
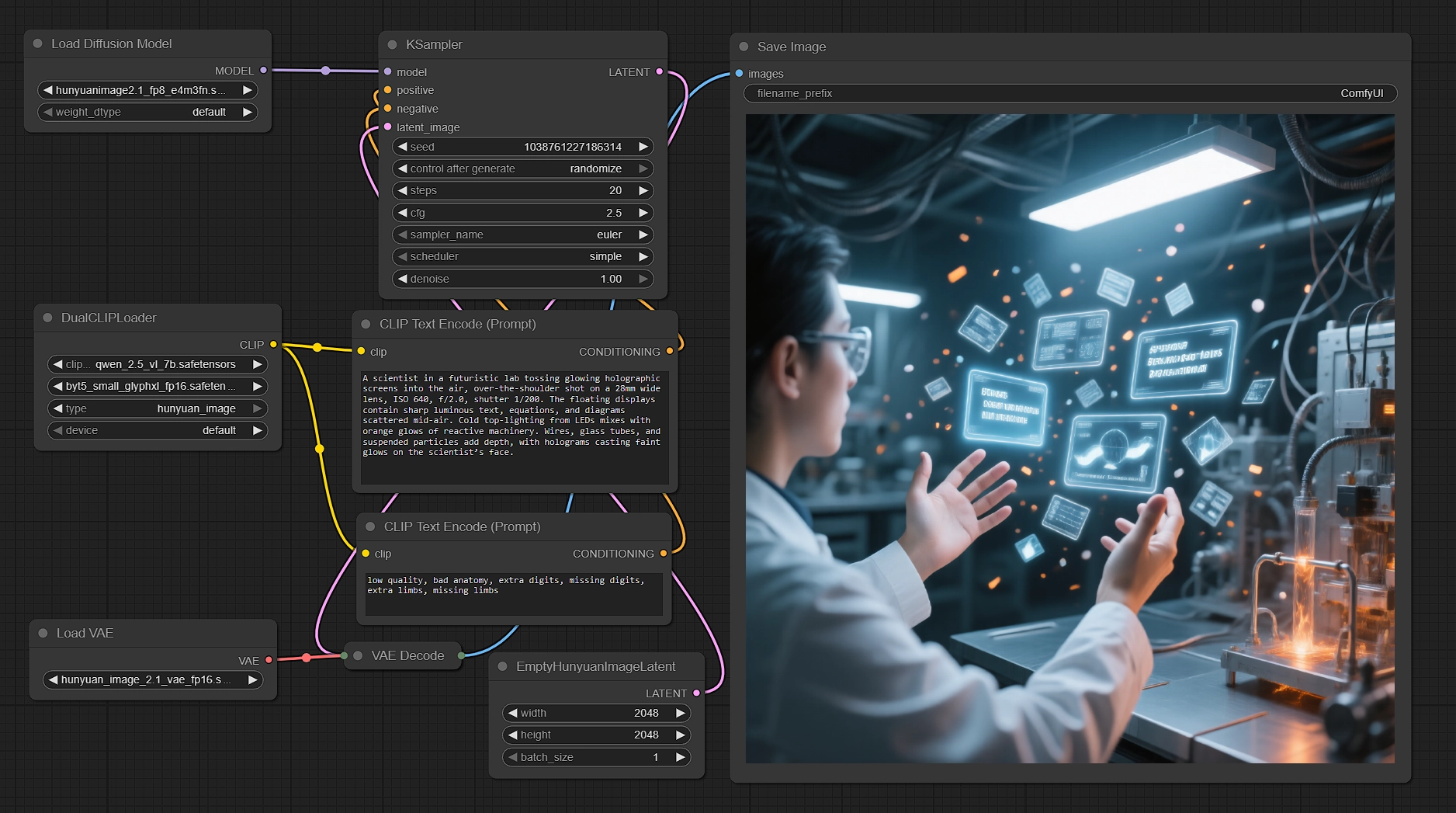










ComfyUIでHunyuan Image 2.1を使用してネイティブ2K画像を生成#
このワークフローは、Hunyuan Image 2.1を使用してプロンプトを鮮明なネイティブ2048×2048レンダーに変えます。Tencentの拡散トランスフォーマーをデュアルテキストエンコーダーと組み合わせてセマンティックアライメントとテキストレンダリング品質を向上させ、その後、対応する高圧縮VAEを通じて効率的にサンプリングしてデコードします。2Kで生産準備の整ったシーン、キャラクター、そして画像内の明確なテキストが必要で、スピードとコントロールを維持したい場合、このComfyUI Hunyuan Image 2.1ワークフローはあなたのために構築されています。
クリエイター、アートディレクター、およびテクニカルアーティストは、多言語プロンプトを入力し、いくつかのノブを微調整して、一貫してシャープな結果を得ることができます。グラフには、適切なネガティブプロンプト、ネイティブ2Kキャンバス、およびVRAMを制御するためのFP8 UNetが付属しており、Hunyuan Image 2.1の即時の成果を示しています。
Comfyui Hunyuan Image 2.1ワークフローの主なモデル#
- HunyuanImage‑2.1 by Tencent。拡散トランスフォーマーバックボーン、デュアルテキストエンコーダー、32× VAE、RLHFポストトレーニング、および効率的なサンプリングのためのmeanflow distillationを備えた基本的なテキストから画像へのモデル。リンク: Hugging Face · GitHub
- Qwen2.5‑VL‑7B‑Instruct。ここで使用されるマルチモーダルビジョン‑ランゲージエンコーダーとして、複雑なシーンと言語間のプロンプト理解を改善するために使用されます。リンク: Hugging Face
- ByT5 Small。画像内のテキストレンダリングのために文字とグリフの処理を強化するトークナイザー不要のバイトレベルエンコーダー。リンク: Hugging Face · Paper
Comfyui Hunyuan Image 2.1ワークフローの使用方法#
グラフはプロンプトからピクセルまでの明確なパスをたどります: テキストを2つのエンコーダーでエンコードし、ネイティブ2Kの潜在キャンバスを準備し、Hunyuan Image 2.1でサンプリングし、対応するVAEを通じてデコードし、出力を保存します。
デュアルエンコーダーによるテキストエンコーディング#
DualCLIPLoader(#33)はHunyuan Image 2.1用に構成されたQwen2.5‑VL‑7BとByT5 Smallをロードします。このデュアルセットアップにより、モデルはシーンのセマンティクスを解析しつつ、グリフと多言語テキストに対して堅牢であり続けます。CLIPTextEncode(#6)にメインの説明を入力します。英語または中国語で書くことができ、カメラヒントと照明を組み合わせ、画像内のテキスト指示を含めることができます。CLIPTextEncode(#7)にあるすぐに使えるネガティブプロンプトは、一般的なアーティファクトを抑制します。スタイルに合わせて適応させたり、バランスのとれた結果を得るためにそのまま残したりできます。
ネイティブ2Kでの潜在キャンバス#
EmptyHunyuanImageLatent(#29)は2048×2048でキャンバスを単一バッチで初期化します。Hunyuan Image 2.1は2K生成用に設計されているため、最高の品質を得るためにはネイティブ2Kサイズが推奨されます。- 必要に応じて幅と高さを調整し、Hunyuanがサポートするアスペクト比を維持します。代替の比率については、アーティファクトを避けるためにモデルに適した寸法を守ってください。
Hunyuan Image 2.1での効率的なサンプリング#
UNETLoader(#37)はFP8チェックポイントをロードしてVRAMを削減しつつ忠実度を維持し、その後KSampler(#3)にフィードしてデノイズします。- エンコーダーからのポジティブおよびネガティブ条件付けを使用して構成と明確さを導きます。バラエティのためにシードを調整し、クオリティ対速度のためにステップを調整し、プロンプトの遵守のためにガイダンスを調整します。
- ワークフローはベースモデルパスに焦点を当てています。Hunyuan Image 2.1はリファイナーステージもサポートしており、追加の磨きをかけたい場合は後で追加することができます。
デコードと保存#
VAELoader(#34)がHunyuan Image 2.1 VAEを導入し、VAEDecode(#8)がモデルの32×圧縮スキームでサンプリングされた潜在画像から最終画像を再構築します。SaveImage(#9)は出力を選択したディレクトリに書き込みます。シードやプロンプトを通して反復する予定がある場合は、明確なファイル名プレフィックスを設定してください。
Comfyui Hunyuan Image 2.1ワークフローのキーノード#
DualCLIPLoader (#33)#
このノードはHunyuan Image 2.1が期待する一対のテキストエンコーダーをロードします。モデルタイプをHunyuanに設定し、Qwen2.5‑VL‑7BとByT5 Smallを選択して、強力なシーン理解とグリフ対応のテキスト処理を組み合わせます。スタイルを反復する場合は、エンコーダーを交換するのではなく、ガイダンスとともにポジティブプロンプトを調整してください。
CLIPTextEncode (#6 and #7)#
これらのノードは、ポジティブおよびネガティブプロンプトを条件付けに変換します。ポジティブプロンプトは上部に簡潔に保ち、レンズ、照明、スタイルのヒントを追加します。ネガティブプロンプトを使用して、余分な肢やノイズのあるテキストなどのアーティファクトを抑制します。コンセプトに対して制限が厳しすぎると感じた場合は、削減してください。
EmptyHunyuanImageLatent (#29)#
作業解像度とバッチを定義します。デフォルトの2048×2048はHunyuan Image 2.1のネイティブ2K能力に一致します。他のアスペクト比の場合、モデルに適した幅と高さのペアを選択し、正方形から遠く離れる場合はステップを少し増やすことを検討してください。
KSampler (#3)#
Hunyuan Image 2.1でデノイズプロセスを推進します。微細なマイクロディテールが必要な場合はステップを増やし、クイックドラフトの場合は減らします。プロンプトの遵守を強化するためにガイダンスを上げますが、過度の飽和や硬直性に注意してください。より自然なバリエーションのために下げます。プロンプトを変更せずに構成を探索するためにシードを切り替えます。
UNETLoader (#37)#
Hunyuan Image 2.1 UNetをロードします。含まれているFP8チェックポイントは、2K出力のためにメモリ使用量を控えめに保ちます。十分なVRAMがあり、積極的な設定のための最大の余地を望む場合、公式リリースから同じモデルの高精度バリアントを検討してください。
VAELoader (#34)とVAEDecode (#8)#
これらのノードは、正しくデコードするためにHunyuan Image 2.1リリースに一致する必要があります。モデルの高圧縮VAEは、迅速な2K生成の鍵であり、正しいVAEをペアリングすることで、色のずれやブロック状のテクスチャを避けることができます。ベースモデルを変更する場合は、常にVAEを適切に更新してください。
オプションの追加#
- プロンプト
- Hunyuan Image 2.1は構造化されたプロンプトにうまく対応します: 主題、アクション、環境、カメラ、照明、スタイル。画像内のテキストの場合、正確な言葉を引用して短く保ちます。
- スピードとメモリ
- FP8 UNetは既に効率的です。さらに圧縮する必要がある場合、大きなバッチを無効にし、ステップを減らすことをお勧めします。オプションのGGUFローダーノードはグラフに存在しますが、デフォルトでは無効になっています。高度なユーザーは、量子化されたチェックポイントを使用して実験する際にそれらを交換できます。
- アスペクト比
- ベストな結果を得るためにネイティブ2K対応のサイズに固執してください。広いまたは高い形式に移行する場合は、クリーンなレンダーを確認し、ステップを少し増やすことを検討してください。
- 洗練
- Hunyuan Image 2.1はリファイナーステージをサポートしています。試してみるには、ベースパスの後にリファイナーチェックポイントと軽いデノイズを使用して構造を保持しつつマイクロディテールを強化するために2番目のサンプラーを追加します。
- 参考文献
- Hunyuan Image 2.1モデルの詳細とダウンロード: Hugging Face · GitHub
- Qwen2.5‑VL‑7B‑Instruct: Hugging Face
- ByT5 Smallと論文: Hugging Face · Paper
謝辞#
このワークフローは以下の作品とリソースを実装し、構築しています。我々はHunyuan Image 2.1 Demoの貢献とメンテナンスにおいて@Ai VerseとHunyuanに感謝しています。権威ある詳細については、以下にリンクされた元のドキュメントとリポジトリを参照してください。
リソース#
- Hunyuan/Hunyuan Image 2.1 Demo
- ドキュメント/リリースノート: Hunyuan Image 2.1 Demo tutorial from @Ai Verse
注意: 参照されたモデル、データセット、およびコードの使用は、それぞれの著者および管理者によって提供されるライセンスおよび条件に従います。

