Stand In LoRA at model initialization. Keep the Stand In adapter connected here rather than later in the graph so identity is enforced throughout the denoising path. Pair withWanVideoVAELoader(#38) for the matching Wan‑VAE.WanVideoAddStandInLatent(#102). Fuses your encoded reference image latent into the image embeddings. If identity drifts, increase its influence; if motion seems overly constrained, reduce it slightly.WanVideoSampler(#27). The main generator. Tuning steps, scheduler choice, and guidance strategy here has the largest impact on detail, motion richness, and temporal stability. When pushing resolution or length, consider adjusting sampler settings before changing anything upstream.WanVideoSetBlockSwap(#70) withWanVideoBlockSwap(#39). Trades GPU memory for speed by swapping attention blocks between devices. If you see out‑of‑memory errors, increase offloading; if you have headroom, reduce offloading for faster iteration.ImageRemoveBackground+(#128) andImageCompositeMasked(#108). These ensure the subject is cleanly isolated and placed on a neutral canvas, which reduces color contamination and improves the Stand In identity lock across frames.VHS_VideoCombine(#180). Controls encoding, frame rate, and file naming for the main MP4 output. Use it to set your preferred FPS and quality target for delivery.
Optional extras#
- Use a front‑facing, evenly lit reference on a plain background for best results. Small rotations or heavy occlusions can weaken identity transfer.
- Keep prompts concise; describe clothing, mood, and lighting that match your reference. Avoid conflicting face descriptors that fight the Wan2.1 Stand In signal.
- If VRAM is tight, increase block swapping or lower resolution first. If you have headroom, try enabling compile optimizations in the loader stack before increasing steps.
- The Stand In LoRA is nonstandard and must be connected at model load; follow the pattern in this graph to keep identity stable. LoRA files: Stand‑In
- For advanced control, enable the VACE path to steer motion with a guide clip. Start without it if you want purely text‑driven movement from Wan 2.1.
Resources
- Wan 2.1 14B T2V: Hugging Face
- Wan 2.1 VACE: Hugging Face
- Stand In LoRA: Hugging Face
- LightX2V Step‑Distill LoRA: Hugging Face
- UMT5‑XXL encoder: Hugging Face
- WanVideo wrapper nodes: GitHub
- KJNodes utilities used for resizing, padding, and masking: GitHub
- ControlNet Aux preprocessors (MediaPipe Face Mesh, DWPose): GitHub
Acknowledgements#
This workflow implements and builds upon ArtOfficial Labs works and resources. We gratefully acknowledge ArtOfficial Labs and Wan 2.1 authors for Wan2.1 Demo for their contributions and maintenance. For authoritative details, please refer to the original documentation and repositories linked below.
Resources#
- Wan 2.1/Wan2.1 Demo
- Docs / Release Notes: Wan2.1 Demo
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.


